



Amazon Elastic Container Service (ECS) delivers platform-based speed and consistency, representing a massive improvement in operational efficiency. But ECS also presents a significant challenge: financial management. Without a structured approach to cloud costs, your cloud bill can quickly become a big source of stress, undermining many of the benefits you expected from cloud services.
Enter ECS cost optimization. By carefully managing ECS spend, you’ll accelerate innovation efforts, minimize operational costs, and achieve architectural efficiency without compromising performance.
This article provides step-by-step guidance on optimizing ECS costs, along with practical methods and tools to help you control your container expenses and eliminate cloud waste.
The Cloud Visibility Playbook
Read this playbook to achieve continuous, agent-less visibility across every cloud resource and data flow.

What contributes to ECS costs?
To effectively manage your expenses, you need to understand what factors into your ECS costs based on your chosen launch type: Fargate or EC2.
ECS on Fargate
Fargate's serverless operations mean you only pay for the resources you request, not for the underlying servers. Fargate costs are determined by:
Task definition vCPU and memory settings
Task duration (billed per second, 1-minute minimum)
Ephemeral storage usage (charged for configured storage beyond the 20 GB free tier)
Data transfer costs (including inter-AZ and internet egress under standard EC2 data transfer rates), NAT Gateway hourly and per-GB processing charges, load balancer hours/LCUs, and public IPv4 address charges; ENIs for ECS tasks aren’t typically billed as a separate line item.
ECS on EC2
When using EC2, the main cost factor is the cluster's EC2 instances themselves. Unlike Fargate, you pay for the full capacity of each instance, regardless of how much you use it. Therefore, a key to reducing costs is improving your utilization rates. Additional significant expenses for this launch type include EBS volumes and load balancer costs. The two primary causes of cloud waste in this model stem from poor container density (bin-packing) and misconfigured autoscaling, which results in idle capacity.
Fargate vs. EC2: Cost trade-offs
The decision between Fargate and EC2 has a significant impact on your management practices and financial costs. The best choice depends on workload patterns and your team's operational expertise:
| Column A | Column B | New Column |
|---|---|---|
| Management model | AWS Fargate operates without server management, as AWS controls the underlying infrastructure. | You are responsible for preparing, operating, and scaling the EC2 instances. |
| Cost structure | You pay per second for provisioned vCPU and memory while tasks run (plus any configured ephemeral storage beyond the included 20 GB baseline). | The entire cost of an EC2 instance exists, regardless of how much you use it. |
| Ideal workloads | Best for sporadic bursts of work and unpredictable workloads; great for stateless applications and batch jobs | You should use steady-state applications with predictable operation when you want to achieve maximum resource utilization. |
| Pros |
|
|
| Cons |
|
|
To begin, assess your workload patterns. The Fargate launch type is best suited for applications with fluctuating traffic patterns or for teams that want to minimize operational responsibilities. On the other hand, the EC2 launch type offers better cost efficiency for applications with consistent usage and allows for active capacity management.
EBS Cost Optimization: How to stop your block storage bill from spiraling
This guide is about smart cloud cost optimization, eliminating cloud waste and ensuring every dollar spent on storage delivers real value. Let's dig into the actionable strategies to get your EBS spend under control for good.
Read more

Common ECS cost optimization challenges
The main obstacles to controlling ECS costs stem from visibility, processes, and ownership, rather than purely technological challenges:
Right-sizing problems: A common pitfall is that developers frequently over-allocate CPU and memory resources to avoid performance issues. Without adequate historical data to guide their decisions, this guesswork often results in substantial cloud waste.
Complex multi-account AWS environments: It's easy to lose track of active services, but that adds up: The system continues to charge customers for idle services, forgotten test deployments, and underutilized tasks. Since no one knows who owns these resources or if they are still needed, a cycle of waste can continue for a long time.
Idle and underused resources: The combination of idle resources, underused services, and disused assets creates a large amount of cloud waste. And this problem extends beyond the retired ECS services themselves: Service deployments often require EBS volumes, EBS snapshots, Application Load Balancers, and target groups, which can remain active even after the service has been decommissioned.
The absence of direct cost responsibility: When there's no direct cost responsibility, no one needs to take accountability for the expense of a service. To make matters worse, if developers can’t monitor monthly costs when deploying resource-intensive services, external costs become invisible.


