

Malicious AI models are intentionally weaponized model artifacts that execute harmful actions when they are loaded or run. Unlike vulnerable models – which contain accidental flaws – malicious models are designed to compromise the environment they are deployed in.
The defining characteristic of malicious AI models is that the threat is embedded inside the model file itself. In many cases, attackers abuse unsafe serialization formats to hide executable code within model weights or loading logic. When the model is imported or deserialized, that code executes automatically – often before any inference occurs.
This makes malicious AI models a distinct supply chain threat. They exploit the trust organizations place in pretrained models downloaded from public repositories or shared internally across teams. Because model artifacts are not treated like traditional source code, they frequently bypass security controls such as code review, static analysis, and dependency scanning.
As AI adoption accelerates, pretrained models have become a foundational building block for modern development. That same convenience has turned model artifacts into a high-value attack vector – one that traditional application security tools were never designed to inspect.
Why malicious AI models are a real supply chain risk
Malicious AI models emerge from the same forces that reshaped modern software development: reuse, automation, and trust in external components. Pretrained models are routinely pulled from public repositories to accelerate development, reduce costs, and avoid retraining from scratch. In many organizations, downloading and deploying models has become as routine as installing a library.
This workflow shifts trust away from internally reviewed code and toward external artifacts that are rarely inspected. Model files are often treated as opaque binaries – stored, shared, and loaded without the scrutiny applied to application code or container images. As a result, they frequently bypass established security controls such as code review, static analysis, and dependency scanning.
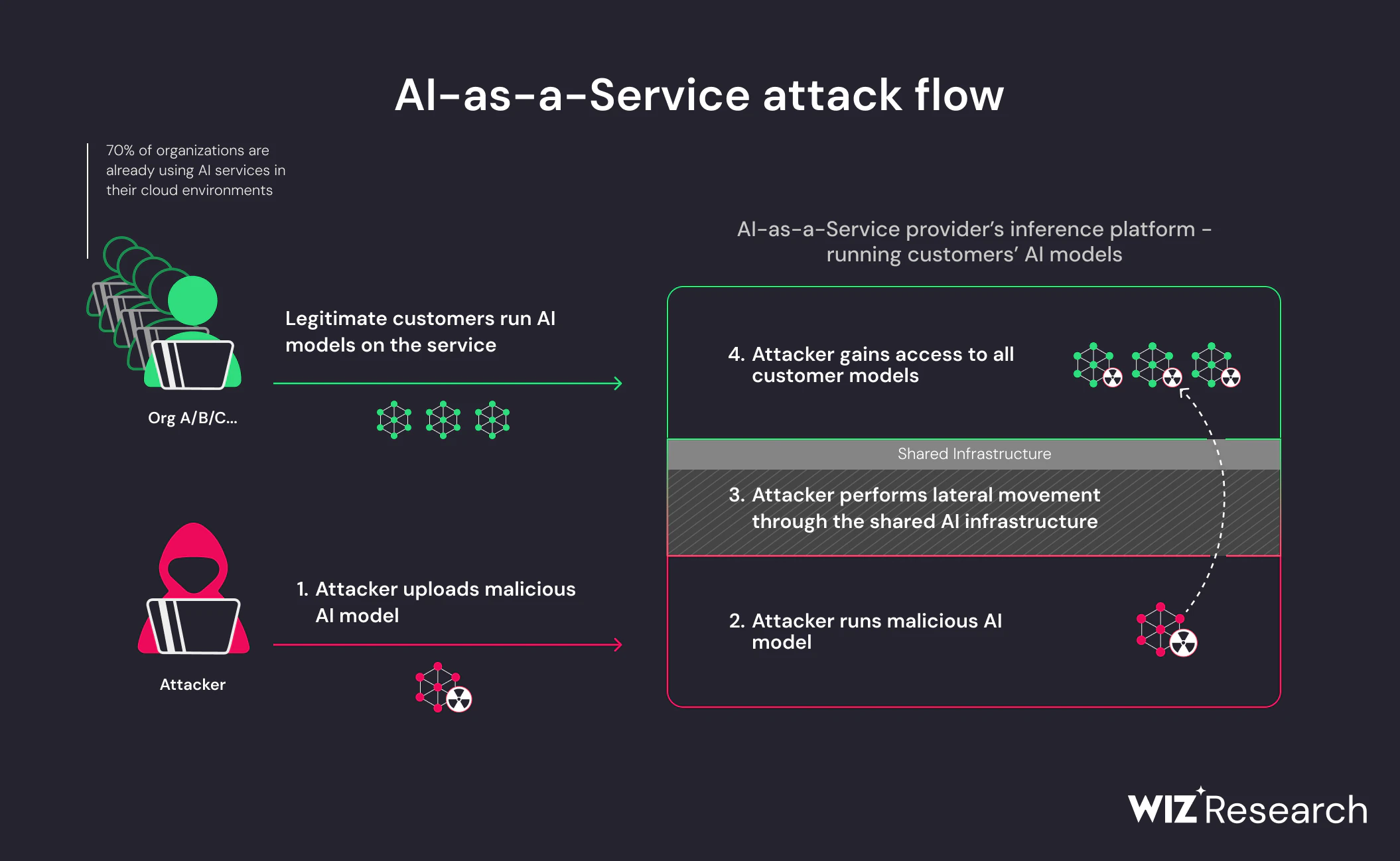
What makes this risk particularly acute is that malicious models exploit expected behavior. Loading a model is a normal, trusted action in AI pipelines. When attackers embed executable logic into model artifacts, that trust becomes the delivery mechanism. No exploit chain is required; the compromise occurs because the system is doing exactly what it was designed to do.
