



Organizations turn to Amazon EKS because it delivers AWS’s hallmark power, scalability, and rock‑solid reliability. It's the gold standard for running production Kubernetes. But as many businesses have discovered, that power comes with a hidden price tag—one that can quickly spiral out of control if left unchecked.
It's easy to launch fresh clusters for every project, feature branch, or test cycle. Deployments sail through, and at first, everything appears smooth. Months later, an eye‑watering AWS invoice hits finance. Engineering teams are asked to cut costs, but without clear data, they're flying blind. Where do you even start?
Read on to explore what really drives your Amazon EKS spend, learn the most common and costly pitfalls, and find practical, engineering-driven strategies to reduce waste.
EKS Security Best Practices [Cheat Sheet]
This 14-page cheat sheet is packed with actionable advice that you can put can in place immediately. You'll learn how to improve the security posture of your EKS environment, from initial setup to ongoing monitoring and compliance.

What drives cost in Amazon EKS?
Picture your EKS bill not as a solitary charge but as a web of interconnected AWS services. Here are the primary cost drivers:
EC2 compute costs: This is almost always the most significant driver of your EKS bill. The cost is directly tied to the instance types, pricing models (On-Demand, Spot Instances, Savings Plans), and the number of nodes running. Overprovisioned nodes, underutilized Auto Scaling groups, and a heavy reliance on expensive On-Demand instances are the main culprits.
Elastic Load Balancers (ELBs): Application Load Balancers (ALBs) and Network Load Balancers (NLBs) are created by Kubernetes Service or Ingress objects to expose your applications. These have an hourly cost, data processing fees, and are often left running long after the associated service has been deleted.
EBS volumes: Stateful applications rely on Persistent Volumes (PVs), which are backed by Amazon EBS. These volumes persist even after the pods using them are terminated. Without proper garbage collection, you can accumulate a costly collection of orphaned volumes.
Network and data transfer costs: Data transfer fees can be a significant and often overlooked expense, especially for traffic between Availability Zones (AZs), across regions, or out to the internet through services like NAT gateways.
Idle resources: This category represents pure cloud waste, such as forgotten namespaces, zombie pods, or entire dormant clusters.
Container image storage and registry costs: Private registries such as Amazon ECR charge for both storing image layers and the data transferred every time nodes pull them. Stale, untagged, or redundant images quietly accumulate storage fees and can balloon costs if left unmanaged.
Common EKS cost optimization challenges
The common pain points are widespread, so if they sound familiar, you're not alone:
| Common pitfalls | Better approach |
|---|---|
| "Just-in-case" overprovisioning | Right-sizing with VPA and monitoring |
| Setting high CPU/memory requests to avoid issues | Using tools to analyze actual usage and set appropriate requests |
| Always-on dev/test clusters | Automated downtime scheduling |
| Running non-production environments 24/7 | Shutting down idle clusters during nights and weekends |
| Opaque, cluster-level billing | Granular, per-team cost attribution |
| Receiving a single bill with no workload breakdown | Using labels and tools to see who is spending what |
| Finance owns cost, engineering owns infrastructure | Shared ownership and visibility |
| Siloed responsibilities that create a disconnect and blame | Empowering engineers with cost data to make informed decisions |
Kubernetes Security Best Practices [Cheat Sheet]
This 6 page cheat sheet goes beyond the basics and cover security best practices for Kubernetes pods, components, and network security.

