



Amazon S3 powers everything from backups to big data pipelines — but without visibility into usage patterns and ownership, costs can creep up fast. Even worse, stale or unowned data often hides security and compliance risks. By aligning storage decisions with access patterns, retention needs, and data sensitivity, you can cut spend and strengthen your security posture.
In this article, you’ll learn more about these cost drivers and find actionable strategies for addressing each one. Ready to make the most of S3 without sticker shock when your bill arrives? Let’s get started.
S3 Security Best Practices [Cheat Sheet]
In this 15-page cheat sheet, we'll cover best practices in the following areas of AWS S3: Access control, Data durability, Storage visibility, Data loss prevention, including how to implement Multi-Factor Authentication (MFA) as an additional layer of security, and making use of S3's security features to protect your data.

Key S3 cost drivers
How S3 costs are calculated
Amazon S3 pricing is based on several usage dimensions, with your monthly bill adding up from all of them:
Storage – Charged per GB per month based on the storage class (e.g., S3 Standard, IA, Glacier tiers) and the amount of data stored.
Requests and retrievals – Fees for operations like PUT, GET, COPY, and LIST, plus retrieval charges for infrequent access or archival classes.
Data transfer – Outbound data to the internet or between AWS regions incurs transfer charges. Intra-region transfers are typically free.
Additional features – Costs for object versioning, replication, tagging, batch operations, analytics, and monitoring (e.g., S3 Storage Lens).
Formula: S3 monthly cost ≈ (Storage amount × Class rate) + (Requests × Request rate) + (Data transfer × Transfer rate) + (Optional feature charges)
Storage classes
In Amazon S3, storage classes define how your data is stored, accessed, and priced, with each class tailored to specific access patterns and durability requirements. For example…
S3 Standard is a higher-priced storage class that’s designed for frequently accessed data.
Standard-IA and One Zone-IA are cheaper alternatives to S3 Standard that are optimized for infrequent access, with the latter storing data in a single availability zone.
Glacier classes, including Instant Retrieval, Flexible Retrieval, and Deep Archive, are designed for rarely used or archived data, with increasing retrieval times and lower storage costs, as well as minimum retention periods.
Object size and duration
S3 charges factor in how much data you store and for how long:
Object size and quantity: Storing a million 1 KB files costs a different amount than storing one 1 GB file does, especially when accounting for request and metadata expenses.
Storage duration: S3 costs are incurred per GB per month. The bills you pay are directly proportional to storage duration.
Here’s an example: Archiving 2 TB of logs for a year in S3 Standard will be significantly more expensive than moving them to a Glacier storage class after 30 days. The bottom line? Achieving S3 cloud cost savings requires optimizing not just what you store but for how long and in what form.

