




In the ever-evolving realm of modern application development, the need for greater levels of abstraction has become increasingly apparent. The prevailing shift toward containerized applications and microservices signifies a departure from traditional monolithic approaches. Within this landscape, Kubernetes has emerged as the primary orchestrator for managing cloud-native applications, embodying the industry's de facto standard. However, as the development focus sharpens on agility, scalability, and efficiency, a noteworthy consideration arises: the complexities associated with kernel-dependent solutions clash with the streamlined nature of contemporary cloud native principles. Navigating this intricate junction of technologies urges us to understand the challenges introduced by kernel modules, and to explore alternative avenues that harmonize more seamlessly with the ethos of cloud-native architecture.
In this series of blog posts, we'll introduce eBPF and its concepts, and then delve into real-life use cases.
kernel module: the challenges inherent with new development methods
Kernel modules are executable code that can be installed in the Linux operating system's kernel to enhance its functionality.
Let's take a closer look at the overall architecture. At the bottom, we have our hardware. On top of that is the Linux kernel, which is the core of the operating system and has unrestricted access to all hardware, including the CPU and memory.
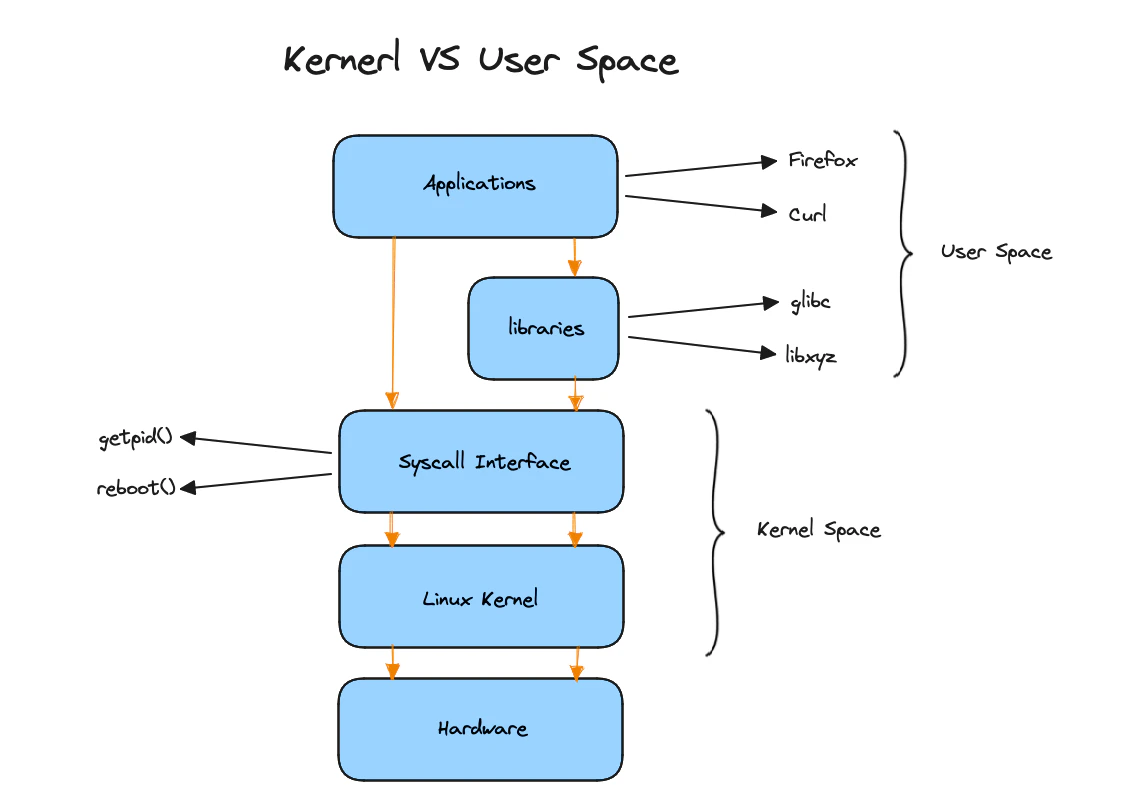
The kernel provides a system call interface, which is usually written in C with some assembly. Examples of system calls include getpid and reboot. Applications and libraries call the system call interface to communicate with the kernel and hardware. The kernel space is at the bottom, while the user space is at the top where applications run. Applications can communicate directly with the system call interface, or they can go through libraries (usually, libraries are used to avoid reinventing the wheel). However, it is possible to write a simple application that calls the Linux kernel syscall directly. When a request is made, the system call interface passes it down to the kernel and then to the hardware.
Linux Kernel Modules (LKMs) allow developers to add new hardware, filesystems, network protocols, or system calls directly into the kernel. But LKMs also pose risks such as bypassing security measures and causing system crashes if kernel code fails, causing safety concerns for users. It is important to note as well that LKMs need regular maintenance, since updating the Linux kernel version may unintentionally cause damage to the module.
What is eBPF?
The Berkeley Packet Filter was created to filter network packets according to specific rules. Essentially, it functioned like a firewall with the filtering process occurring within a registry-based virtual machine. Over time, however, the BPF became outdated because its virtual machine engine and instruction sets were not utilizing the full potential of 64-bit processors.