Best practices for EKS cost optimization
Cutting EKS expenses demands a layered strategy that blends smart resource sizing, thoughtful architecture, and heavy doses of automation. The following best practices are actionable steps your engineering team can take to immediately optimize your cloud spend management strategy.
Right-size nodes and workloads
The most effective way to cut costs is to stop paying for resources you don't need. Right‑sizing means tuning your infrastructure footprint so it mirrors real‑world workload demand—delivering exactly the CPU, memory, and storage your services consume, and nothing more.
Use the Vertical Pod Autoscaler (VPA): The VPA analyzes pod consumption and can automatically adjust pod CPU and memory requests to optimal values. Run it in recommendation mode first to gain insights before enabling full automation.
Audit pod resource usage: Install Metrics Server to utilize tools like kubectl top or Prometheus and compare the requested resources with actual usage.
Choose the right instance types: Don't default to general-purpose instances. Use burstable T-family instances for variable workloads or compute-optimized C-family instances for intensive jobs.
Group similar workloads: Use Kubernetes node selectors and taints/tolerations to schedule pods with similar resource profiles onto dedicated node groups with optimized instance types.
Leverage intelligent node autoscaling: Pair Cluster Autoscaler or Karpenter with well‑labeled, heterogeneous node groups so the cluster expands just‑in‑time for demand spikes and contracts to zero when workloads subside, eliminating silent over‑provisioning.
Use Spot Instances for flexible workloads
Amazon EC2 Spot Instances offer access to spare AWS compute capacity at discounts of up to 90% compared to On-Demand prices. Because they can be interrupted at any time, Spot Instances excel at running resilient or loosely coupled jobs.
Below are quick, actionable steps to squeeze maximum savings from Spot Instances without sacrificing reliability:
Identify Spot-friendly workloads: CI/CD pipelines, batch processing, data analytics, and dev/test environments are excellent candidates for Spot.
Use a smart autoscaler: Tools like Karpenter are highly effective for managing Spot nodes, as they provision from diverse pools to improve reliability and optimize instance selection. While the Cluster Autoscaler can also work with Spot Instances, Karpenter's direct integration with EC2 and dynamic instance provisioning often leads to greater efficiency and faster scaling for Spot workloads.
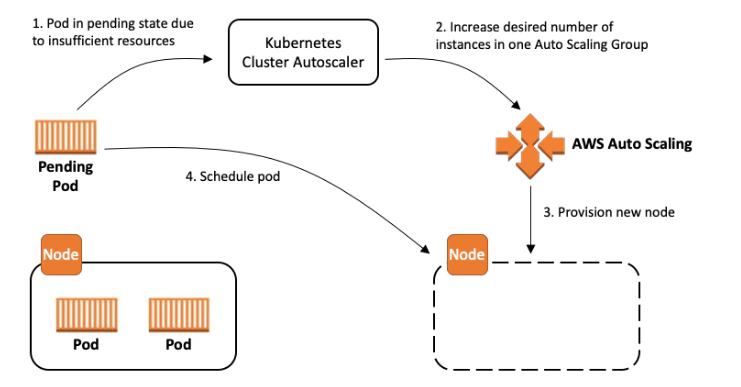
Mitigate interruption risk: Design resilient applications by using features such as pod anti-affinity and topology spread constraints to distribute replicas across multiple nodes, reducing the impact of a single Spot interruption.
Clean up idle or unused resources
As we’ve seen, orphaned resources are a significant source of cloud waste. A regular cleanup routine is the basis of good infrastructure hygiene:
Audit service traffic: Periodically review services and ingresses. If a service has had zero traffic for weeks, it's a candidate for decommissioning.
Garbage collect orphans: Use scripts or specialized tools to find and delete EBS volumes in an available state (meaning they are not attached to any EC2 instance) and Elastic Load Balancers (ELBs) not associated with any active Kubernetes service or other compute resource.
Implement TTL labels: For temporary resources, add a delete-after label with a future date. An automated script can then scan for and delete expired resources.
Schedule non-production cluster downtime
Make sure you’re not paying for development and staging clusters when they're not in use:
Automate shutdowns: Use the AWS Instance Scheduler or custom Lambda scripts to automatically stop or scale down node groups during off-hours and on weekends.
Embrace infrastructure as code (IaC): Use Terraform or CloudFormation to define non-production environments. This makes it trivial to tear them down and rebuild them in minutes.


Decommissioning outdated EKS clusters
Sometimes, the most significant savings come from getting rid of what you no longer need. Old EKS clusters cost more than just money. Aside from accruing full infrastructure costs even when idle, they represent a hidden liability because they prevent modernization and pose security risks from running unsupported Kubernetes versions.
Implement cluster lifecycle management: Make cluster lifecycle management a core part of your platform hygiene. Clusters should have clear owners and an expected end-of-life (EOL) date.
Use tools to identify forgotten clusters: Wiz, with its agentless scanning approach, automatically discovers every EKS cluster across all your accounts, immediately flagging those that are unused, running unsupported versions, or have critical security misconfigurations. This provides a clear, prioritized list for secure decommissioning and eliminates the blind spots agents might leave.

