

What is a CVE (Common Vulnerabilities and Exposures)?
A CVE, or Common Vulnerabilities and Exposures, is a standardized identifier used to reference a publicly disclosed security vulnerability. Its primary purpose is to ensure that everyone in the security ecosystem is talking about the same issue when a vulnerability is discovered.
Before CVEs existed, the same vulnerability might be described differently by vendors, researchers, and security tools. That made coordination difficult. It was not always clear whether two advisories referred to the same flaw or to different ones. CVEs solved this problem by introducing a single, shared naming system.
When a vulnerability is assigned a CVE, it means the issue has been acknowledged, documented, and made publicly referenceable. It does not mean the vulnerability is severe. It does not mean it is exploitable in every environment. And it does not mean it should be fixed immediately.
This distinction is critical. CVEs are designed to answer a narrow question: how do we consistently identify and track known vulnerabilities across products, vendors, and tools? They are not designed to answer broader questions about risk, impact, or prioritization.
In practice, CVEs function as the connective tissue of vulnerability management. Security scanners use CVE identifiers to report findings. Vendors use them in advisories and patch notes. Incident response teams use them to communicate about active threats. Without CVEs, this coordination would break down.
The CVE program itself is maintained by MITRE, which oversees how vulnerabilities are named, tracked, and published. That stewardship reinforces the role of CVEs as a neutral reference system rather than a risk assessment framework.
Understanding what a CVE is, and just as importantly what it is not, sets the foundation for effective vulnerability management. CVEs tell you what exists. Everything that follows is about determining what actually matters.
The Ultimate Vulnerability Management Playbook
Actionable steps to identify, assess, and mitigate AWS vulnerabilities, ensuring your cloud infrastructure is protected.
Get Cheat Sheet

What a CVE Actually Represents
A CVE represents a specific, publicly disclosed vulnerability in a defined product, version, or component. At its core, a CVE answers a very narrow question: what issue are we talking about?
Each CVE entry typically includes a short description of the vulnerability, information about affected software, and references to advisories or patches. That information is intentionally limited. A CVE does not describe how a vulnerability behaves in your environment, whether it is reachable, or what damage it could realistically cause if exploited.
This limitation is not a flaw in the CVE system. It is a design choice. CVEs exist to support consistency and coordination across a global security ecosystem that includes vendors, researchers, tooling, and defenders. To fulfill that role, CVEs must remain environment-agnostic.
When teams treat CVEs as risk judgments rather than identifiers, problems begin. A CVE can look alarming on paper but be completely irrelevant in practice. Another CVE may appear routine yet sit on a critical attack path in a production environment. The CVE itself does not contain the information needed to tell those two scenarios apart.
CVE Identifiers Explained
CVE identifiers follow a simple, standardized format, such as CVE-2021-44228. The identifier encodes the year the CVE was assigned and a unique number, but it does not convey severity, exploitability, or priority.
Once assigned, a CVE goes through a lifecycle. Details may be updated as more information becomes available. In some cases, a CVE may be disputed or withdrawn if the issue cannot be confirmed or is later determined not to be a vulnerability. Throughout this process, the identifier remains the anchor that tools and advisories use to stay aligned.
Vulnerability scanners, patch management systems, and security advisories all rely on CVE identifiers to correlate findings. Multiple vendors may reference the same CVE in different contexts, but the identifier ensures everyone is still talking about the same underlying issue.
The CVE program is stewarded by MITRE, which governs how identifiers are assigned and maintained. That stewardship reinforces the role of CVEs as neutral references, not opinions about risk or urgency.
CVE vs CWE
CVEs are often confused with CWEs, but they serve different purposes.
A CVE describes a specific vulnerability in a specific piece of software. A CWE, or Common Weakness Enumeration, describes the broader class of weakness that led to the vulnerability, such as improper input validation or insecure authentication logic.
In practical terms, a CVE is the instance, while a CWE is the pattern. Many different CVEs can map back to the same CWE. Understanding CWE categories can help explain why similar vulnerabilities keep appearing across different products and versions.
However, CWE does not replace CVE. CVEs are still required to track individual issues, coordinate disclosure, and manage remediation. CWE provides insight into root causes, while CVEs provide the shared references that vulnerability management workflows depend on.
Recognizing this distinction helps clarify why vulnerability data alone is not enough. CVEs and CWEs describe what exists and why it exists. Determining whether it matters requires additional context.
The CVE Database: Curated Vulnerability Intelligence by Wiz
Wiz's CVE Database curates CVE data to create easy-to-navigate profiles that cover the entire vulnerability timeline, exploit scenarios, and mitigation steps.
