

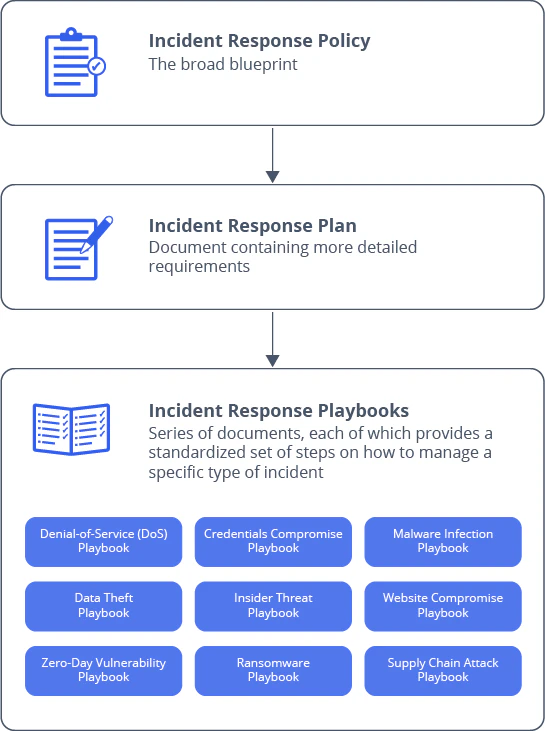
What is an incident response framework?
An incident response framework is a structured blueprint that guides organizations through security incidents before, during, and after they happen. It does so by defining step-by-step actions, assigning clear roles and responsibilities, and ensuring that teams respond swiftly and effectively to threats. Frameworks like the NIST Cybersecurity Framework and the SANS Institute's model follow a similar sequence of phases: preparation, detection, containment, eradication, and recovery.
In recent years, countless organizations have paid the price for lacking a formal incident response plan. From data breaches to eroded customer trust, the fallout is costly and often irreversible. But a plan alone isn’t enough. What many teams still miss is a modern, cloud-ready framework that integrates people, process, and technology. In today’s threat landscape, reactive and outdated approaches no longer work.
And the threat is escalating. Verizon’s 2025 Data Breach Investigations Report shows that exploitation of vulnerabilities to gain initial access and cause security breaches grew by 34% compared to last year's findings. With this persistent growth, having an incident response in place is critical when an attacker attempts to compromise your system.
But recognizing the importance of incident response, or even investing in it, isn’t enough. Without clear, standardized practices in place, those investments can fall flat.
Incident response frameworks play a critical role. They transform response plans into actionable, repeatable systems that teams can test and rely on. When implemented correctly, these frameworks enable your organization to scale, innovate, and embrace cloud technologies with speed and confidence.
How to Prepare for a Cloud Cyberattack: An Actionable Incident Response Plan Template
A quickstart guide to creating a robust incident response plan - designed specifically for companies with cloud-based deployments.

What issues do incident response frameworks mitigate?
Incident response frameworks exist to close the gaps that outdated plans can’t. They bring structure, speed, and consistency to security operations, especially when threats escalate fast, and mistakes are costly.
The most common risks an incident response framework mitigates include:
Weak incident response protocols: If a business’s playbooks, processes, or response capabilities fall short, its cloud environment becomes an easy target. Threats such as phishing, malware, ransomware, and supply chain attacks can exploit these gaps, leading to severe breaches and delayed recovery times.
Overwhelmed security teams: Without a clear, standardized response framework, internal teams and SOCs may misjudge risks, chase the wrong priorities, overlook critical vulnerabilities, or waste time on inefficient remediation efforts.
Disorganized cyber forensics: Effective incident response requires understanding how and why an attack occurred. But when response plans are fragmented or reactive, forensic teams struggle to pinpoint root causes, which makes repeat attacks more likely.
Inconsistent execution: Many businesses already use various incident response tools, protocols, and tactics. But when you don’t apply those methods consistently across environments or incidents, response efforts become disjointed, resulting in delays, errors, and greater long-term damage.
Imbalanced cybersecurity posture: Incident response is a foundational pillar of cybersecurity. Without a strong, well-defined plan, even the most advanced defenses can collapse under pressure.
Almost every other pillar of cybersecurity will lose potency if an enterprise’s incident response plan isn’t rock solid. By adopting an incident response framework, businesses can ensure that their cybersecurity capabilities are uniformly effective and mutually complementary.
