

À mesure que les organisations intègrent de plus en plus l’IA dans leurs produits et opérations, la sécurisation des systèmes d’IA est devenue une priorité absolue pour SecOps. Mais sécuriser l’IA n’est pas comme sécuriser les logiciels traditionnels – l’IA est un écosystème de modèles, de pipelines de données, de code, d’API et d’intégrations tierces, tous introduisant de nouveaux risques de sécurité et de conformité.
Si vos applications d’IA s’exécutent dans le cloud, ces risques deviennent encore plus difficiles. Les modèles d’IA hébergés dans le cloud interagissent dynamiquement avec des ensembles de données externes, des API et des utilisateurs, ce qui les rend plus vulnérables à l’empoisonnement des données, à l’injection rapide et aux attaques adverses.
Les tests de sécurité traditionnels ne suffisent pas à faire face à l’IA'étendue et complexe. C’est pourquoi le red teaming par IA – une pratique qui simule activement des attaques adversaires dans des conditions réelles – émerge comme un élément clé des stratégies modernes de sécurité de l’IA et un contributeur clé à la Croissance du marché de la cybersécurité en IA.
Avec Durcissement de la réglementation en matière de sécurité de l’IA et l’adoption de l’IA qui monte en flèche, les organisations doivent adopter l’IA pour garder une longueur d’avance sur l’évolution des menaces et les nouvelles opportunités.
Qu’est-ce que le red teaming IA ?
Le red teaming de l’IA est une pratique de cybersécurité qui simule des attaques sur des systèmes d’IA afin d’identifier les vulnérabilités dans des conditions réelles.
Contrairement aux repères de sécurité standard et aux tests de modèles contrôlés, le red teaming de l’IA va au-delà de l’évaluation de la précision et de l’équité du modèle. Il examine l’ensemble du cycle de vie et de la chaîne d’approvisionnement de l’IA – des modèles d’IA et des pipelines de données aux services d’IA hébergés dans le cloud et aux interactions utilisateur-IA, garantissant que chaque composant est résilient face à d’éventuels adversaires.
En adoptant une position adverse, le red teaming de l’IA révèle de manière proactive des faiblesses de sécurité cachées – qu’elles soient introduites via l’entraînement du modèle, des pipelines d’inférence ou des interactions utilisateur en temps réel. Elle va au-delà de l’évaluation statique des modèles et garantit que les systèmes d’IA restent résilients dans des conditions dynamiques et réelles.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Quels tests sont généralement effectués pour la red team IA?
Un red teaming efficace de l’IA nécessite une approche globale qui couvre à la fois les aspects techniques et opérationnels pour couvrir la surface d’attaque étendue des déploiements d’entreprise. Les principaux domaines d’essai sont les suivants :
Biais & Évaluation de l’équité : Évalue si les modèles d’IA produisent des résultats discriminatoires ou biaisés, y compris en cas de stress ou de pression adverse.
Violations de la confidentialité des données : Identifie les risques de Fuite de données ou accès non autorisé, garantissant que les informations sensibles sont protégées sur l’ensemble du pipeline de données
Risques d’interaction humain-IA : Teste la façon dont les systèmes d’IA réagissent aux entrées et utilisations malveillantes ou inattendues des utilisateurs, ce qui est crucial pour détecter des vulnérabilités telles que injection rapide
Défense ML adversaire : Évalue la capacité des systèmes d’IA à résister à des attaques adverses ciblées, telles que l’injection rapide et Empoisonnement des données
Les autres zones de test incluent la performance sous stress, l'analyse des vulnérabilités à l'intégration et la modélisation des menaces spécifiques au scénario.
Ces tests doivent tenir compte de la nature en constante évolution des systèmes d’IA, où le réentraînement continu et la dérive des modèles exigent des mesures de sécurité dynamiques et adaptatives. Comme l’IA évolue constamment, les organisations devraient également investir dans des stratégies robustes de mesure et d’atténuation pour garder une longueur d’avance Risques de sécurité liés à l’IA.