Explore database

Vulnerability vs Exposure in Cloud Environments
A vulnerability and an exposure are not the same thing, even though they are often treated as interchangeable. Understanding the difference is essential for making sense of CVEs in modern cloud environments.
A vulnerability is a flaw in software that could potentially be exploited. A CVE tells you that such a flaw exists. An exposure describes whether that flaw is actually reachable and usable by an attacker in a real environment. Exposure depends on how the vulnerable component is deployed, what it can access, and how it is connected to the rest of the system.
In traditional on-prem environments, the gap between vulnerability and exposure was often smaller. Systems were long-lived, network boundaries were relatively static, and ownership was easier to trace. In cloud environments, that gap widens dramatically.
Cloud architectures introduce layers of abstraction and dynamism that change how risk materializes. Services communicate through APIs. Workloads scale automatically. Containers are rebuilt frequently. Identity and access permissions often determine reachability more than network topology alone. As a result, a vulnerable component may exist without presenting meaningful risk, while a seemingly modest vulnerability can become critical under the right conditions.
This is why CVEs on their own struggle to convey real risk in the cloud. A CVE does not tell you whether a vulnerable service is internet-facing or isolated. It does not tell you whether the workload runs with minimal permissions or broad administrative access. It does not tell you whether the service can reach sensitive data, or whether it sits on a path that an attacker could realistically traverse.
Risk emerges when vulnerability and exposure intersect.
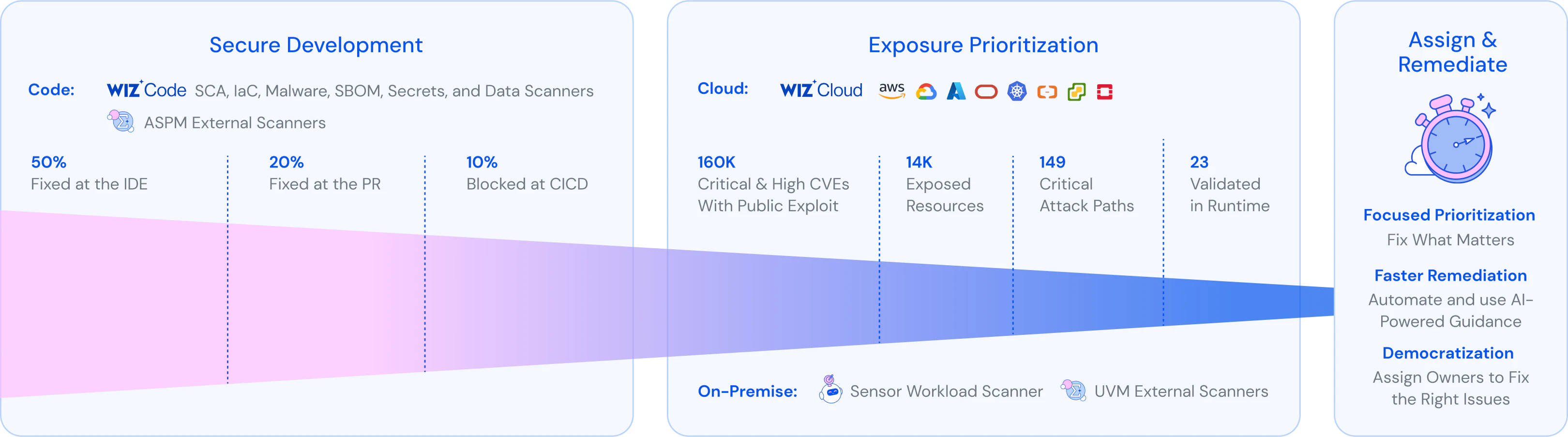
Why Exposure Changes Everything
Exposure is what turns a theoretical weakness into a practical threat. In cloud environments, a few contextual factors tend to matter far more than raw vulnerability counts.
Internet reachability
A vulnerability in a public-facing API or load balancer is fundamentally different from the same vulnerability in an internal service with no external access. Reachability determines whether an attacker can even attempt exploitation.
Identity and permission context
Cloud workloads are defined by the permissions they carry. A vulnerability in a low-privilege service may have limited impact, while the same vulnerability in a workload with broad IAM permissions can enable lateral movement or privilege escalation.
Access to sensitive or regulated data
Exposure increases dramatically when a vulnerable component can access customer data, financial records, credentials, or regulated information. In these cases, even vulnerabilities that seem minor on paper can have serious consequences.