Detect active cloud threats
Learn how Wiz Defend detects active threats using runtime signals and cloud context—so you can respond faster and with precision.

What are some popular incident response frameworks?
Several industry-standard frameworks exist to guide organizations in planning, executing, and improving their incident response. These models help establish clear workflows that reduce guesswork during a crisis and ensure your teams respond with speed and precision:
NIST CSF
The National Institute of Standards and Technology (NIST) Cybersecurity Framework (CSF) is a trusted source of cybersecurity best practices. NIST’s Information Technology Laboratory details its incident response framework in Special Publication 800-61, which defines four active phases in the incident response life cycle:
Preparation equips teams with the tools, processes, and protocols to prevent incidents and respond immediately when threats arise.
Detection and analysis rely on monitoring and analysis tools to uncover potential breaches, document events, and prioritize incidents by severity.
Containment, eradication, and recovery aim to limit damage, eliminate threats, gather forensic evidence, and restore operations.
Post-incident activity turns incident insights and forensic findings into actionable improvements that strengthen future defenses.
CSF 2.0 adds structure by organizing cybersecurity into six functions: Govern, Identify, Protect, Detect, Respond, and Recover.
While incident response efforts fall primarily under Respond and Recover, every phase should contribute to continuous improvement.
The SANS Institute’s incident response framework
Like NIST, the SANS Institute provides a diverse range of cybersecurity frameworks, resources, certifications, and training programs.
While the SANS incident response framework is similar to NIST’s in principle, it features a six-step cycle for incident response:
Preparation involves defining security policies, assembling incident response teams, and deploying the right tools and processes to detect and handle potential threats.
Identification focuses on detecting threats through continuous monitoring, raising internal awareness, and recognizing unusual traffic, behaviors, or system processes.
Containment involves stopping the spread by patching exploited vulnerabilities, assessing the impact, and isolating affected systems to prevent further damage.
Eradication targets the root cause by removing malware, restoring clean backups, and eliminating all traces of the threat.
Recovery returns systems to a known-good state. This phase emphasizes restoring normal operations, verifying system integrity, and documenting the recovery process.
Lessons learned turn incident data into strategic insights. The goal isn’t to assign blame but to refine processes, update documentation, and improve future response readiness.


CIS Controls
Unlike the NIST and SANS frameworks, which break down incident response into a four-step and six-step cycle, respectively, the CIS Critical Security Controls list incident response as one of 18 critical cybersecurity safeguards.
According to CIS Critical Security Control 17, the key aspects of a robust incident response include policies, plans, procedures, defined roles, training, and communications. A comprehensive incident response plan involves nine components:
Establish key cybersecurity personnel and incident responders to ensure the right experts are ready to act when threats emerge.
Manage the contact information of key stakeholders so teams can quickly notify the right people during an incident.
Implement a standardized incident reporting process to ensure consistency, traceability, and rapid triage across all incidents.
Establish and maintain a comprehensive incident response process that guides actions from detection through recovery.
Assign roles and responsibilities across IT, security, incident response, compliance, and HR teams to avoid confusion and ensure smooth collaboration.
Establish communication mechanisms and protocols for incident response to streamline coordination across internal and external stakeholders.
Plan and implement incident response simulations to prepare teams, test workflows, and identify gaps before a real threat strikes.
Conduct meticulous post-incident analyses and reviews to capture lessons learned and improve future response efforts.
Establish cyber incident thresholds for data breaches and privacy incidents to trigger appropriate escalation and compliance actions.
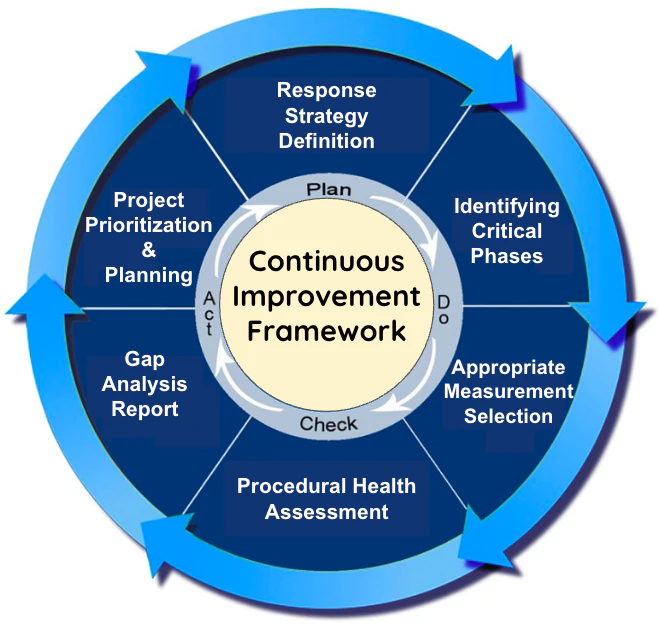
The Continuous Improvement Framework
Google’s Incident Response (IR) team created the Continuous Improvement Framework, and it puts a slightly different spin on other incident response resources and templates. This model focuses on continuous and constant optimization to ensure an enterprise’s cybersecurity capabilities are mature and always ready to respond to incidents.