Requests and API access
The number and type of requests made of your data are a big component of your S3 bill. (Think operations like PUT, GET, LIST, COPY, and POST.) DELETE and CANCEL requests are free of charge.
When retrieving data from storage classes such as S3 Standard-Infrequent Access, One Zone-IA, or Glacier Instant Retrieval, additional retrieval fees apply. For archives stored in Glacier Flexible Retrieval or Deep Archive, costs are incurred both for the restore request and for temporarily storing the retrieved copy in S3 Standard.
Data transfer
Transferring data out from S3 to the internet and/or other AWS regions incurs data transfer charges, which can substantially increase your S3 expenditure. The best way to optimize? Proper storage class allocation planning in combination with lifecycle management.
S3 doesn’t charge for data ingress, transferring data between S3 buckets in the same AWS region, or transferring data to AWS services within the same AWS region.
Object versioning and replication
Amazon S3 offers two replication options: Same-Region Replication (SRR) and Cross-Region Replication (CRR). With SRR, you incur charges for the storage of both the primary and replicated copies, replication-related PUT requests, and any infrequent access storage used. CRR includes these same costs, along with additional inter-region data transfer fees. If you enable S3 Replication Time Control for predictable replication latency, you'll also be billed for Replication Time Control data transfer and associated replication metrics.
Keep in mind that replicating or versioning data in Amazon S3 increases storage usage and can significantly raise costs over time, especially if done without a clear business or operational need.
S3 management and analytics costs
Additional costs may apply when using S3 metadata features and analytics tools. Specifically:
Object tagging: You are charged per 10,000 tags applied to objects.
Batch operations: Costs include processing tasks, associated requests, data transfer, and any resulting replication charges.
S3 Storage Lens: Priced per million objects per month monitored. Discounts are applied to the total quantity of objects monitored.
Storage Class Analysis: Additional charges apply for analyzing storage patterns and access frequency.
Best practices for S3 cost optimization
These strategies help you match storage to actual usage patterns, avoid paying for performance you don’t need, and reduce the risk of sensitive data lingering in costly storage.
1. Select the right storage class
Selecting the right storage class for each data type adds up to huge savings.
Frequently accessed data: S3 Standard is the best choice for frequently accessed data. For the most latency-sensitive applications, consider S3 Express One Zone, which is optimized for fast access and has single availability zone redundancy.
Infrequently accessed data: S3 Standard-IA or S3 One Zone-IA storage classes are great options for storing backups or older data that still requires relatively fast access.
Rarely accessed data: Use S3 Glacier Instant Retrieval and S3 Glacier Flexible retrieval for data that’s accessed rarely but still requires fairly fast access if needed. Put data into S3 Glacier Deep Archive only if it doesn’t require real-time access.
Avoid minimum duration charges
Remember that the majority of low-cost storage classes have a minimum duration policy. That means if a storage class has a 90-day minimum storage rule, you pay a full 90-day fee even if you choose to delete the data after 30 days.
S3 Glacier Instant and S3 Glacier Flexible Retrieval require a minimum storage duration of 90 days; for S3 Glacier Deep Archive it’s 180 days. In other words, plan the duration needed for your data carefully before putting it into any particular storage class.
2. Enable objects lifecycle management
S3 lifecycle policies enable the cost-effective storage of objects in S3 buckets by transitioning them to lower-cost storage tiers when appropriate and deleting expired objects. Lifecycle policies can—and should!—be applied to logs, digital media, compliance documents, and document versions.
Lifecycle configuration is composed of a set of actions on a group of stored objects. Two types of actions that are supported are…
Transition actions: You can tell S3 when to transition objects to another storage class. For example, you may decide to transition your S3 Standard buckets to S3 Standard-IA class 30 days after creating them, or you might want to archive objects after one year. This is a very useful cost automation feature because you don’t need to track the movement of objects manually.
Expiration actions: Expiration actions help you streamline your storage. For example, you can choose to delete objects after a regulatory compliance period has passed.


3. Control data transfer costs
Minimize cross-region data transfer. Whenever possible, keep data processing and storage within the same region to avoid inter-region transfer charges.
Avoid unnecessary data egress. Unnecessary data transfer to the public internet can be avoided by processing data within AWS whenever possible and caching data closer to users using services like Amazon CloudFront.
Use S3 Multi-Region Access Points wisely. Multi-Region Access Points make data access faster, but they involve additional data routing costs for each GB processed, plus standard charges for requests, data transfer, and replication.
4. Create a strategy for data replication
As we’ve seen, replication (SRR and CRR) can be a pain point on your S3 bills. To control costs, follow these best practices:
Replicate granularly: Only replicate data that truly requires redundancy (e.g., compliance data or frequently accessed global content).
Choose Same-Region Replication (SRR) whenever possible: SRR lets you avoid inter-region data transfer fees, making it more cost-effective than CRR.
Use Cross-Region Replication (CRR) strategically: Make sure that only target objects/buckets are replicated by filtering based on prefix and tags. Run regular monitoring checks to make sure only necessary objects are replicated.
Use Replication Time Control (RTC) wisely: S3 Replication Time Control makes sure that newly uploaded S3 objects are replicated quickly and predictably. Use this feature only for workloads that require guaranteed replication and for which you have strict compliance and SLA requirements.
5. Establish ownership and data sensitivity for S3 buckets through tagging
Without clear ownership, purpose, and sensitivity classification of your data, it's difficult to apply effective cost optimization strategies. For instance, archiving sensitive data that must be retained for compliance could lower costs, but doing so prematurely may violate compliance regulations. That’s why establishing ownership and data sensitivity through meaningful tags is so important. Tagging gives teams the information they need for efficient storage usage and effective decisions about data retention, replication, and class transitions.
Depending on your organization’s requirements, you can apply tags related to the…
Application: Identify which application or service the data supports.
Environment: Distinguish between dev, test, and production environments to tailor cost policies accordingly.
Data sensitivity: Flag data for compliance, encryption, or restricted access.
Owner/team: Assign clear ownership so that each team can monitor and manage their own costs.
Recommendations:
Integrate tagging into your CI/CD pipelines and enforce it using AWS service control policies (SCPs).
Enable team-level cost visibility. Create per-team dashboards based on data tags so that teams understand the effect of their data governance strategies/policies.
Watch 12-minute demo
Learn what makes Wiz the platform to enable your cloud security operation