Best practices for ECS cost optimization
Now that we've identified the problems, let's examine specific steps to help manage your ECS expenses.
Right-size tasks
The correct sizing of tasks is the single most effective method to optimize cloud cost expenses. Once tasks are right-sized, your expenses reflect your actual needs and nothing more.
Actionable items
Monitor CPU and memory usage patterns using CloudWatch Container Insights to establish performance thresholds from historical data.
Modify task definitions to reflect measured peak usage while maintaining a security buffer to handle temporary capacity surges.
Perform regular checks and implement automated right-sizing because application performance evolves over time.
Here’s an example of quick, data-driven right-sizing:
Pick a service (such as orders-api on Fargate currently 1 vCPU / 2 GB; desired count 5)
Pull the last 14 days from CloudWatch Container Insights: p95 CPU ~40%, p95 memory ~0.8 GiB, short spikes to 60% / 1.1 GiB
Choose a headroom target of ~70% at peak. New task size: 0.5 vCPU / 1 GB (fits observed peaks + buffer; confirm the selection matches Fargate’s valid CPU/memory combinations in your region).
Impact: vCPU -50% and memory -50% per task: ~45–50% lower Fargate task cost
Cloud cost optimization tools
In this blog post, we'll explore the key features and benefits of these tools and help you choose the right one for your organization.
Read more