Key aspects of the Continuous Improvement Framework include well-established escalation paths, updated incident response playbooks, the availability of security tools, strong stakeholder partnerships, and comprehensive root cause analyses.
This framework features the following five steps:
Response strategy includes cataloging response strategies for different types of cyber threats.
Critical phases involve framing critical incident response phases.
Measurements and metrics selection focuses on establishing data points and objectives to evaluate the success of each phase.
Procedural health assessment involves collaborating with the stewards or owners of each phase of incident response to evaluate the current state and identify gaps.
Gap analysis report and planning input include triaging gaps and weaknesses based on criticality and sharing information with key stakeholders.
How do you build an optimal incident response plan?
A strong incident response plan should evolve constantly, as cloud-native and hybrid environments change as fast as the threats that target them. That’s why you should treat IR not as a one-time project, but as a living framework. You must actively strengthen it with the right templates, sensors, automation, and regular drills. If you do, you’ll increase your speed, coverage, and confidence when incidents strike.
Here are a few ways you can build and improve your plan:
Choose the right incident response plan template
Incident response plan templates offer a proven structure, enabling you to respond quickly without missing critical components. To start, select a template that fits your environment. Templates provide a standardized structure, while frameworks ensure your templates are thoroughly tested. Here are a couple of examples for templates:
Wiz’s Quickstart Template for Cloud Incident Response provides defined roles, workflows, and escalation paths for cloud-native stacks.
NIST SP 800‑61 Rev. 3 is a federal standard for structuring IR phases across any organization.
When choosing a template, you should ensure that it meets the following criteria:
The plan defines the scope, purpose, and roles across IT, security, legal, and communications teams to ensure coordinated response efforts.
It covers the entire incident lifecycle, including detection, containment, eradication, recovery, and post-incident review.
The response prep outlines severity levels and escalation criteria to guide timely decision-making and ensure the right response for each incident.
It includes clear communication protocols and regulatory reporting requirements to maintain compliance and transparency.
The plan fits your organization’s size, risk profile, and environment, whether you operate in the cloud, on-premises, or in a hybrid setup.


Deploy sensors for proactive threat detection
Early detection prevents minor issues from escalating into major incidents, and sensors give you visibility into threats before they spread.
To build strong visibility and threat detection, your organization needs layered monitoring across your entire environment. The following components work together to uncover risks early, reduce false positives, and support a faster response:
| Component | Function |
|---|---|
| Runtime agents | Provide deep visibility into system-level behavior, helping detect real-time anomalies like process injection or suspicious script execution. |
| Host-level sensors | Monitor key operating system events to uncover unusual activity, such as privilege abuse or lateral movement. |
| Cloud workload monitors | Track the behavior of virtual machines, containers, and serverless functions to catch misconfigurations, excessive permissions, or unapproved changes. |
| Network traffic analyzers | Inspect east-west and north-south traffic for signs of command-and-control, data exfiltration, or internal reconnaissance. |
| Centralized threat engines | Collect and correlate sensor data to eliminate noise, prioritize real risks, and accelerate triage. |
| Integrated threat intelligence | Refine detection rules and enrich alerts to minimize false positives and increase detection accuracy. |
| IAM monitoring | Surface risky behaviors like unused credentials, privilege escalation attempts, and misconfigured identity policies across cloud services. |
| Cloud configuration checks | Identify outdated or insecure services, overexposed assets, and policy drift that can lead to exploitable gaps. |
Use Wiz’s runtime sensors to gain container-level visibility and execution context. When you combine this with automated alerting, you can detect and escalate real threats faster.
