

What is shift left in cloud security?
Shift left means moving security checks earlier in the software development lifecycle (SDLC). Instead of testing right before deployment, you catch issues while developers write application code and define infrastructure as code (IaC) templates.This includes scanning Terraform configurations, Kubernetes manifests, and CI/CD pipeline definitions before any resources reach production.
This approach works by embedding security directly into your CI/CD pipeline. Your team scans infrastructure as code templates, checks for exposed secrets in repositories, and tests container images for vulnerabilities before anything reaches production. When you find issues early, they're cheaper and faster to fix.
Development teams get instant feedback through tools they already use. If a developer accidentally commits a secret (API key, password, token) to a version control system (GitHub, GitLab, Bitbucket), they see an alert in their pull request immediately. The secret scanner flags the exposure before code merges, allowing the developer to rotate credentials and remove the secret from git history.
Organizations in the travel and e-commerce sectors integrate security scans into their CI/CD pipelines. Developers validate IaC configurations before deployment, preventing misconfigurations from reaching production. This approach reduces mean time to remediation (MTTR) by 60–80% compared to post-deployment fixes.
State of SDLC Security 2026 Report
See how leading organizations are embedding security across the development lifecycle.

What is shift right in cloud security?
Shift right focuses on security after your applications go live. You monitor production environments continuously, detect threats in real time, and respond to attacks as they happen.
This approach recognizes a simple truth: you can't catch everything before deployment. Production environments reveal threats that only appear with real users, actual data, and live traffic patterns. Some vulnerabilities only show up under these conditions.
Your security team monitors active threats using cloud audit logs (CloudTrail, Azure Activity Log, GCP Cloud Audit Logs), identity signals (IAM changes, privilege escalations), and runtime telemetry (process execution, network connections, file modifications). This detects privilege escalation attempts, unusual API access patterns, and configuration drift that creates new attack paths.
Global automotive manufacturers use runtime visibility to spot and fix security issues in production cloud environments. Continuous monitoring detects threats like privilege escalation attempts, lateral movement, and zero-day exploitation—catching problems that pre-deployment scans miss.This approach reduces mean time to detection (MTTD) from days to minutes.
Shift left vs shift right: key differences and use cases
The main difference between these approaches is timing. Shift left happens before deployment and focuses on prevention. Shift right happens after deployment and focuses on detection and response.
Here's how they compare across key dimensions:
| Dimension | Shift Left | Shift Right |
|---|---|---|
| Timing | Before deployment (development and build stages) | After deployment (production runtime) |
| Primary focus | Prevention | Detection and response |
| Risks addressed | Known vulnerabilities in dependencies, misconfigurations in infrastructure code, hardcoded secrets in repositories, insecure coding patterns | Zero-day exploits, behavioral anomalies, configuration drift in production, actual attack attempts |
| Team ownership | Developers and DevOps engineers (control code and build process) | Security operations and incident response teams (monitor production and respond to threats) |
| Common tools | Static application security testing (SAST), software composition analysis (SCA) with SBOM generation, IaC validators (Checkov, tfsec), policy-as-code engines (Open Policy Agent/Rego, Kyverno) | Cloud workload protection platforms (CWPP), cloud detection and response (CDR) for cloud-native signals, SIEM/SOAR platforms (Splunk, Sentinel, Chronicle) for centralized logging and automated playbooks |
| Example scenario | Scan a Terraform template and find that it creates a publicly accessible S3 bucket. Fix this before deploying anything. | Detect that someone is trying to escalate privileges on a running container and block them immediately. |
Each approach handles different types of risksand requires different expertise. The most effective security programs use both strategies together rather than choosing one over the other.
When to prioritize shift left vs. shift right
The right balance depends on your current maturity and immediate risks. Use this decision framework:
Prioritize shift left when:
Building new services or migrating to cloud (establish secure foundations)
High developer velocity with frequent deployments (prevent issues at scale)
Compliance mandates require secure development practices (SOC 2, ISO 27001)
Remediation costs are high (regulated industries, complex rollback procedures)
Prioritize shift right when:
Responding to active incidents (contain threats immediately)
Legacy systems with limited code access (monitor what you can't rebuild)
Zero-day vulnerabilities emerge (detect exploitation before patches exist)
Rapid hotfixes bypass normal pipelines (monitor production for drift)
Balanced approach for:
Mature DevSecOps programs (integrate both seamlessly)
Multi-cloud environments (unified visibility across all stages)
Regulated industries (prevention + audit evidence)
High-value targets (defense in depth across lifecycle)
Most organizations start shift-left-heavy to reduce technical debt, then layer in shift-right detection as production complexity grows.