This is why malicious AI models represent a supply chain threat rather than an application bug. The risk does not originate from how a model is used, but from where it comes from and how it is loaded. As model reuse continues to scale across teams and environments, the ability to validate model provenance and behavior becomes a foundational security requirement.
The 4-Step Framework for AI Threat Readiness
Wiz has designed a 4-step framework to help organizations defend against rapid, automated exploitation in a post-Mythos world.

How malicious AI models work at a high-level
Malicious AI models exploit how models are packaged, distributed, and loaded in modern AI workflows. The core risk is not the model’s predictions, but the execution path triggered when a model file is deserialized or initialized.
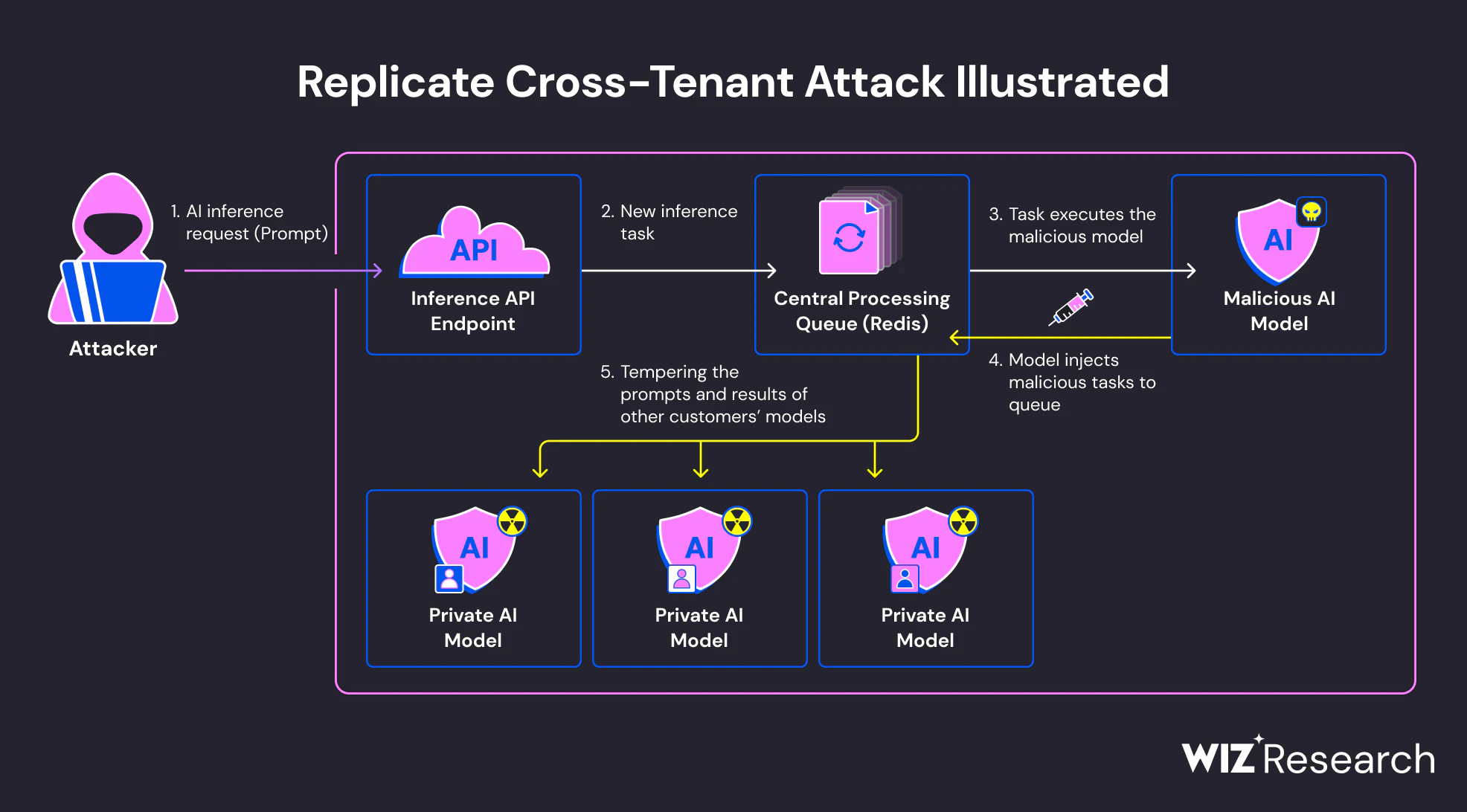
Execution during model loading
Many AI frameworks support serialization formats that allow executable logic to run as part of the model loading process. In particular, Python’s pickle-based formats – commonly used in PyTorch and related tooling—can execute arbitrary code when a model is deserialized. This behavior is documented, but often overlooked in practice.
When a malicious model is loaded, embedded code can execute immediately, before inference or evaluation occurs. From the system’s perspective, this looks like a normal model import. From an attacker’s perspective, it is a reliable execution point inside a trusted environment.
Why this happens before inference
Unlike application code, models are treated as data. Security controls tend to focus on how models are used, not how they are loaded. As a result, the most dangerous activity happens early in the lifecycle – at load time – before runtime monitoring, access controls, or behavioral checks are applied.
This is what makes malicious models difficult to detect with traditional tools. There may be no suspicious API calls, no malformed inputs, and no abnormal outputs. The compromise occurs simply because the model was accepted as legitimate.
Common attacker objectives
Once execution is achieved, attackers typically pursue familiar goals:
Stealing credentials or tokens available in the environment
Accessing training data or downstream data stores
Establishing persistence through backdoors or scheduled tasks
Consuming compute resources for cryptomining or further compromise
These actions are not unique to AI environments, but models often run with elevated permissions and proximity to sensitive data, increasing their impact.
Safer formats, safer defaults
Not all model formats carry the same risk. Formats designed to separate weights from executable logic – such as SafeTensors and ONNX – reduce the likelihood of code execution during model loading. These formats store model data without embedded execution paths, making them safer by design.