Automate triage with incident response playbooks
Triage is your control center. When it breaks down, so does your response. As a result, you should automate triage to classify and route incidents immediately. This frees up your team to focus on the most urgent threats.
Here’s what to include in automated triage:
Pre-defined workflows for phishing, malware, misconfigurations, or privilege misuse guide next steps, assign roles, and trigger alerts automatically. A phishing playbook, for example, might quarantine emails, alert users, and flag suspicious logins.
Severity scoring based on system sensitivity and blast radius prioritizes threats that impact critical assets, like customer data or production systems. Wiz uses contextual modeling to surface real risks through the Security Graph.
Integration with monitoring tools and cloud services allows triage to begin the moment detection occurs. Connect sources like IAM logs, workload monitors, and traffic analyzers to automate the response.
Filters and enrichment rules reduce noise and false positives by focusing on events with real impact. For example, they can correlate exposed workloads with leaked credentials or lateral movement paths.
These improvements cut response times, improve handoffs, and reduce team burnout.
Run coordinated remediation playbooks
Remediation only works if it’s precise. The wrong move can create more problems or delay recovery.
Here are some key elements of a strong and effective remediation plan:
Playbooks for common threats, like ransomware, credential theft, and lateral movement, to guide immediate next steps and reduce decision fatigue under pressure.
Containment strategies, like isolating workloads, revoking credentials, or terminating sessions, to stop active threats and prevent spread.
Automated actions such as patching, configuration rollback, or resource isolation to apply fixes quickly and without human error.
Cross-team coordination with security, engineering, legal, and communications to ensure efforts are aligned and compliant.
Built-in forensic data capture to support root-cause analysis and meet regulatory or audit requirements.
Use runbooks to coordinate containment, cleanup, and restoration across teams.
Test policy-as-code with live drills
Policy-as-code makes your response rules consistent and testable. But unless you drill those rules, you won’t know if they work.
To start improving your policy-as-code with drills, define your security and compliance policies as code, then test them in controlled environments.
Here’s why testing your policy-as-code should matter to you:
Policies behave the same across all environments.
You can catch failures in staging before they hit production.
You can create a clear audit trail showing which policies were in effect during incidents.
Here’s how to test policy-as-code:
Simulate incidents in staging or pre-prod to validate detection and response.
Run tabletop exercises with scenarios like policy conflicts or misconfigured rules.
Test failure paths, including misapplied policies or sensor chaining errors.
Use tools like Open Policy Agent, AWS Config, and CI/CD integrations to automate enforcement.
Use helpful templates to get started
No matter which framework an enterprise adopts, it serves only as a guide. To turn that guidance into action, organizations need a formal incident response policy and a clearly defined incident response plan. These documents translate framework principles into day-to-day security activities.
If you’re just getting started, templates can provide a strong foundation for your plan. Some useful options include the following templates:
NIST’s SP 800-61 Rev. 3
The United States Department of Homeland Security’s National Cyber Incident Response Plan
Carnegie Mellon University’s Computer Security Incident Response Plan
The University at Buffalo’s Information Security Incident Response Plan
The University of California, Berkeley’s Incident Response Plan
You can also use the 7 IR Plan Templates and Examples resource, which covers additional incident response templates from the California Government Department of Technology, the National Institutes of Health (NIH), and other reputable sources.
Tips for executive reporting to keep stakeholders informed
Strong executive reporting enables leadership to stay focused, make informed decisions, and respond with confidence during incidents. Below are some key tips for communicating with stakeholders.
Lead with business context: Focus on business impact, affected systems, and current resolution status. Also, avoid technical jargon unless it supports a decision.
Standardize your format: Use a consistent template for incident updates. A familiar structure reduces confusion and speeds up cross-team alignment. Each summary should fit on a single slide and clearly highlight the blast radius, business impact, and recommended next steps.
Automate where possible: Leverage cloud-native application protection platforms (CNAPPs), such as Wiz, to generate real-time incident summaries that include root cause, impacted assets, and remediation progress.
Include key metrics: Highlight severity, dwell time, time to respond, and any regulatory exposure. These are crucial for executive visibility and risk assessment.
Set a clear update cadence: Share updates regularly, such as hourly during critical incidents and daily for investigations, to keep leadership informed without follow-ups.
Book a Demo of Wiz Defend
Walk through how Wiz Defend helps your team detect threats faster, investigate with full cloud context, contain incidents with automated playbooks, and trace root cause back to code.