Quel est l'objectif de la red team IA?
Le red teaming de l’IA vise à protéger les utilisateurs et les entreprises contre l’utilisation abusive de l’IA en mettant en évidence (et en corrigeant) les défauts des systèmes d’IA afin que les systèmes d’IA soient résilients et dignes de confiance. Les principaux objectifs du red teaming de l’IA sont les suivants :
Identification des risques : Détecter et corriger les vulnérabilités de l’IA avant que les attaquants ne les exploitent
Renforcement de la résilience : Renforcer les modèles et les infrastructures d’IA contre les menaces adverses
Alignement réglementaire : Respect des exigences de conformité, y compris celles du Loi sur l’IA de l’UE et le Décret exécutif de la Maison Blanche américaine sur l’IA
Confiance du public : S’assurer que l’IA est sûre, fiable et conforme aux normes éthiques
Intégrer l’IA red teaming dans un cadre plus large Gestion des risques par IA stratégie et Cadre de gouvernance de l’IA est essentiel pour assurer une sécurité proactive et à long terme dans toute votre organisation.
State of AI in the Cloud
Based on the sample size of hundreds of thousands of public cloud accounts, our second annual State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

En quoi le red teaming pour l'IA diffère-t-il du red teaming traditionnel?
Alors que le red teaming de l’IA et le red teaming traditionnel se concentrent tous deux sur Identifier les vulnérabilités avant que les attaquants ne puissent les exploiter, ils diffèrent fondamentalement dans la portée, les méthodologies et les objectifs.
Équipe rouge traditionnelle : axée sur l'infrastructure, les réseaux et les applications
Le red teaming traditionnel simule des cyberattaques réelles contre l’infrastructure informatique, les applications et les employés d’une organisation. L’objectif principal est d’évaluer la résistance des défenses de sécurité face aux adversaires en ciblant :
Sécurité du réseau : Exploitation des erreurs de configuration, élévation de privilèges, mouvement latéral
Sécurité des applications : Identifier les vulnérabilités des applications web comme l’injection SQL (SQLi), exécution de code à distance (RCE)et XSS (cross-site scripting)
Ingénierie sociale : Manipuler les employés pour qu’ils révèlent leurs identifiants ou cliquent sur des liens d’hameçonnage
Le red teaming traditionnel est bien défini et suit les normes de l’industrie telles que MITRE ATT&CK, NIST 800-53 et OSSTMM. Les vulnérabilités trouvées ont souvent des correctifs clairs (patching des logiciels, mise à jour des configurations, amélioration de la sensibilisation des utilisateurs).
Simulation d'opposition IA : Élargissement de la surface d'attaque au-delà de la sécurité traditionnelle
Le red teaming de l’IA va au-delà des préoccupations de sécurité traditionnelles pour tenir compte des risques uniques posés par les systèmes d’IA. Au lieu de se contenter de sécuriser l’infrastructure où l’IA s’exécute, elle simule des attaques contradictoires sur le modèle d’IA lui-même, son pipeline de données, ses API et ses interactions en temps réel.
Principales différences
Menaces liées aux données : Contrairement aux vulnérabilités logicielles traditionnelles, les menaces d’IA proviennent de la manipulation des données, de l’empoisonnement des modèles et de l’injection rapide.
Surface d’attaque évolutive : Les modèles d’IA changent de manière dynamique au fur et à mesure qu’ils se reforment, ce qui nécessite des évaluations de sécurité continues.
Sécurité & Chevauchement éthique : Les vulnérabilités de l’IA comprennent les préjugés, la désinformation, les hallucinations et les problèmes de fiabilité, qui sont'Les préoccupations typiques de la cybersécurité traditionnelle.