By contrast, serialization mechanisms that allow executable logic during deserialization increase risk unless they are tightly controlled. In practice, compatibility and convenience often lead teams to default to unsafe formats unless explicit security standards are enforced.
Understanding how models are loaded is therefore central to defending against malicious AI models. The threat does not rely on adversarial inputs or novel AI behavior – it relies on predictable, trusted execution paths in common ML tooling.
Primary attack vectors for malicious AI models
Malicious AI models typically reach production through a small number of repeatable attack vectors. These vectors exploit trust in model artifacts and automation in AI workflows rather than novel AI behavior.
Public model repositories
Public repositories are the most common distribution channel for malicious models. Attackers upload weaponized models to popular platforms or use typosquatting to mimic well-known projects. Over time, they may build reputation through benign releases before introducing a malicious version.
Because pretrained models are often downloaded directly into development or training environments, these artifacts can bypass the review processes applied to application code or container images.
Remote code execution via model loaders
Some AI workflows explicitly allow remote or custom code execution during model loading. Settings such as permissive loader flags or custom model classes expand the attack surface by allowing executable logic to be fetched and run dynamically.
In these cases, the risk does not come from the model weights themselves, but from the loading mechanism that implicitly trusts external code. This makes loader configuration an important part of the threat model.
Trojan models and learned backdoors
Not all malicious models rely on execution during loading. Some are designed to behave normally under most conditions while producing malicious outputs when specific triggers are present. These “Trojan” models embed harmful behavior directly into learned weights rather than executable code.
Unlike serialization-based attacks, Trojan models typically target the training or fine-tuning process, such as through poisoned training data or manipulated fine-tuning workflows. Because the malicious behavior is encoded in the model’s parameters, static scanning of the model artifact offers limited visibility into the threat.
This makes Trojan models a distinct risk category. Detecting them generally requires adversarial testing, behavioral analysis, or validation of training data and lineage, rather than inspection of the model file alone.