Tools to support S3 cost optimization
From AWS-native capabilities to third-party FinOps platforms, the right tools give you visibility into spend, automate cost-saving actions, and surface the riskiest and most expensive storage first.
AWS native tools
AWS S3 Storage Lens
AWS S3 Storage Lens is a powerful S3 monitoring solution that helps analyze storage usage patterns and trends. Here are some key features that can help you optimize S3 costs:
60+ metrics related to usage patterns, with insights into historical trends spanning 15 months
Interactive dashboards with pre-configured views, covering 14 days of historical data
Actionable recommendations for cost optimization and data protection best practices
Analytics insights, which export to various formats such as CSV and Parquet for further analysis
Prefix aggregation for tracking usage patterns on the prefix level; facilitates finding the fastest-growing prefixes within a bucket
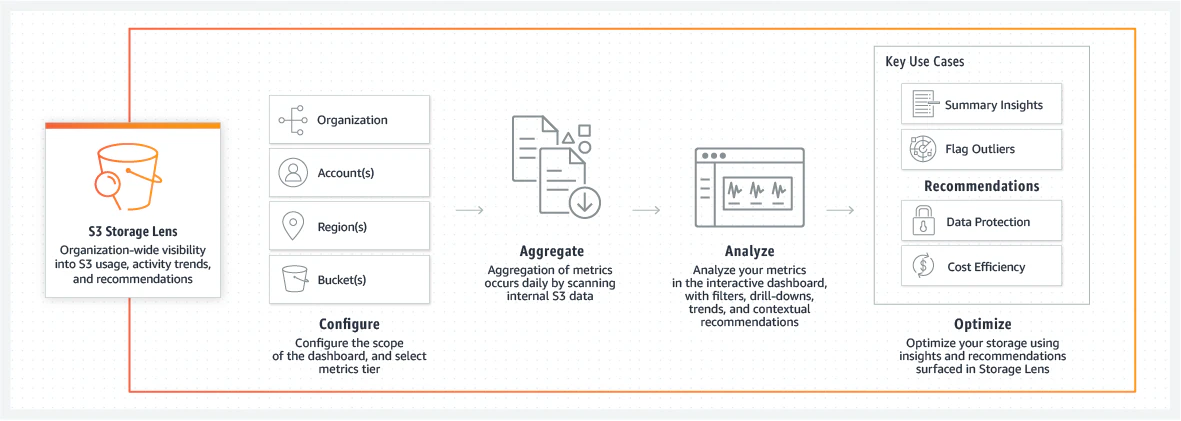
These features lead to cost savings by…
Pinpointing buckets with incomplete downloads
Locating buckets with a lot of old and stale data versions
Identifying buckets without lifecycle rules
Cost Explorer and detailed billing reports: High-level spend tracking
AWS Cost Explorer offers a generic picture of your AWS expenses but also allows access to rich filtering by AWS service, usage type, region, operation, and more. One advantage of this tool is that you can limit your query to S3 and see its cost breakdown by month, region, account, and other filters to identify trends.
You can save the resulting S3 cost reports as PDFs and share them with your team for further analysis. On top of that, you can use the AWS Cost Anomaly detection tool to check if there’s any unusual spending associated with your S3 service.
More detailed information about your S3 costs may be found in AWS usage reports. When generating these reports, you can specify the time period, operation type, usage type, and aggregation parameters to display. The generated report will contain a list of various operations on your S3 buckets (such as GET and PUT), as well as the cost and a corresponding timestamp.
AWS Storage Class Analysis
Like AWS Storage Lens, AWS Storage Class Analysis helps identify data with infrequent access patterns, making it easier to decide when to transition objects to lower-cost storage classes. Specifically, SCA provides recommendations for transitioning between S3 Standard and Standard-IA based on usage patterns. In addition, you can filter data by tags and prefixes and group objects together for analysis.
Engineering-centric or FinOps platforms
While AWS native tools provide useful insights for S3 cost optimization, third-party platforms offer some useful additional features. Specifically, they link S3 usage to data ownership and context, provide anomaly detection functionality, and help you understand costs in relation to data sensitivity, infrastructure, and data governance.
Third-party tools support service-ownership correlation through:
Service ownership mapping: These tools link S3 resources to internal teams or services to support accountability and internal cost allocation.
Context-aware filtering: Analyze S3 costs by customer, product, team, or component to align usage with business value.
For anomaly detection and monitoring, these platforms typically provide:
Real-time cost alerts to notify teams of unexpected spikes in S3 usage or spend
AI/ML-based anomaly detection to uncover unusual patterns and suggest optimization opportunities
Many third-party tools also offer additional cost management features, including:
Impact forecasting to estimate how new features, deployments, or updates may affect S3 costs
Optimization recommendations to suggest data tiering, lifecycle policies, or deletions based on actual usage trends.
Graph-based insight platforms
Platforms like Wiz take optimization a step further by combining billing data with architectural, data exposure, and security context. By modeling your cloud environment as an interconnected graph, Wiz provides a holistic view of how S3 usage relates to data sensitivity, application structure, and potential risk. The result? Smarter, risk-aware cost decisions.