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
En quoi le red teaming de l'IA diffère du test de modèle d'IA standard
La plupart des tests d’IA se concentrent sur la précision, la détection des biais et les principes d’IA responsable. Cependant, l’équipe rouge de l’IA simule des scénarios d’attaque réels pour découvrir les failles de sécurité au-delà des critères de performance.
| AI Model Testing | AI Red Teaming |
|---|---|
| Evaluates model fairness, accuracy, explainability | Simulates real-world adversarial attacks |
| Uses controlled datasets & scenarios | Tests AI in live, unpredictable environments |
| Focuses on ML robustness | Assesses entire AI supply chain & infrastructure |
| Ensures responsible AI compliance | Validates security, privacy, and resilience |
En intégrant le red teaming de l'IA dans la gestion des risques d'IA et la gouvernance de la sécurité, les organisations peuvent devancer les menaces émergentes, assurer la conformité avec les régulations évolutives (comme l'Acte de l'IA de l'UE), et maintenir la confiance du public dans les applications pilotées par l'IA.
Vulnérabilités courantes et cas d’utilisation réels du red teaming de l’IA
Malgré la complexité de l’IA, les attaques dans le monde réel sont souvent étonnamment simples : elles exploitent des erreurs de configuration, des faiblesses négligées ou une mauvaise hygiène de la sécurité de l’IA. Voici quelques-unes des attaques d’IA les plus courantes :
Attaques par porte dérobée : Des déclencheurs cachés insérés dans les systèmes d’IA peuvent permettre aux attaquants de manipuler secrètement les sorties, créant ainsi des possibilités de contrôle non autorisé.
Injection rapide : En créant des entrées malveillantes, les attaquants peuvent modifier subtilement les réponses de l’IA ou même déclencher des fuites de données involontaires, un peu comme si l’on glissait un cheval de Troie dans un système de confiance.
Empoisonnement des données : L’injection de données d’entraînement corrompues peut lentement fausser le comportement de l’IA, en lui apprenant à agir de manière à favoriser l’agenda d’un attaquant.
Faiblesses de l’intégration : Les vulnérabilités des API et des connexions cloud peuvent exposer les systèmes à l’exploitation, permettant aux attaquants de contourner les mesures de sécurité et d’accéder à des données critiques.
Ces vulnérabilités ne sont pas seulement théoriques. Explorons des cas concrets, découverts par le L’équipe de recherche Wiz, qui ont mis en évidence ces risques :
Fuite de la base de données DeepSeek: Des défauts d’intégration dans le dernier modèle DeepSeek ont conduit à l’exposition de données d’entraînement sensibles de l’IA.
🔍Cet exemple concret montre comment… de nouvelles menaces d’IA peuvent émerger de mauvaises configurations d’accès aux API et aux modèles.
Vulnérabilités de l’IA SAP: Les erreurs de configuration des systèmes d’IA de SAP ont créé des risques cachés de porte dérobée, permettant potentiellement aux attaquants de manipuler les sorties de l’IA.
🔍Cet exemple concret montre comment…même les plateformes AI d'entreprise bien établies peuvent souffrir de points aveugles de sécurité.
Vulnérabilité de l’IA NVIDIA: Les faiblesses de la boîte à outils de conteneurs d’IA de NVIDIA ont permis des attaques par injection rapide, exposant des lacunes dans la sécurité de l’IA au niveau de l’infrastructure.
🔍Cet exemple concret montre comment…les attaquants peuvent manipuler le comportement de l'IA via des attaques basées sur des entrées, affectant les décisions et les sorties pilotées par l'IA.
Risques du modèle Hugging Face: Les vulnérabilités d’empoisonnement des données dans les plateformes populaires d’IA en tant que service de Hugging Face ont permis aux adversaires d’introduire des modifications subtiles et malveillantes aux données d’entraînement.
🔍Cet exemple concret montre comment…même les services AI largement fiables sont susceptibles à la manipulation de données adverses, soulignant la nécessité de tests de sécurité continus.