The eBPF, which is a more advanced version of the BPF, overcomes this limitation by being compatible with modern hardware, including 64-bit chips. This and other improvements enable eBPF to do much more than function as a virtualized firewall. Now, eBPF allows certain applications to be executed in isolation by the kernel without compromising the security of the operating system or other running tasks.
Software engineer Brendan D. Gregg, an expert in this area, compares eBPF to JavaScript in HTML. While HTML limits a web page to static content, JavaScript permits small programs to run in the browser as if it were a virtual machine without compromising the system.
Similarly, eBPF allows applications to access the kernel's structure in a sandbox limited to a set of system resources. The entire execution can be observed in real time, making eBPF widely used for monitoring, analyzing, and filtering tasks related to network or security areas, such as mitigating DDoS attacks.
How does it solve the challenges brought by cloud-native applications?
BPF is a powerful tool that enables users to modify packets, change syscall arguments, and even modify userspace applications. This is useful because it provides a safe alternative to running arbitrary code in the kernel without the need to load it in a kernel module. eBPF is like a kernel module on steroids. It allows you to attach custom sandboxed bytecode to almost every function exported via the kernel symbol table without worrying about breaking the kernel. eBPF prioritizes safety when crossing user space boundaries. The in-kernel verifier will not load any eBPF program if it detects invalid pointer dereferences or exceeds the maximum stack size limit. While loops are not allowed, except for those with constant upper bounds known at compile time, only a small subset of specific eBPF helper functions can be called in the generated bytecode. eBPF programs are guaranteed to terminate at some point and never exhaust system resources, which is not the case with kernel modules that can cause system instability or lead to kernel panics. Some people may find eBPF too restrictive compared to the "freedom" offered by kernel modules. However, the tradeoffs are likely to favor eBPF over "module-oriented" instrumentation, mainly because eBPF programs cannot harm the kernel. Additionally, eBPF provides other benefits besides safety.
For instance, with eBPF, you can easily attain security observability in the kernel without having to make changes to applications or manage a complex distributed system. It is a lightweight solution that simplifies the process, and provides quick answers to the following questions:
Was a process executed with non-standard socket input, representing a Remote Code Execution (RCE) attack?
Did a process attempt to establish a connection to a known crypto-mining domain?
Was there an attempt to access `/etc/passwd`?
See eBPF in action
As system administrators, we are familiar with the benefits of using strace as a tool to monitor system calls. However, it is important to note that this command can create a significant amount of overhead when generating output. Using it on a production server without redundancy could lead to catastrophic consequences. Using BPF, we avoid the risk of impacting the system due to its low overhead.
To provide some context, it's important to note that eBPF cannot be installed like regular software. It originates from the bpf() syscall. The bare minimum kernel version required is 4.4. In my case, I’m running 5.15 on Ubuntu 22.04:
$ uname -a
Linux lima-learning-ebpf 5.15.0-72-generic #79-Ubuntu SMP Tue Apr 18 16:53:43 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.2 LTS
Release: 22.04
Codename: jammy To continue, we'll need to get bcc installed. The BCC project can be found at BCC project. The instructions for installing BCC are available here, and it offers a user-friendly interface for compiling and loading eBPF programs. It is so straightforward that you can utilize a Python script to compile, load, and engage with your program.
#!/usr/bin/python3
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b.trace_print() the code above, the Python program compiles the C code, with no loops, printf, global variables and loads it into the kernel, and attaches it to the execve syscall kprobe. Whenever an application on the virtual machine calls execve(), it triggers the eBPF hello() program. This program writes a trace message into a specific pseudofile, and the trace message is then read by the Python program and displayed to the user.
Run the program using sudo:
sudo python3 hello.pyThey provide a lot of useful examples and a nice tutorial to get started writing eBPF tracers.
eBPF in a nutshell
The Linux kernel has been incorporating the Berkeley Packet Filter (eBPF) extended virtual machine for a few years now. This feature allows users to apply eBPF filters to specific sockets beyond just packet filtering. Custom scripts can be called with minimal overhead at various points in the kernel. Though not a new technology, eBPF is now becoming more mature as microservices are increasingly deployed as orchestrated containers. Correlating latency or performance issues with an API call can be challenging with complex service-to-service communications. Recently, tools have emerged with pre-written eBPF scripts to collect and display packet traffic or generate reports on CPU usage.
The future of eBPF looks very promising as it gains more adoption across industries and platforms, such as cloud providers and container orchestration systems like Kubernetes. With the ongoing development of the eBPF ecosystem, including improved tooling, libraries, and capabilities, programming with eBPF will become easier, and more sophisticated applications will be enabled. The applicability of eBPF will also broaden due to cross-platform support, like Microsoft's eBPF for Windows project. As eBPF gains momentum, it will likely integrate more deeply with existing monitoring, security, and management tools, allowing users to benefit from eBPF without needing to abandon or relearn their current toolsets.
Overall, eBPF is a powerful and versatile technology within the Linux kernel. It is poised for growth and will continue to improve traditional BPF, and open new possibilities in networking, monitoring, security, and more. It is an important technology to learn, as it helps create better and more efficient solutions for Linux systems.















