What is data leakage?
Data leakage is the unintentional exposure of sensitive information to unauthorized parties. Unlike a data breach involving deliberate, unauthorized access by external attackers, data leakage typically results from internal errors such as misconfigured storage buckets, overpermissioned identities, and human error. The distinction matters because leakage often goes undetected for months, while breaches usually trigger immediate alerts. Left unaddressed, leakage often escalates into a full breach once attackers discover the exposed data.
While leakage can stem from malicious activity, like insider threats or targeted phishing campaigns, accidental errors dominate real-world incidents.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

The rising threat of data leakage in machine learning (ML)
Organizations deploying AI models face traditional data exposure alongside ML pipeline contamination. In ML, data leakage occurs when information unavailable at prediction time contaminates the training process. Leaked data creates models that perform well during development but fail in production because they learned patterns they shouldn’t have.
A common example is calculating normalization statistics across the entire dataset before splitting it into training and test sets, which allows future information to influence past predictions. A model trained on leaked data can produce unreliable outputs that drive flawed business decisions.
The two most common forms of ML data leakage are target leakage and train-test contamination. Both create models that appear accurate during evaluation but underperform in production. Understanding the difference helps teams identify which safeguards to implement at each stage of the ML pipeline.
Types and examples of data leakage in machine learning
Data leakage occurs when information unavailable at prediction time contaminates a machine learning model’s training, leading to overly optimistic performance and poor generalization.
Target leakage: Training data includes features that reveal the target label, even indirectly. Accessing such features gives the model access to future information it would not have in production. Example: Including “payment status” when predicting loan default.
Train-test contamination: Test data influences the training process due to improper splitting—often appearing as repeated subject leakage—which inflates performance metrics and masks real-world accuracy gaps. Example: Randomly splitting time-series data, allowing future values into the training set.
Preprocessing leakage: Transformations like scaling or imputation apply before splitting the data. Statistical properties from the test set then influence training. Example: Normalizing the full dataset before splitting.
Feature leakage: Engineered features use information unavailable at prediction time, including temporal data from future events. Example: Creating “average spend over the past year” using transactions that occur after the prediction date.
Common causes of data leakage
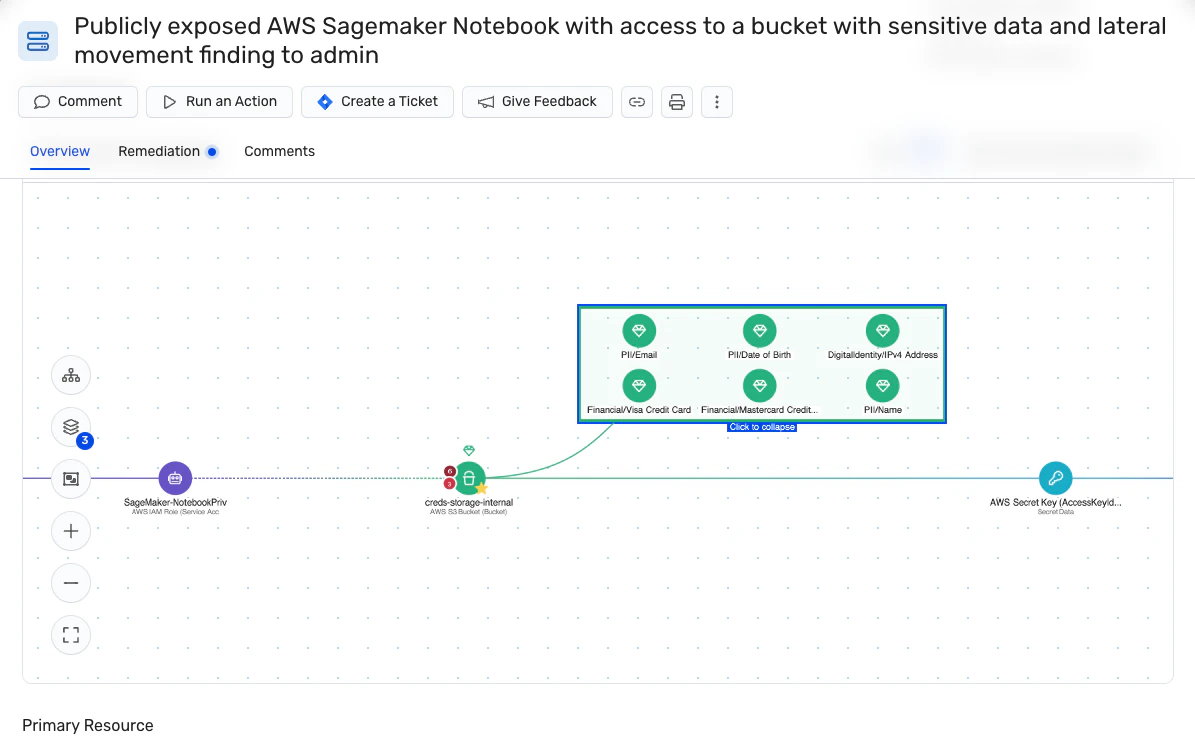
Cloud environments introduce data leakage risks that traditional security tools often miss. The Wiz 2025 State of Code Security Report found that 61% of organizations have secrets exposed in public repositories. The causes below recur in real-world incidents, and they often compound, pairing a misconfigured storage bucket with overpermissioned access, for example, creates a direct exposure path.