Quand il s’agit de Sécurité de l’IA, même les plus simples faux pas peuvent avoir des conséquences profondes. Votre organisation a besoin d’une équipe rouge IA continue et proactive pour détecter et résoudre ces problèmes avant qu’ils ne se transforment en violations de sécurité à part entière.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Meilleures pratiques pour l'équipe rouge AI : un cadre en 5 étapes
Pour équiper efficacement les systèmes d’IA, les organisations ont besoin d’un cadre de sécurité évolutif, reproductible et en constante évolution. Les modèles d’IA se réentraînent et se mettent à jour de manière dynamique, ce qui rend les mesures de sécurité statiques inefficaces. Un processus d’équipe rouge d’IA bien structuré garantit que l’IA reste résiliente face aux attaques adverses, aux exploits de biais et aux erreurs de configuration.
Étape 1 : Définir le champ d'application de l'équipe rouge AI
Avant de tester la sécurité AI, les organisations doivent définir :
Quels composants de l'IA nécessitent des tests ?
Robustesse du modèle, intégrations API, sécurité de l'IA basée sur le cloud, intégrité des données de formation
Quels sont les scénarios d'attaque ?
Attaques ML adverses (évasion, empoisonnement), abus d'API, injection de prompt, risques de chaîne logistique
Quelle sécurité & Des exigences de conformité s’appliquent-elles ?
Sécurité de l'IA OWASP, NIST AI RMF, Acte AI EU, SOC 2, GDPR
Étape 2 : Sélectionner et mettre en œuvre des méthodes de test adversarial de l'IA
Le red teaming de l'IA va au-delà des tests de pénétration - il requiert des techniques de ML adversariales pour simuler des menaces AI réelles.
Test centré sur le modèle (évaluation de la robustesse de l'IA)
Essais de perturbation contradictoire : Génère des entrées pour inciter l’IA à se tromper de classification
Inversion de modèle & extraction: Tentatives de reconstitution de données d’entraînement privées à partir de réponses d’IA
Tests de sécurité de pipeline de données
Simulations d’empoisonnement de données : Vérifie si l’injection de données d’entraînement malveillantes fausse le comportement de l’IA
Biais & Évaluation de l’équité : Évalue si les adversaires peuvent exploiter le biais du modèle d’IA à des fins de manipulation
Interaction homme-IA & Sécurité des API
Attaques par injection rapide : Teste si l’IA ignore les mesures de protection via des entrées manipulées
Tests d’abus d’API : Explorer les vulnérabilités de l’API du modèle d’IA (par exemple, la récupération de données sans restriction)
Étape 3 : Automatiser les tests de sécurité en équipe rouge pour l'IA pour l'évolutivité
Il est inefficace de tester manuellement les vulnérabilités de l’IA dans les déploiements à l’échelle du cloud. L’automatisation permet de simuler des attaques antagonistes à grande échelle.
Utiliser la sécurité de l’IA & Outils de test contradictoire
Garak : Outil de test antagoniste open-source pour la sécurité LLM
PyRIT (Python Risk Identification for Generative AI) : Simule des attaques d’évasion et d’extraction de modèles
Contre-ajustement Microsoft : Tests de sécurité de l’IA pour les modèles d’apprentissage automatique
Boîte à outils de robustesse antagoniste (ART) : Simule les attaques et les défenses de l’IA adverse.
Étape 4 : Mettre en place une surveillance continue des risques par l’IA & réponse
Le test de l'apprentissage machine rouge n'est pas un test unique — il doit évoluer en continu à mesure que les modèles d'IA se mettent à jour et se réentrainent.
Stratégies continues de tests de l'apprentissage machine rouge
Mettre en place le partage de renseignements sur les menaces par l’IA : Suivez l’évolution des menaces à partir de MITRE ATLAS et du Top 10 de l’IA OWASP.
Adoptez des tests de sécurité continus par l’IA : Intégrez des tests contradictoires dans les pipelines CI/CD.