Benefits of implementing both shift left and shift right strategies
Using only one approach leaves gaps in your security. You need both to protect your applications throughout their entire lifecycle.Here's what you gain:
Complete security coverage: Prevention controls in development catch most issues before deployment. Detection controls in production catch the rest. Nothing falls through the cracks.
Continuous feedback loop: When your runtime monitoring detects a new attack pattern, you can create a policy to scan for that vulnerability in code. This prevents the same issue from happening again. When your code scans find a common mistake, you can watch for exploitation attempts in production.
Watch 5-min demo
See how Wiz Code creates a continuous feedback loop from code to cloud.

*
Faster root cause remediation:
When you detect a threat in production—like an exposed database or privilege escalation—you trace it back to the source: the application code, IaC template (Terraform, CloudFormation), or CI/CD configuration that introduced the risk. You fix the root cause in the repository, preventing the issue from reappearing in future deployments.
Context-aware prioritization: By correlating misconfigurations, vulnerabilities, identities, network exposure, and data sensitivity, you eliminate alert fatigue and prioritize real attack paths over isolated findings. Instead of treating every vulnerability equally, graph-based platforms show which vulnerabilities are actually exploitable—for example, a critical CVE in an internet-exposed container with admin privileges to production databases ranks higher than the same CVE in an isolated dev environment. This context-aware prioritization reduces noise by 80–90%, letting teams focus on risks that matter.
Better team collaboration: Developers, operations, and security all use the same tools and share the same understanding of risk. They collaborate instead of pointing fingers when problems arise.
Lower costs: Finding vulnerabilities during development costs much less than fixing them in production. At the same time, good runtime monitoring prevents expensive breaches. Organizations in pharmaceutical research and life sciences have reduced critical vulnerabilities by 95%+ by combining both approaches with unified visibility. This integrated model correlates code-level risks with production exposure, enabling teams to prioritize fixes based on actual attack path severity rather than CVSS scores alone.
How to measure success with shift left and shift right
Track these KPIs to demonstrate ROI and improve your security program:
Shift left metrics:
Vulnerability escape rate: Percentage of vulnerabilities reaching production (target: <5%)
False positive rate: Percentage of findings that aren't exploitable (target: <20%)
Mean time to fix (MTTF): Days from detection to remediation in pre-production (target: <3 days)
Pipeline gate effectiveness: Percentage of builds blocked for policy violations (track trend)
Developer remediation rate: Percentage of findings fixed by developers vs. security team (target: >80%)
Shift right metrics:
Mean time to detection (MTTD): Minutes from exploit to alert (target: <15 minutes)
Mean time to respond (MTTR): Minutes from alert to containment (target: <30 minutes)
Configuration drift rate: Percentage of resources deviating from baseline (target: <10%)
Critical vulnerabilities in production: Count of CVSS 9.0+ with public exploits (target: 0)
Attack path coverage: Percentage of critical paths monitored (target: 100%)
Combined program metrics:
Change failure rate: Percentage of deployments causing incidents (target: <5%)
Security debt reduction: Quarterly decrease in total vulnerability count (track trend)
Cost per vulnerability: Total security spend divided by vulnerabilities prevented/detected
Audit readiness: Days to compile compliance evidence (target: <1 day)
Challenges in balancing shift left and shift right approaches
Implementing both strategies creates new problems you need to solve:
Tool overload: Most organizations use separate tools for development security and production security. These tools don't talk to each other, which creates blind spots. Your security team wastes time manually connecting information from different systems to understand what's actually happening.
Alert fatigue: Without proper context, you get flooded with notifications from both pre-production scans and runtime monitoring. Industry surveys show that security and development teams report overwhelm from vulnerability volume, with most alerts turning out to be false positives or low-priority issues. Your team burns out trying to investigate everything without clear prioritization.
Policy drift: Pre-production scans often check different standards than production monitoring. The solution is a unified policy engine that standardizes security rules once and enforces them across IDE, pull requests, CI/CD pipelines, cloud infrastructure, and runtime workloads. For example, define 'no public S3 buckets' once, and the platform enforces it when developers write Terraform, when CI/CD deploys infrastructure, and when monitoring detects configuration drift in production.
Budget constraints: Limited resources force difficult choices between preventing vulnerabilities and detecting active threats. This creates a false choice because you need both. Budget limitations make it hard to do everything well.