| Data leakage risk | How it leads to data exposure |
|---|---|
| Misconfigured cloud storage | Publicly accessible S3 buckets or Blob storage expose sensitive data to the internet. |
| Over-permissioned identities | Excessive access enables lateral movement and large-scale data exfiltration if credentials are compromised. |
| Hardcoded secrets and credentials | API keys and secrets in code repositories provide direct access to systems and sensitive data. |
| Missing encryption controls | Unencrypted data at rest or in transit can be intercepted or accessed without authorization. |
| Shadow data and unmanaged assets | Untracked databases and storage increase attack surface and leave sensitive data unprotected. |
| Publicly exposed services and APIs | Missing authentication or access controls allow attackers to directly retrieve sensitive data. |
| Third-party and supply chain risks | Weak vendor security practices create indirect paths for data leakage. |
| Insecure AI and ML pipelines | Poorly secured datasets, notebooks, and models expose sensitive data and embedded credentials. |
How to prevent data leakage
Preventing data leakage requires a layered approach that spans data handling, model training, deployment, and organizational practices. The following sections break down the key safeguards you can put in place.
1. Data preprocessing and sanitization
Effective data preprocessing in cloud-native environments requires automated scanning of storage buckets to identify sensitive data before it enters the ML pipeline. Hardening this initial handling phase prevents sensitive information from ever reaching your models.
Anonymization alters or removes PII to prevent re-identification, while redaction specifically obscures sensitive values like credit card numbers and addresses. Without these controls, AI models can memorize sensitive training data and reproduce it in their outputs, posing a serious risk for public-facing applications.
Best practices:
Use tokenization, hashing, or encryption techniques to anonymize data.
Permanently remove redacted data from both structured and unstructured datasets before training.
Implement differential privacy to further reduce the risk of individual data exposure.
Data minimization focuses on collecting and using only the minimum dataset to achieve AI model objectives. Limiting data collection shrinks the risk surface for breaches and lowers the likelihood of exposing sensitive information.
Using only necessary data also ensures compliance with privacy regulations like GDPR and CCPA. Cloud environments benefit from automated discovery tools that identify and flag redundant or shadow datasets before they enter the training pipeline.
Best practices:
Audit data points to assess which are essential for training.
Implement policies to discard non-essential data early in the preprocessing pipeline.
Review the data collection process regularly to ensure teams avoid retaining unnecessary data.
Data Governance & Compliance Guide
Data governance and compliance are central to the DSO mandate.

2. Model training safeguards
Secure model training requires isolating environments within dedicated VPCs to prevent lateral movement if a model becomes compromised. The following techniques harden the development phase.
Data splitting separates the dataset into training, validation, and test sets. The training set trains the model, while the validation and test sets assess accuracy without overfitting.