Reduce idle or unused services
Eliminating idle resources lets you reduce cloud costs immediately. Remember: Any payment for unused services is 100% wasted.
Actionable items
Create automated "janitor" scripts to identify services that remain idle for extended periods.
Implement lifecycle policies and schedulers that automatically shut down non-production resources during off-business hours.
Enforce detailed tagging schemes so that everyone knows who owns what, allowing for accountability and safe resource removal.
Optimize launch type usage
Selecting appropriate launch types for different workloads helps users avoid both the convenience costs of Fargate and the idle capacity expenses of EC2.
Actionable items
Classify your applications based on their steady-state or intermittent workload characteristics.
Use a hybrid strategy, where steady-state workloads utilize EC2, and Fargate handles unpredictable and intermittent jobs.
Guide autoscaling decisions with application-specific metrics, such as SQS queue depth or latency, instead of relying solely on CPU metrics.
ECS Service autoscaling: Use target-tracking policies based on queue depth, request latency, or custom metrics. Example:
{
"TargetValue": 70,
"PredefinedMetricType": "ECSServiceAverageCPUUtilization"
}
Capacity Providers: Combine On-Demand and Spot with managed draining to minimize stranded capacity and automate interruption handling.
Maximize container density (for EC2)
To truly get the most from your EC2 setup while keeping costs down, it's all about how efficiently you distribute the containers on those instances.
Actionable items
Use EC2 Spot Instances for any fault-tolerant and stateless workloads to reach maximum savings potential.
Employ the binpack task placement strategyto achieve complete instance filling and minimize resource fragmentation. This ensures your cluster consolidates tasks onto the fewest possible instances, reducing overall cost.
Implement Cluster Auto Scaling with managed instance draining to remove underutilized instances gracefully.
Ownership and tagging for ECS cost accountability
You can't optimize what you can't measure, and you can't control what you don't own. Any successful cloud spend management program requires a strong tagging system that provides consistent and detailed organization. The ability to segment your cost data through team, application, environment, and business dimensions provides you with essential capabilities.
Actionable items
Implement tagging requirements as a deployment policy to require standard tags for all ECS services and task definitions.
Maintain tag hygiene because reporting fails when different keys use inconsistent formatting (e.g., "team" vs. "Team").
Use custom dashboards to generate cost visibility reports that directly associate cloud expenses with workload owners through their assigned tags.
Trigger automatic alerts when either an untagged resource starts running or a tagged service demonstrates unexpected cost increases.
Automating ECS cost optimization
Manual optimization makes a big difference, but the main path to real efficiency requires automation. Continuous cloud cost savings happen when you implement cost controls directly into operational workflows:
Automate shutdowns that detect and terminate idle services and clusters. This practice should be mandatory for all non-production environments because it can result in double-digit savings.
Implement scheduled scaling policies to automatically shut down dev/test clusters during weekend and nighttime hours. This simple adjustment can lead to a more than 75% cost reduction—you’ll be running dev clusters for 8 hours a day, 5 days a week, instead of 24 hours a day, 7 days a week.
Integrate cost checks into your CI/CD pipeline using open-source tools or custom scripts. This allows you to analyze the cost implications of infrastructure changes right within a pull request. Automated checks detect developers who unintentionally request web servers with 16 vCPUs, staving off cloud waste before deployment.
Integrate cost checks directly into your infrastructure code when using Terraform or CloudFormation. The Open Policy Agent (OPA) framework enables you to define policies that restrict deployments of expensive instance types and mandate cost-related tags and task-sizing constraints.
Tools for ECS cost optimization
Managing this complex system doesn't require your full attention. You can easily get visibility and control over your cloud resources using AWS's own tools or other third-party platforms:
AWS-native solutions
Amazon CloudWatch is AWS's core monitoring tool. It lets you collect utilization data for right-sizing and configure alarms on operational metrics. For spend alerts and anomalies, use AWS Budgets and AWS Cost Anomaly Detection.
AWS Cost Explorer is the main tool for visualizing and analyzing spending patterns. It uses service filtering (ECS), tagging features, and launch type selection to help users understand their expenditures and identify costly services.
AWS Compute Optimizer analyzes CloudWatch metrics to recommend optimal resource sizes, helping users select the best EC2 instance types and CPU/memory configurations for Fargate ECS.
AWS Trusted Advisor performs high-level checks across accounts to identify cloud waste, such as idle load balancers, unattached EBS volumes, and underused EC2 instances in inactive clusters.
Engineering-centric platforms
While AWS tools are robust, they often operate in silos. AWS Cost Explorer shows you what you're spending, and CloudWatch explains why (utilization), but neither connects these insights to crucial security or architectural contexts. This creates a gap for engineers, who need a unified view.
That’s where platforms like Wiz Cloud Cost come in. Teams can pull granular spend, usage, and savings opportunities directly into the Wiz Security Graph while using agentless scanning to discover resources, validate tag guardrails, and work alongside AWS Organizations Tag Policies (which can enforce compliant tagging on supported resources) to map resources to owners. By layering cost, security, and architectural context together, teams close ownership gaps and act with confidence. The platform also unifies context across Fargate and EC2 services into a single view, enabling you to choose the optimal launch type based on a comprehensive understanding of usage patterns, risk, and configuration.
Wiz’s secret weapon is the Wiz Security Graph, which reveals high-cost workloads with high risk. It enables engineers to direct optimization efforts to expensive, overprovisioned services that also handle sensitive data or have critical vulnerabilities. The result is risk‑prioritized remediation: You cut spend where it also reduces risk and strengthens your security posture.
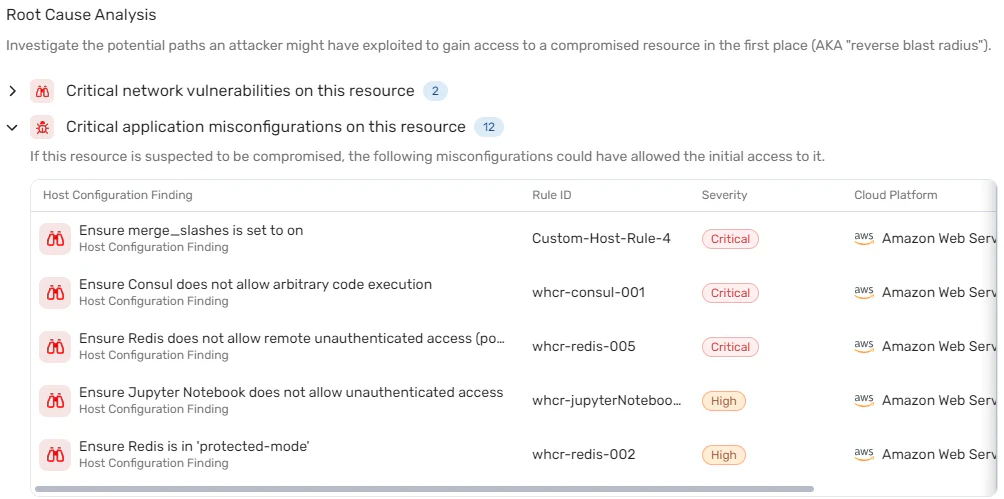
Context is king in ECS cost optimization
Context is the primary determining factor for cost-optimization success. A graph-based view lets you target the services where every dollar saved also reduces risk, like overprovisioned, internet-exposed workloads with critical vulnerabilities or sensitive data access. Example: A payments service on Fargate showed the highest monthly spend and p95 CPU under 35%. The graph view revealed it was also internet-exposed with an admin role attached. The team right-sized tasks, removed public exposure, and scoped the role, cutting cost ~40% while eliminating a critical attack path.
Wiz Cloud Cost unifies spend data with configuration, vulnerability, network exposure, and identity context in a single, queryable platform that supports secure optimization decisions. Teams can use Cost Explorer to drill into the ECS services, tasks, and supporting resources driving spend, apply context-aware optimization rules to surface waste, and set cost monitors to catch spikes before they become monthly surprises. With everything visible in one place, you can safely remove unnecessary resources and right-size tasks because you know which dependencies, owners, and risks sit behind each change.
That same context matters for AI-related container workloads too. If you run ECS services for inference APIs, embedding workers, or retrieval pipelines, Wiz helps you distinguish legitimate burst demand from waste and shows which services are tied to sensitive data or model endpoints, so you can cut spend without breaking performance or weakening your AI security posture.

Ready to see how a context-rich approach can transform ECS cost management and security? Schedule a live demo to experience how the Security Graph unifies code-to-cloud context into actionable insights.
Manage Cloud Costs with Wiz
Learn how Wiz combines security insights with cost visibility to maximize business outcomes.