Skills gap: Developers must learn security fundamentals to shift left effectively. Security teams must become experts in cloud-native technologies to shift right successfully. This skills gap takes time and training to close.
Development friction: Security checks can slow down development if you implement them poorly. Developers get frustrated when scans take too long or block their deployments with irrelevant findings. You need automated, context-aware guardrails that don't create bottlenecks.
Lack of correlation: A vulnerability in a code repository is just a data point. To understand its real risk, you need to know if that code runs in production, if it's exposed to the internet, and if it can access sensitive data. Siloed tools make this correlation nearly impossible.
Tools and technologies that enable shift left and shift right security
Modern security platforms solve these challenges by providing capabilities across the entire lifecycle. These tools give you unified visibility and consistent policies from code to cloud.
Shift left tools work in your development environment:
Infrastructure as code scanners analyze Terraform and CloudFormation templates to find misconfigurations before you create any infrastructure
Container image scanners inspect images for known vulnerabilities in operating system packages and application dependencies
Secrets scanners search code repositories and configuration files for hardcoded credentials like API keys and passwords
Static application security testing tools analyze source code to identify security flaws without running the application
Software composition analysis (SCA) tools scan dependencies for known vulnerabilities (CVEs) and license compliance issues, generating a software bill of materials (SBOM) that inventories all components. SCA tools analyze reachability—determining if vulnerable code paths are actually used—to reduce false positives. Examples include Snyk, Dependabot, and Mend (formerly WhiteSource).
Policy-as-code engines(Open Policy Agent with Rego, Kyverno, Sentinel) let you define security rules in code and automatically enforce them in CI/CD. For example, you can write a policy that blocks any Terraform plan creating an S3 bucket without encryption, or prevents Kubernetes deployments running as root. These policies gate your pipeline, failing builds that violate standards before infrastructure deploys.
Shift right tools work in your production environment:
Cloud workload protection platforms provide runtime security for VMs, containers, and serverless functions using eBPF-based telemetry, process monitoring, file integrity monitoring (FIM), and behavioral detections. These platforms detect threats like cryptominers, reverse shells, privilege escalations, and suspicious network connections by analyzing process execution, system calls, and network traffic in real time.
Cloud security posture management tools continuously scan your cloud for misconfigurations and compliance violations
Cloud detection and response (CDR)platforms specialize in cloud-native threats by analyzing cloud audit logs, identity signals, and runtime telemetry. Unlike traditional XDR (which focuses on endpoints and networks), CDR understands cloud-specific attack patterns: privilege escalation through IAM, lateral movement via cloud APIs, data exfiltration through storage services, and cryptomining in serverless functions. CDR correlates signals across AWS, Azure, GCP, and Kubernetes to detect multi-stage attacks.
Cloud-native application protection platforms integrate both shift left and shift right capabilities into a single unified platform
The most effective platforms connect shift left and shift right through code-to-cloud correlation. This means tracing findings bidirectionally across the entire lifecycle. When runtime monitoring detects a threat—like an exposed database or privilege escalation—the platform links it back to the exact repository, IaC template, and CI/CD pipeline that introduced the risk. You can then fix the vulnerable code or misconfigured templateat its source, preventing the issue from reappearing in future deployments. Look for platforms that maintain this traceability through a Security Graph that connects every resource, configuration, identity, and vulnerabilityacross your environment.
How Wiz unifies shift left and shift right for comprehensive cloud security
The shift left versus shift right debate misses the point. You need both, and they need to work together seamlessly.
Wiz is a cloud-native application protection platform (CNAPP) that unifies shift left and shift right security in a single solution. Instead of juggling separate tools for code scanning, cloud posture management, and runtime protection, you get one platform that covers your entire software lifecycle—from the first line of code to production workloads.