Embed cost optimization in engineering workflows
The most successful cloud cost optimization programs are proactive, not reactive. Embed cost awareness directly into your daily engineering workflows by shifting left:
Surface cost impact in CI/CD: Leverage tools to estimate the cost impact of infrastructure changes within a pull request, providing engineers with immediate feedback.
Define policy as code (PaC): Use policies to enforce cost-saving rules automatically, like restricting expensive instance types in dev environments.
Use real-time alerts: Automatically send cost and usage alerts with tools like Slack to notify the right team about anomalies as they happen.
Integrate cost visibility into developer portals: Empower developers by showing them the costs of the services they own directly in their internal dashboards.


Tools for EKS cost monitoring & optimization
A wide array of tools can help you implement the best practices we’ve covered. They generally fall into three categories: AWS native tools, Kubernetes cost optimization tools, and cloud cost management and optimization solutions:
AWS native tools (Cost Explorer, Compute Optimizer)
What they offer: First-party billing visibility and rightsizing signals across EC2, EBS, and Elastic Load Balancing (ALB/NLB)
Where they shine: Trend lines, Savings Plans/RI planning, instance recommendations, high-level anomaly checks
Kubernetes cost optimization tools (Kubecost)
What it offers: In-cluster allocation and showback down to cluster, namespace, deployment, and pod
Where it shines: Requests vs. usage right-sizing, spot vs. on-demand mix visibility, budgets, forecasts, and alerts
Cloud cost management & optimization solutions (Wiz)
What it offers: Code-to-cloud context that ties spend to services, owners, and risk
Where it shines: Surfacing orphaned EBS and ALB/NLB, idle or unsupported EKS clusters, and publicly exposed workloads; prioritizing where cost and risk intersect
Remember: It's crucial to select tools that not only report on costs but also provide engineers with the necessary context to take action.


From cost to context: Actionable EKS optimization with Wiz
Wiz provides the crucial context you need to start optimizing with confidence. It transforms a flat financial problem into a prioritized action plan for FinOps and engineering teams.
Here's how Wiz delivers the context that matters:
The Wiz Security Graph: At its core, Wiz maps every resource, identity, vulnerability, and network path in your cloud. This enables it to identify the complex relationships between resources and all their associated costs, risks, and configurations that other tools overlook.
Correlation of cost with actionable risk: Wiz moves beyond simple cost reporting by highlighting the "toxic combinations" that create both financial waste and security threats, enabling risk-prioritized remediation:
Instantly see if an expensive, over-provisioned cluster is also running an unsupported Kubernetes version with critical vulnerabilities.
Identify costly EBS volumes that are not only orphaned but also unencrypted and contain sensitive data.
Pinpoint publicly exposed workloads that are wasting money while also creating a significant security risk.
Clear ownership and accountability: Wiz cuts through the ambiguity of a single, cluster-level bill to show you exactly who is responsible for what:
Attribute costs to the specific microservice, application, and team owner, fostering greater accountability, similar to how leading cloud-native organizations use Wiz to allocate costs accurately.
Integrate cost and risk data directly into developer portals, empowering engineers to see the impact of their own services.
Wiz enables confident and prioritized decisions
With a comprehensive understanding of cost, risk, and ownership, you can make informed optimization decisions without compromising production. Wiz lets you…
Answer crucial questions instantly: Is this resource vital, or is it an insecure, abandoned workload we can safely decommission for an immediate cost and security win?
Focus on what matters most: Prioritize the cleanup of resources that represent the most significant financial drain and the highest security risk.
Act faster: By transforming a financial issue into a straightforward engineering and security task, the right teams can take immediate, informed action.
Discover how Wiz’s agentless code‑to‑cloud visibility and risk‑prioritized remediation can empower your teams to optimize spend with confidence: Request a demo today and gain the context that truly matters for your EKS environments.
Agentless Full Stack coverage of your AWS Workloads in minutes
Learn why CISOs at the fastest growing companies choose Wiz to help secure their AWS environments.