Dependency and insider risk
Malicious models can also enter environments through compromised dependencies or trusted internal channels. This includes poisoned ML libraries, insecure internal registries, or models introduced by insiders with legitimate access.
Because these vectors rely on existing trust relationships, they are often overlooked in early threat modeling, despite having the potential for broad impact.
Why cloud environments amplify the risk
Cloud environments don’t create malicious AI models, but they significantly increase the impact and speed of compromise when one is introduced. The same characteristics that make cloud platforms ideal for AI – automation, scale, and access to sensitive data – also magnify supply chain risk.
AI workloads frequently run with elevated permissions. Training jobs and inference services often require access to large datasets, object storage, secrets, and downstream services. When a malicious model executes inside this context, it can immediately inherit those privileges, expanding blast radius beyond the model itself.
Automation further amplifies the risk. Models are commonly deployed through CI/CD pipelines, orchestration frameworks, or scheduled retraining workflows. Once a malicious artifact enters one of these paths, it can propagate rapidly across environments without human intervention, making manual inspection impractical.
Cloud infrastructure also changes where execution occurs relative to sensitive data. Malicious models typically execute within the same data plane as the data they are meant to access, rather than adjacent to it. Unlike a compromised web application that must pivot laterally to reach a database, a model often runs inside the environment that already has direct access to training data, inference inputs, or downstream systems. This collapses the distance between execution and impact.
Finally, AI workloads depend on complex stacks of managed services, containers, GPUs, and runtime dependencies. Each layer introduces configuration and isolation challenges that attackers can exploit if controls are misapplied. In practice, this means malicious models benefit from the same misconfigurations that drive many cloud breaches today.
Together, these factors turn malicious AI models from a localized risk into a system-level security concern, reinforcing why model security must be evaluated in the context of cloud identities, data access, and deployment pipelines – not in isolation.
Inside MCP Security: A Field Guide
Explore emerging AI security risks and how protocol-level threats expand the attack surface in cloud environments.

Defending against malicious AI models
Defending against malicious AI models requires a shift in focus from model behavior to model provenance, loading paths, and execution context. Because the threat is embedded in the artifact or training process itself, traditional application security controls are necessary but aren't enough on their own.
Establish controls before models reach production
The most effective defenses operate before a model is loaded. This includes validating where models come from, how they are packaged, and what code paths are executed during loading. Treating model artifacts as first-class supply chain components – subject to inspection, approval, and version control – reduces the likelihood that weaponized models reach sensitive environments.
In practice, this means applying the same governance to model registries that organizations already apply to container registries or artifact repositories. If container images are signed, scanned, and promoted through controlled pipelines, model artifacts should follow the same discipline – regardless of whether they originate internally or from public sources.
Where possible, teams should prefer model formats that separate data from executable logic and restrict loader configurations that implicitly trust external code. These controls don’t eliminate risk, but they significantly narrow the attack surface.
Constrain execution through identity and access controls
Malicious models are most dangerous when they inherit broad permissions. Limiting the identities and roles available to training and inference workloads reduces blast radius if a model is compromised. This includes enforcing least privilege for service accounts, isolating environments, and avoiding shared credentials across pipelines.
Because models often execute inside the data plane, access control becomes a primary line of defense – not a secondary safeguard.
Monitor behavior in context, not in isolation
Static inspection alone cannot catch every malicious model, particularly those that embed behavior in learned weights. Runtime visibility helps fill that gap by observing how models interact with their environment over time.
Effective monitoring focuses on contextual signals: unexpected network access, unusual file operations, abnormal identity usage, or deviations from established execution patterns. These signals are most meaningful when correlated with cloud context – what data the model can access, which identities it uses, and how it was deployed.
Treat model security as part of cloud security
Ultimately, defending against malicious AI models is not a standalone discipline. It requires integrating AI-specific considerations into existing cloud security practices, including supply chain governance, identity management, and workload monitoring.
By evaluating models as part of the broader system they operate within – rather than as opaque black boxes – security teams can reduce exposure to malicious artifacts without relying on speculative detection or assumptions about model behavior.