If you improperly split the data (e.g., including the same data in both training and test sets), the model can “memorize” the test set. Memorization leads to overestimated performance and risks of exposing sensitive information during training and prediction phases. Automated cloud training pipelines should verify data splits during ingestion to prevent cross-contamination between sets.
Best practices:
Randomize datasets during splitting to ensure no overlap between the training, validation, and test sets.
Use techniques like k-fold cross-validation to robustly assess model performance without data leakage.
Regularization techniques prevent overfitting, which occurs when the model becomes overly specific to the training data and memorizes details rather than learning general patterns. Overfitting increases the likelihood of data leakage because the model can reproduce sensitive information from the training data during inference.
Best practices:
Randomly drop certain units from the neural network during training, forcing the model to generalize patterns.
Penalize large weights during training to prevent the model from fitting too closely to the training data.
Monitor model performance on a validation set and stop training when performance starts to degrade due to overfitting.
Differential privacy adds controlled noise to data or model outputs, making it difficult for attackers to infer information about any individual data point.
Applying differential privacy makes AI models less likely to leak details of specific individuals during training or prediction. Many cloud-native AI platforms now include built-in differential privacy modules to simplify the protection of individual records, which adds a layer of protection against adversarial attacks and unintended data leakage.
Best practices:
Add Gaussian or Laplace noise to training data, model gradients, and final predictions to obscure individual data contributions.
Use frameworks like TensorFlow Privacy or PySyft to apply differential privacy in practice.
3. Secure model deployment
Organizations must harden the deployment environment to prevent unauthorized access to live models and data. Monitoring cloud-native API for unexpected egress patterns catches leakage from live model endpoints in real time. The following steps secure the inference phase.
Tenant isolation creates logical or physical boundaries between tenants in multi-tenant environments. Isolating each tenant’s data prevents unauthorized access, protects sensitive information, and reduces the risk of data breaches. Securing each environment protects sensitive AI training data from potential leaks, and maintaining compliance with data protection regulations gets much easier once these safeguards are in place.
Best practices:
Use virtualization techniques like containers or virtual machines (VMs) to ensure each tenant's data and processing are isolated from one another.
Implement strict access control policies to ensure each tenant accesses only their own data and resources.
Use tenant-specific encryption keys to further segregate data, ensuring that even if a breach occurs, data from other tenants remains secure.
Enforce resource limits and monitor for anomalous behavior to prevent tenants from exhausting shared resources.
Output sanitization involves implementing checks and filters on model outputs to prevent accidental exposure of sensitive data, especially in natural language processing (NLP) and generative models.
Sanitizing outputs ensures that even if a model encounters sensitive information during training, it won’t expose it.
Best practices:
Redact PII (e.g., email addresses, phone numbers) in model outputs using automated pattern-matching algorithms.
Set thresholds on probabilistic outputs to prevent a model from making overly confident predictions that could expose sensitive details.
4. Organizational practices
Building a secure culture requires establishing strong internal policies and training to ensure every team member understands their role in preventing leakage. The following practices standardize security across the organization.
Employee training ensures that everyone involved in the development, deployment, and maintenance of AI models understands the risks of data leakage and the mitigation strategies. Human error or oversight drives many breaches, but proper training can prevent accidental exposure of sensitive information or model vulnerabilities. Effective training programs highlight cloud-specific risks, like shadow data and hardcoded secrets in public repositories.
Best practices:
Provide regular cybersecurity and data privacy training for all employees handling AI models and sensitive data.
Update staff on emerging AI security risks and new preventive measures.
Data governance policies standardize how teams collect, process, store, and access data across the organization. Clear ownership and handling protocols reduce leakage risk while ensuring consistent security practices and compliance with regulations like GDPR and HIPAA. Leveraging cloud-native tagging automatically enforces data handling and encryption policies across multiple regions.
Best practices:
Define data ownership and establish clear protocols for handling sensitive data at every stage of AI development.
Review and update governance policies regularly to reflect new risks and regulatory requirements.
5. Leverage AI security posture management (AI-SPM) tools
Proactive security requires full visibility into the AI stack to identify and remediate risks before they lead to leakage. Integrating automated platforms ensures visibility across the ML lifecycle.