Développer un scoring automatisé des risques pour l’IA : Priorisez les vulnérabilités d’IA à haut risque pour la remédiation.
Étape 5 : Aligner les tests de l'apprentissage machine rouge avec la gouvernance et la conformité
Au-delà de la sécurité, les tests de l'apprentissage machine rouge doivent soutenir les lignes directrices réglementaires et éthiques de l'IA pour garantir la conformité.
Sécurité clé de l’IA & Normes de conformité
Cadre de gestion des risques IA DU NIST (AI RMF) : Bonnes pratiques en matière de sécurité de l’IA
Loi de l’UE sur l’IA : Exigences de conformité pour les applications d’IA à haut risque
SOC 2, RGPD, CCPA : Protégez les données personnelles basées sur l’IA
Intégrer les tests d'équipe rouge de l'IA dans la gestion des risques d'entreprise (GRE)
Présentez les résultats aux équipes de gouvernance de l’IA : S’aligner sur l’éthique et les principes d’IA responsable.
Collaboration interfonctionnelle : Impliquez les équipes de sécurité, de science des données et de conformité dans la gestion des risques liés à l’IA.


Comment Wiz améliore-t-il votre sécurité de l'IA ?
Wiz offre une plateforme de sécurité cloud complète qui étend ses capacités pour sécuriser l’infrastructure IA grâce à sa Gestion de la posture de sécurité de l’IA (IA-SPM).
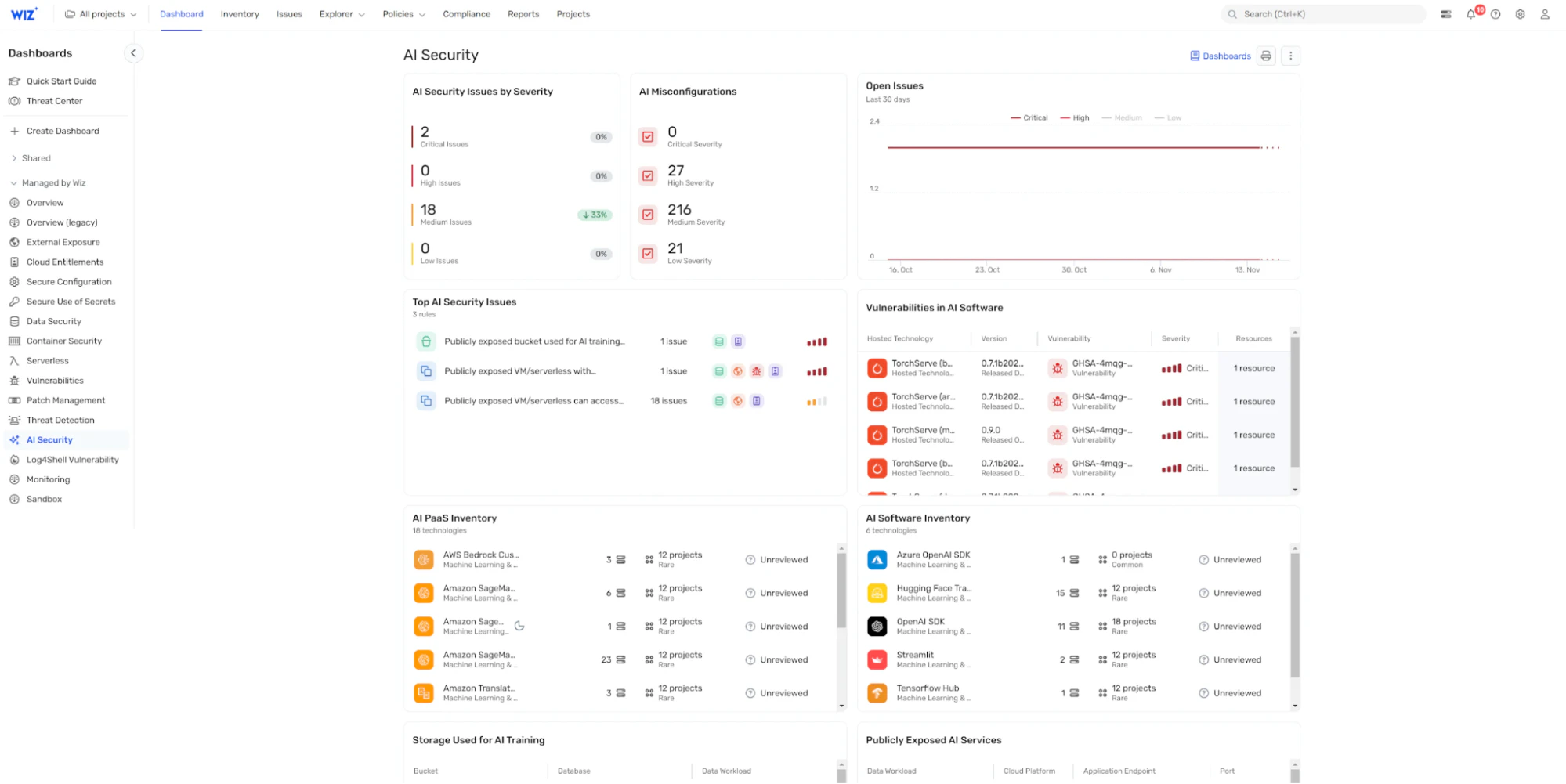
Grâce à son tableau de bord centralisé de sécurité de l’IA, Wiz AI-SPM vous offre :
Une nomenclature IA (AI BOM) : Une carte détaillée de vos composants et dépendances d’IA, offrant une visibilité claire sur l’ensemble de votre écosystème
Détection d’erreur de configuration : Identification automatisée des failles de sécurité dans les pipelines d’IA et les services cloud, pour vous aider à corriger les vulnérabilités avant qu’elles ne s’aggravent
Analyse du chemin d’attaque : Visualisation des itinéraires potentiels que les attaquants pourraient utiliser pour exploiter les risques de sécurité de l’IA, ce qui permet une gestion plus éclairée des risques