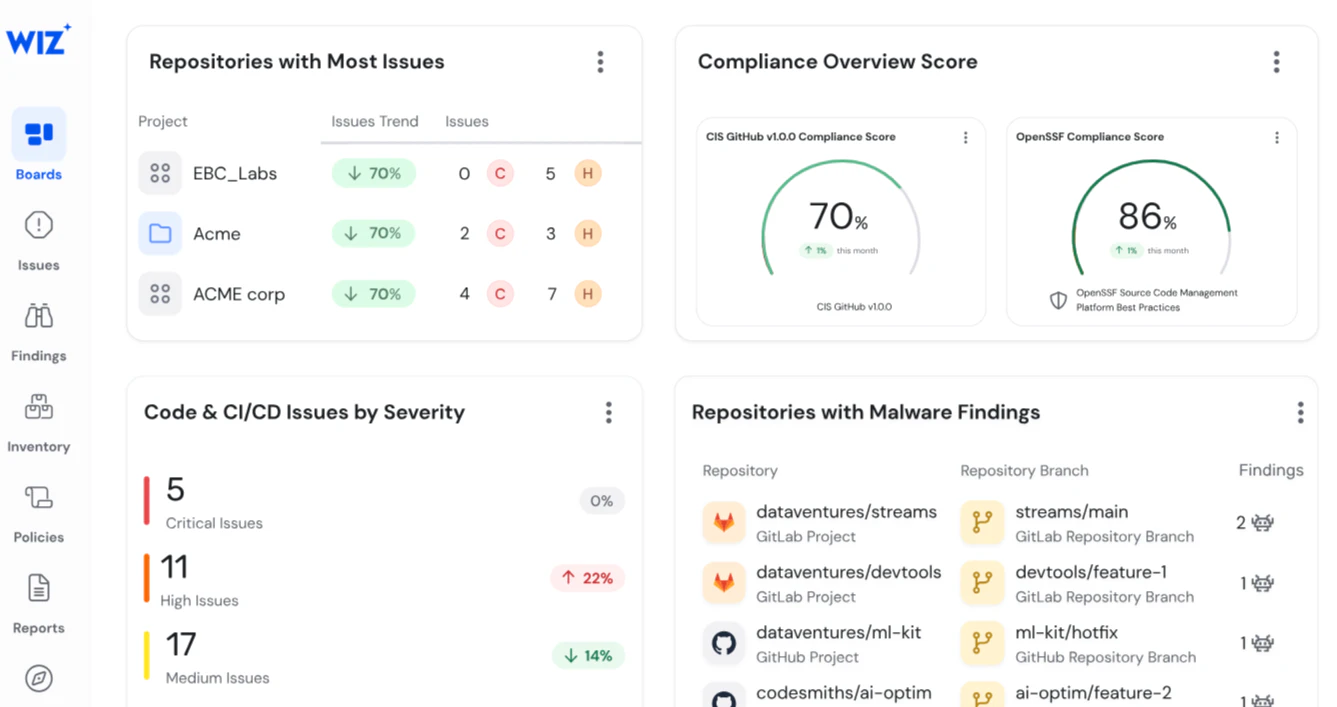
The foundation is the Security Graph, which maps every resource, configuration, identity, vulnerability, network path, and data asset across your environment. This creates bidirectional traceability—linking runtime threats back to their source in code and showing production blast radius. When a vulnerability is detected in a repository, the graph shows which production workloads are affected, whether they're internet-exposed, what data they can access, and which identities have permissions—enabling risk-based prioritization instead of CVSS-only scoring.
Wiz Code (shift left prevention):
Scans IaC templates, application dependencies, secrets, and CI/CD configurations before deployment
Prioritizes findings based on production exploitability using Security Graph context
Auto-generates pull requests with remediation guidance and code examples
Reduces alert noise by 70–80% compared to generic scanners
Wiz Cloud (continuous posture management):
Agentless monitoring for misconfigurations, excessive permissions, and public exposure
Attack path modeling that shows how attackers could move through your environment
Identifies toxic combinations connecting vulnerabilities to sensitive data
Prioritizes the 2–5% of findings that represent real business risk
Wiz Defend (shift right threat detection):
Real-time runtime telemetry (process execution, network connections, file access)
Automated investigation workflows correlating events across the Security Graph
Targeted containment actions (process termination, network isolation)
Full context linking runtime behavior to vulnerable code and blast radius
A unified policy engine eliminates tool sprawl by enforcing consistent security standards across code repositories, CI/CD pipelines, cloud infrastructure, and runtime workloads. You define policies once—like 'no public S3 buckets' or 'containers must not run as root'—and enforce them at every stage, from IaC validation to production monitoring. Your teams use one platform, one set of policies, and one view of risk. This makes it possible to move fast while staying secure. Ready to see unified code-to-cloud security in action? Get a demo to experience agentless visibility, graph-based attack path analysis, and bidirectional traceability linking production threats to source code—all in one platform.
Unify shift left and shift right in one platform
Replace tool sprawl with a single CNAPP that connects code scanning, posture management, and runtime protection through a shared Security Graph.