AI-SPM solutions provide visibility and control over critical components of AI security, including the data used for training and inference, model integrity, and access to deployed models. Incorporating an AI-SPM platform enables organizations to proactively manage the security posture of AI models to minimize the risk of data leakage and ensure robust AI system governance.
How AI-SPM helps prevent ML model leakage:
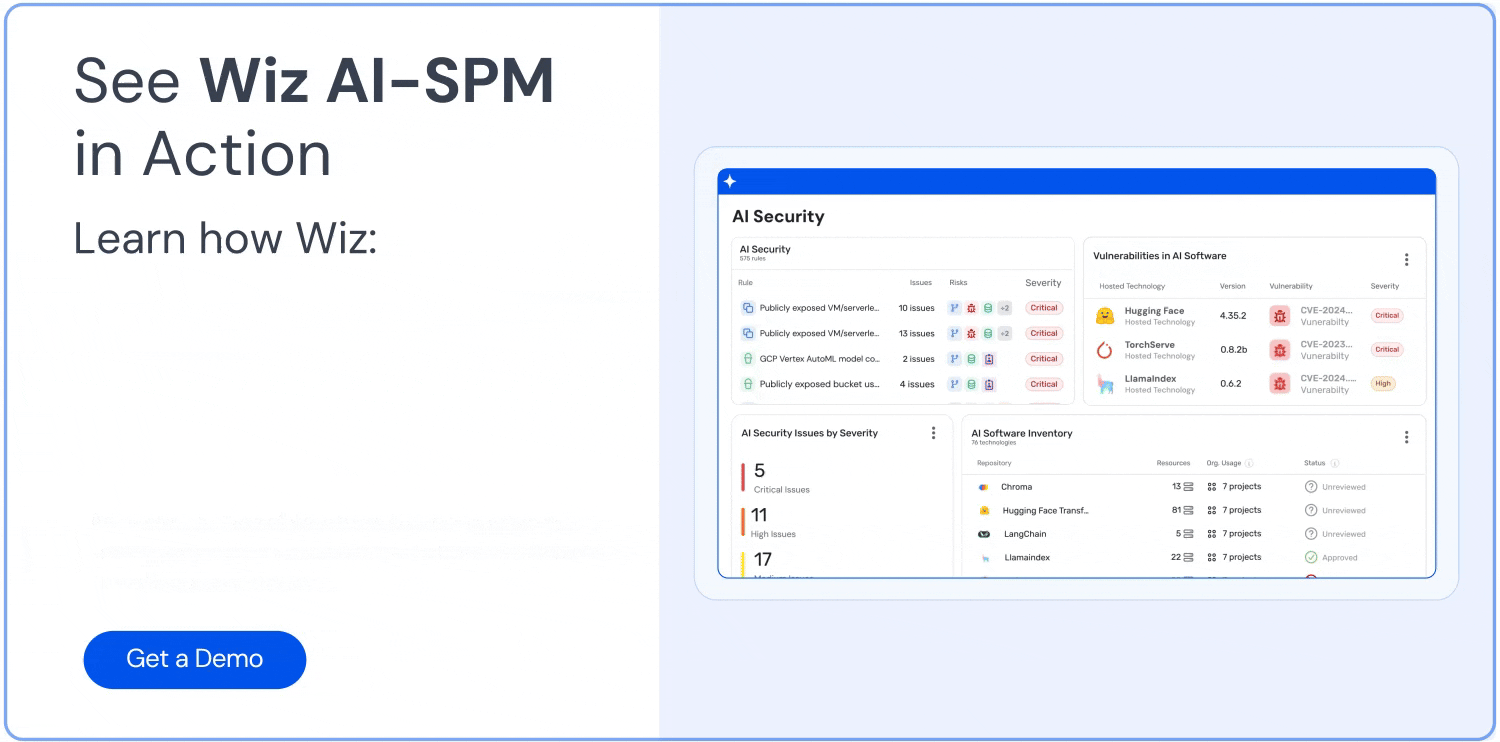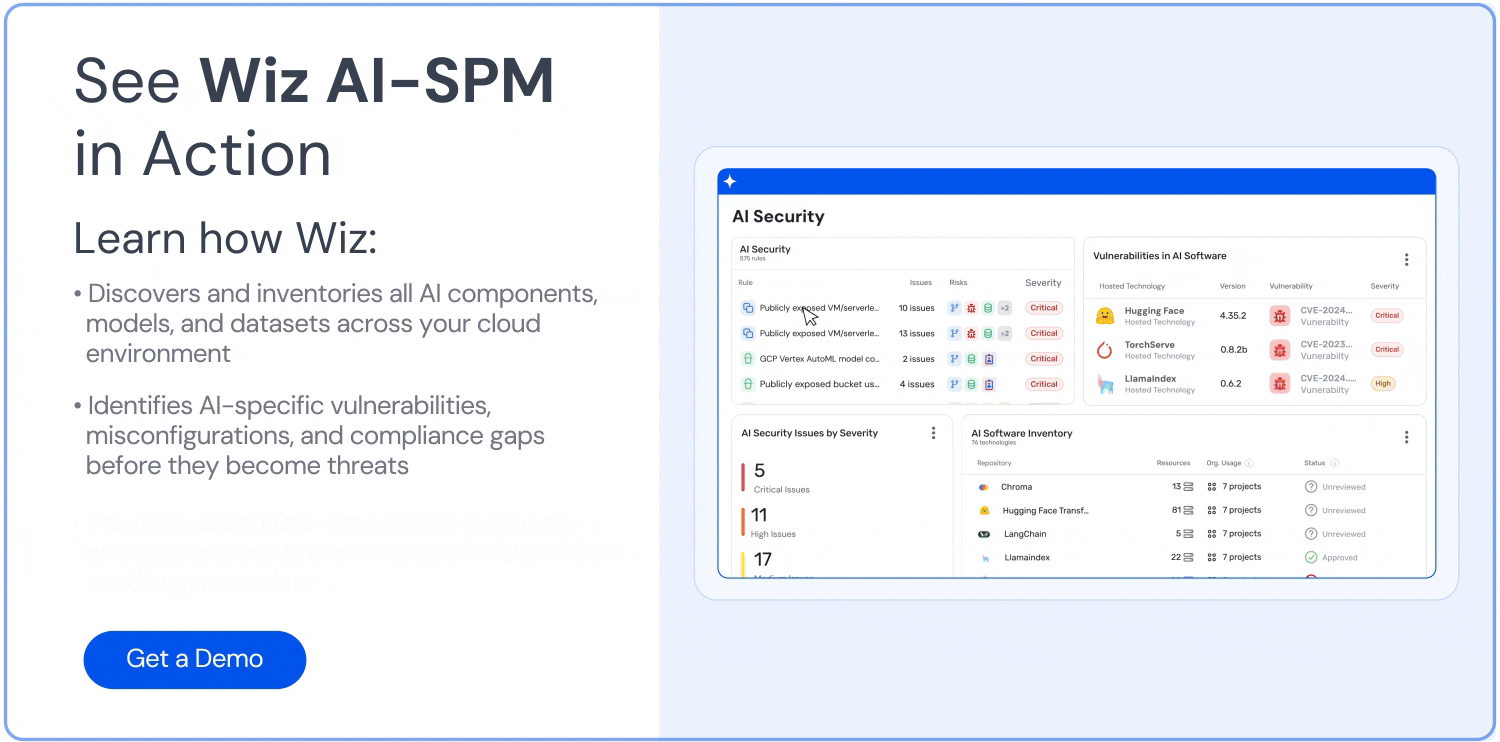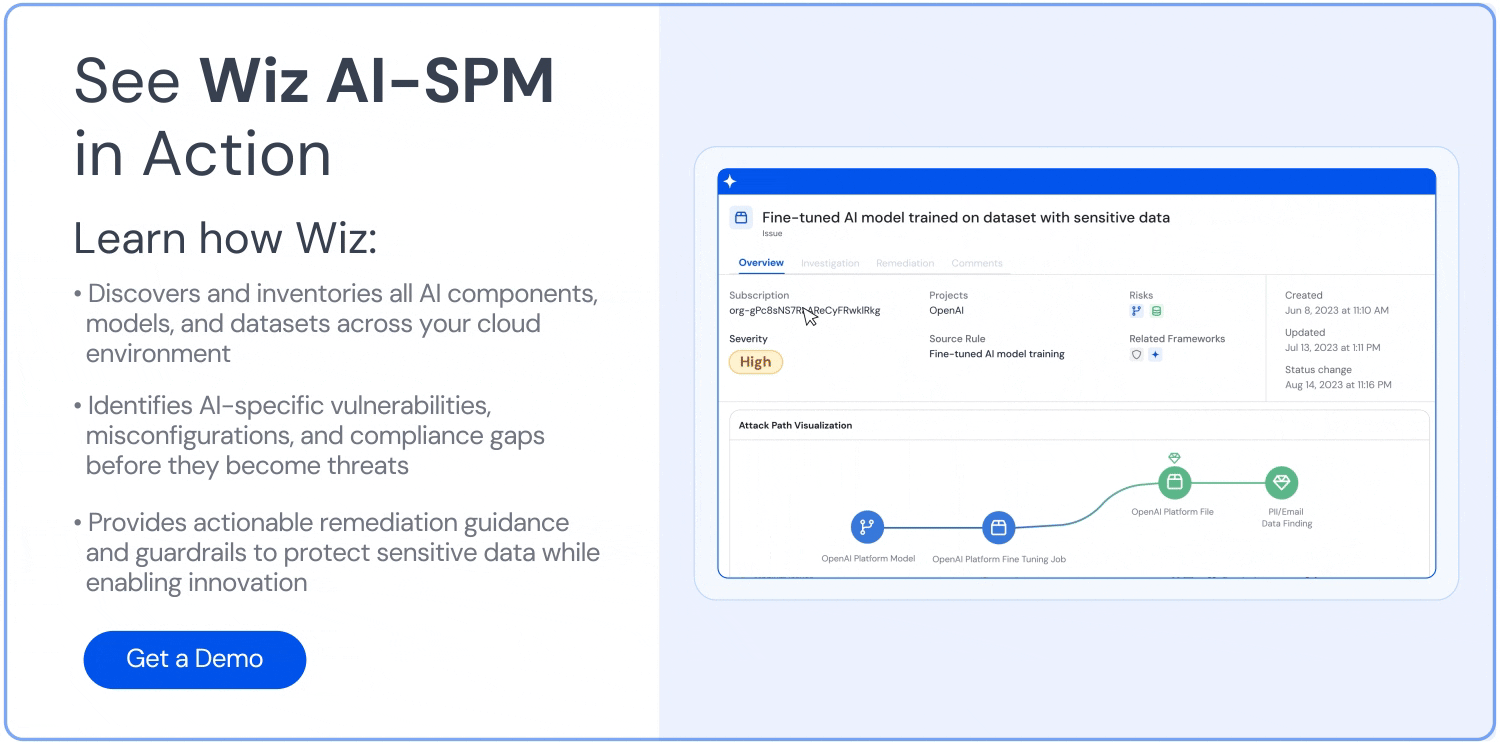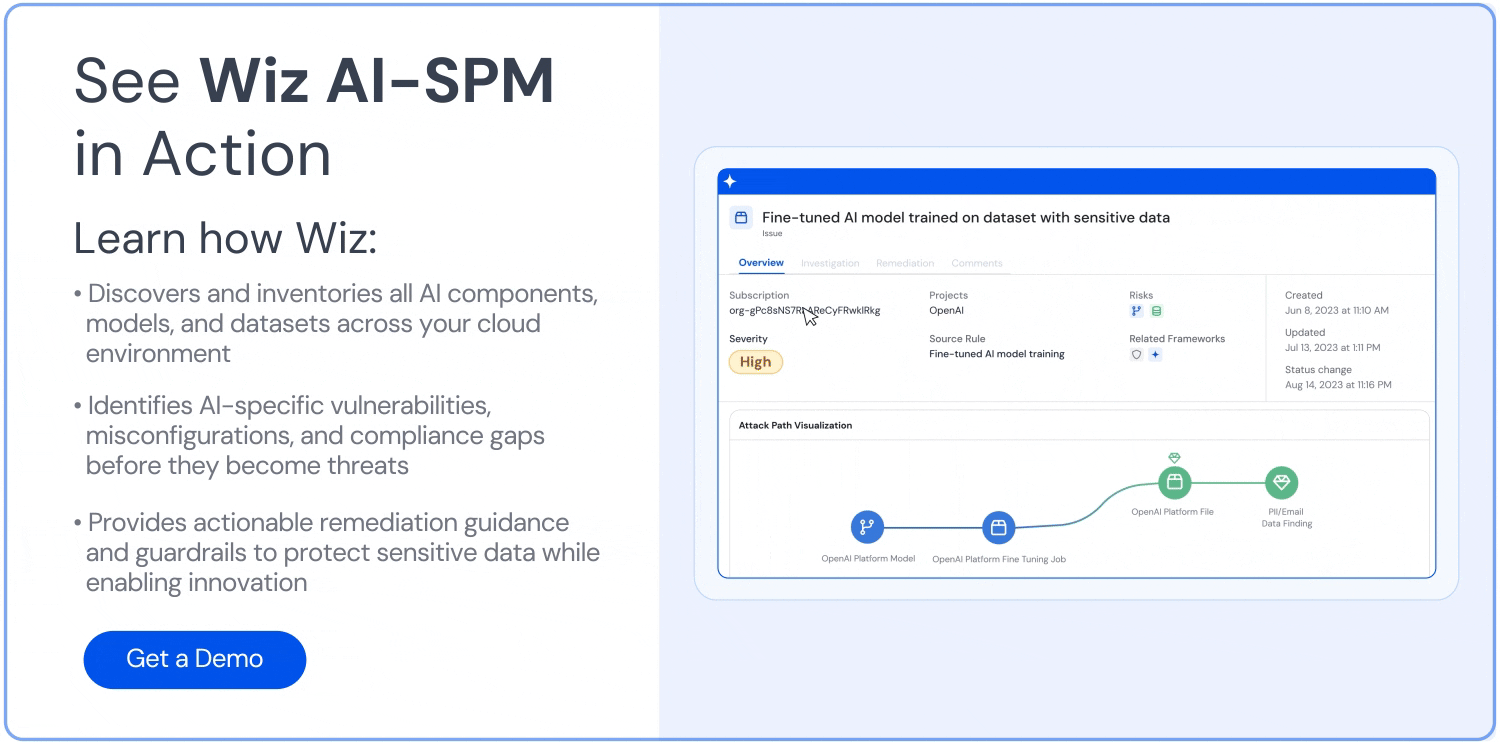
Discover and inventory all AI applications, models, and associated resources.
Identify vulnerabilities and misconfigurations in the AI supply chain that could lead to data leakage.
Monitor for sensitive data across the AI stack, including training data, libraries, APIs, and data pipelines.
Detect anomalies and potential data leakage in real-time.
Implement guardrails and security controls specific to AI systems.
Conduct regular audits and assessments of AI applications.
Preventing data leakage with Wiz
Cloud data leakage typically results from overlooked risks: exposed storage, overpermissioned identities, hardcoded secrets, and unmonitored shadow data. Adopting AI and scaling environments only compound these vulnerabilities.
Wiz DSPM continuously discovers and classifies sensitive data across cloud workloads, storage, and applications. The platform moves beyond simple visibility by mapping sensitive data to real exposure paths, showing when assets are publicly accessible, unencrypted, or connected to overpermissioned identities. Wiz also uncovers complex attack paths where lateral movement could reach critical datasets. Actionable context helps teams prioritize the exposures that actually put data at risk.
When organizations train and deploy AI models, Wiz extends protection directly to AI pipelines. Teams can automatically detect sensitive training data in cloud environments and flag leaks across services, APIs, and development workflows.
Get a demo to see how Wiz identifies exposure paths to sensitive data across your cloud environment.