How Wiz helps reduce the risk of malicious AI models
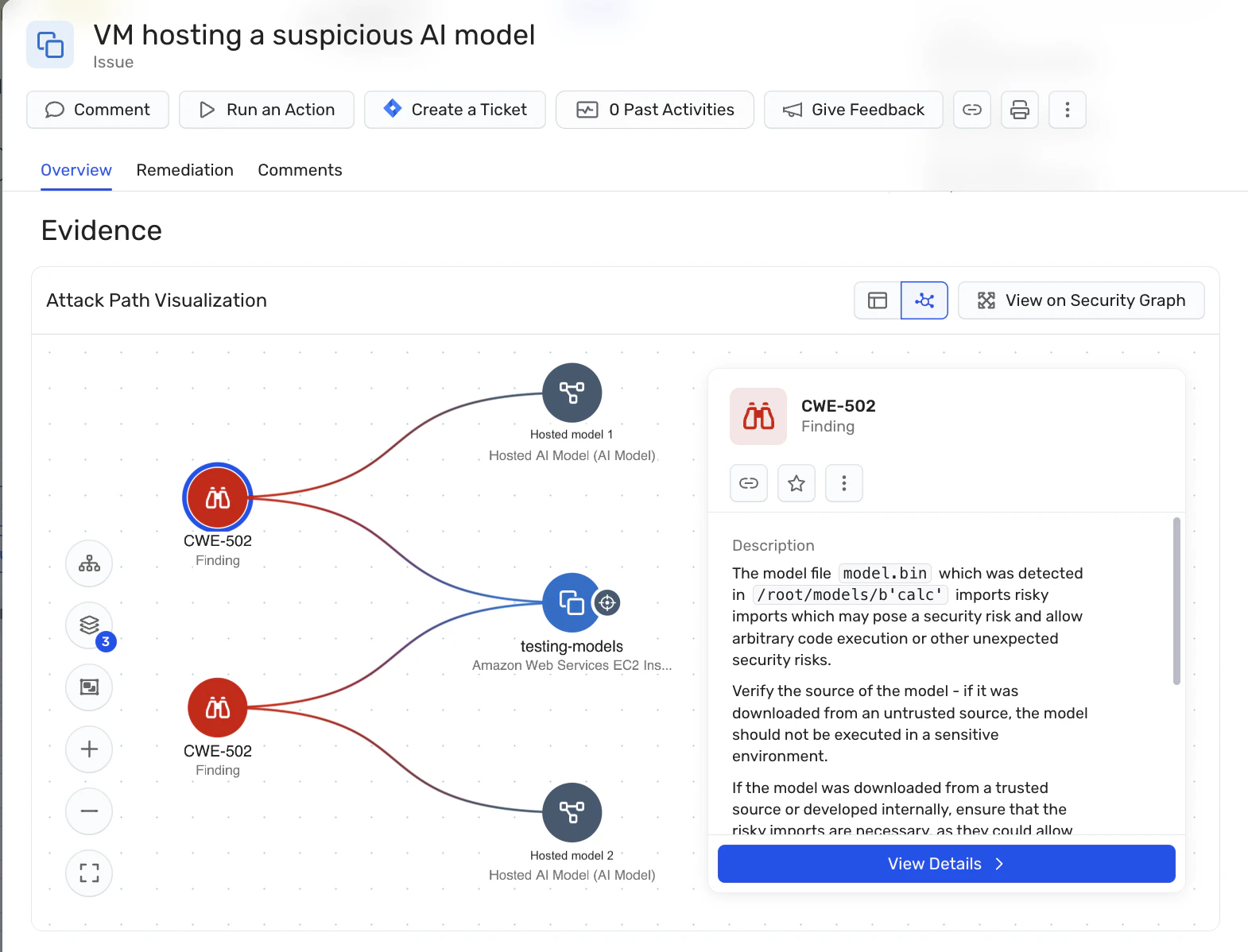
Wiz helps organizations reduce the risk of malicious AI models by grounding model security in cloud security fundamentals. Rather than attempting to classify model intent or behavior, Wiz focuses on validating the controls that determine where models come from, how they are loaded, and what they can access once deployed.
Through AI Security Posture Management (AI-SPM) and the Wiz Security Graph, AI models, training jobs, inference services, and registries are treated as first-class cloud assets. Wiz provides visibility into hosted model artifacts and performs format-level inspection to surface risky serialization methods or untrusted sources – extending software supply chain discipline to AI models before they reach production.
By correlating model artifacts with identities, permissions, network exposure, and sensitive data access, Wiz helps teams identify when a risky or potentially malicious model becomes exploitable in practice, understand its true blast radius, and prioritize remediation based on real attack paths – without slowing down AI development or introducing separate security tooling.
Want to see how Wiz connects model risk to cloud context across your environment? Get a demo to explore AI-SPM and the Security Graph in action.
See how AI-APP connects the full stack
Experience Wiz's unified security graph mapping code, cloud, and runtime for your AI workloads.