Automating S3 cost optimization
Automation is not merely a cost optimization strategy; it's essential for preventing data mismanagement, human error, and the unnecessary expenses that stem from manual data handling. In Amazon S3, automation can be achieved through a combination of Intelligent-Tiering, lifecycle policies, and proactive alerting.
Enable Intelligent-Tiering for unpredictable workloads
Sometimes you don’t know how often particular data will be accessed. For these scenarios, S3 offers Intelligent-Tiering, which automatically moves data to the most cost-effective storage class based on data access pattern changes, without any operational overhead. This storage class is especially useful for user-generated data, logs, and backups whose access behavior isn’t clear upfront.
Define lifecycle policies as code
Given the volume of data and the frequency of tiering transitions required, manually assigning lifecycle policies simply isn’t practical. A more scalable and sustainable approach is to treat lifecycle policies as reproducible configurations defined, versioned, and automatically applied to S3 objects at creation.
This can be achieved using infrastructure-as-code (IaC) tools like AWS CloudFormation or Terraform, which allow you to:
Define automatic expiration and transition rules
Manage lifecycle configurations consistently across data types, environments, and teams
The key advantages of this approach include scalability, reproducibility, maintainability, reduced human error, and stronger alignment with data lifecycle governance and compliance requirements.
Set up smart alerts for S3 anomalies and trends
Setting up automated S3 alerts helps identify cost risks before they escalate. Consider having alerts for the following cases:
High-growth buckets. Trigger alerts when storage writes and/or data requests have sudden spikes. These events may indicate potential cloud waste or data ingestion issues.
Buckets without lifecycle policies. Send alerts when buckets are lacking lifecycle rules or have misconfigured tags, prefixes, etc. This provides an opportunity for cost optimization and signals possible misconfiguration of your automated cost optimization pipeline.
High egress buckets. Monitor egress traffic to flag anomalous high data-transfer costs, especially across regions or to the internet.
When applied together, the automation strategies discussed above decrease cost leakages, let you leverage emerging cost-reduction opportunities, and allow S3 usage to adapt to data behavior in real time.
Wiz integrates with AWS Security Hub to help you better manage your AWS security posture
Read more

The link between S3 cost optimization and data risk
Runaway S3 bills aren’t always just a budgeting problem – they’re often a signal of weak data governance. Stale, unowned, or poorly classified data can linger for years, quietly driving up costs while increasing your attack surface.
For example, a bucket containing terabytes of untagged, publicly accessible files could cost thousands of dollars a month to store. Beyond the waste, it might expose sensitive data in violation of compliance requirements.
Optimizing S3 spend should therefore go hand in hand with improving security and compliance. That means:
Establishing ownership and classification so teams can make informed retention and replication decisions.
Eliminating unneeded data to reduce both storage costs and potential exposure.
Aligning lifecycle policies with security requirements to ensure sensitive data is retained or destroyed according to compliance mandates.
The most effective way to do this is to combine cost visibility with context about data sensitivity and exposure. Wiz Cloud Cost brings granular spend and usage data into the Wiz Security Graph, so you can quickly pinpoint high-cost, high-risk storage, see which team owns it, and act on savings opportunities without compromising security.
That shared context becomes even more useful as S3 increasingly backs AI datasets, model artifacts, and inference logs alongside traditional backups and application data. When cost, ownership, sensitivity, and exposure are visible together, teams can clean up stale or duplicate objects, tune lifecycle and versioning policies, and reduce spend without creating new security or compliance gaps.
Looking for a tool that correlates exposure, sensitivity, and cost in one view? Book a demo of Wiz today, and see how easy cost optimization can be when you have all the context you need at your fingertips.
Agentless Full Stack coverage of your AWS Workloads in minutes
Learn why CISOs at the fastest growing companies choose Wiz to help secure their AWS environments.