Enquête alimentée par l’IA : Accélérez vos efforts de red teaming en IA avec Mika AI, qui vous aide à enquêter rapidement sur les vulnérabilités potentielles, à comprendre des scénarios d’attaque complexes et à obtenir des conseils pratiques en langage naturel
Réponse automatisée : Lorsque le red teaming par IA découvre des vulnérabilités critiques, le Agent IA Wiz SecOps peut automatiser, trier, enquêter et initier les flux de travail de réponse – réduisant ainsi le temps entre la détection et la remédiation
En intégrant ces capacités, Wiz AI-SPM met non seulement en œuvre les meilleures pratiques de sécurité de l’IA mais facilite également la surveillance continue et la gestion automatisée des risques pour votre organisation, garantissant une gouvernance robuste de l’IA.
Quelle est la prochaine étape ?
Le red teaming de l’IA devient une fonction de sécurité essentielle pour les organisations qui s’engagent à protéger leur adoption de l’IA, en particulier à mesure que les exigences réglementaires augmentent. Bien que le domaine continue d’évoluer, des défis tels que les attaques complexes, l’interopérabilité contextuelle et le manque de normalisation persistent.
Une plateforme de sécurité comme Wiz peut vous aider à rester à la pointe des meilleures pratiques de sécurité de l’IA en initialisant vos défenses et en assurant une amélioration continue. Prêt à en savoir plus ? Visitez le
Une plateforme de sécurité comme Wiz peut vous aider à garder une longueur d’avance sur les meilleures pratiques de sécurité de l’IA en renforçant vos défenses et en assurant une amélioration continue. Prêt à en savoir plus ? En savoir plus sur Wiz AI-SPM, ou si vous préférez un Démo live, nous serions ravis de nous connecter avec vous.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