Attack paths and combinations
In the cloud, serious incidents often result from combinations rather than single failures. A CVE may only become dangerous when paired with a misconfiguration, an exposed secret, or overly permissive identity policies. These attack paths are rarely visible when vulnerabilities are evaluated in isolation.
This distinction explains why vulnerability management breaks down when teams rely solely on CVE lists and severity scores. Most environments contain thousands of vulnerabilities at any given time. Only a small subset are exposed in ways that create real risk.
Effective CVE management, especially in the cloud, requires shifting focus from counting vulnerabilities to understanding exposure. Once teams can see which CVEs are reachable, impactful, and connected to critical assets, prioritization stops being guesswork and starts becoming defensible.
The Vulnerability Management Buyer's Guide
Everything you need to know to evaluate VM providers in one actionable guide.

CVSS Scores and Their Limitations
The Common Vulnerability Scoring System, or CVSS, is often treated as the authority on vulnerability severity. In practice, CVSS was designed to answer a much narrower question than most security teams expect it to.
CVSS provides a standardized way to describe the potential impact of a vulnerability in isolation. It evaluates factors such as how a vulnerability might be exploited and what could happen if exploitation succeeds. This makes CVSS useful for comparison and coordination across tools and vendors, especially when little contextual information is available.
What CVSS does not do is evaluate risk in a specific environment. CVSS scores are static and environment-agnostic by design. They do not account for how software is deployed, whether a vulnerable component is exposed, what permissions it runs with, or what data it can access. Those factors are outside the scope of the scoring system.
This is why the same CVE, with the same CVSS score, can represent vastly different levels of risk in different environments. A vulnerability rated “critical” may be unreachable in practice, while a medium-severity issue may sit on an exposed service with access to sensitive data. CVSS treats those scenarios as equivalent because it cannot see the surrounding context.
In cloud environments, this limitation becomes more pronounced. Infrastructure is dynamic, identities are powerful, and services are interconnected in ways that CVSS was never designed to model. Severity scores remain useful as a signal, but they cannot be used as a decision-making mechanism on their own.
CVSS is maintained by FIRST, and its role as a common framework is valuable. Problems arise only when CVSS is asked to do more than it was intended to do.
For effective vulnerability management, especially in the cloud, CVSS should be treated as one input among many. It can help highlight issues worth attention, but determining what to fix first requires additional signals, particularly those related to exposure, identity, and impact. Without that context, severity scores alone tend to drive volume-based remediation rather than risk-based action.
How CVEs Are Assigned and Published
CVEs do not appear automatically when a vulnerability is discovered. Each identifier goes through a defined assignment and disclosure process designed to ensure consistency, coordination, and responsible publication across the security ecosystem.
When a vulnerability is identified, it is typically reported by a researcher, vendor, or security team. That report is reviewed by a CVE Numbering Authority, or CNA. CNAs are organizations authorized to validate vulnerabilities and assign CVE identifiers within a specific scope, such as a product line, vendor ecosystem, or research domain.
The CVE program itself is overseen by MITRE, which sets the rules for how CVEs are assigned and ensures consistency across the ecosystem. MITRE’s role is administrative and coordinative. It does not assess severity, exploitability, or business impact. Its responsibility is to maintain a trusted, neutral identification system.
Once a CNA confirms that an issue meets the criteria for a CVE, an identifier is assigned. At this stage, the CVE may be reserved but not yet publicly disclosed. This allows vendors time to develop fixes and coordinate responsible disclosure. When disclosure occurs, the CVE is published with an initial description and references, and it becomes available to vulnerability databases, scanners, and advisories.
Security research organizations can also act as CNAs. Wiz is a CVE Numbering Authority, which means vulnerabilities discovered by the Wiz research team can be assigned CVE identifiers directly and disclosed to the broader security community without unnecessary delays. This helps ensure that cloud-specific vulnerabilities are documented and shared quickly as part of the public CVE ecosystem.
The timing of CVE assignment and publication varies widely. Some CVEs are issued and disclosed within days. Others take weeks or months due to validation complexity, vendor coordination, or embargo periods. During this time, details may evolve as researchers gain a clearer understanding of impact and affected components.
Not every reported issue ultimately becomes a valid CVE. Some identifiers are withdrawn or marked as disputed if the vulnerability cannot be reproduced, is determined to be a configuration issue rather than a software flaw, or does not meet disclosure criteria. Even after publication, CVE entries may be updated as new information becomes available.
This process reinforces an important point. CVEs are designed to document and track known vulnerabilities in a consistent way. They are not designed to reflect real-time exploit activity, environmental exposure, or business risk. The existence of a CVE tells you that an issue exists and how to reference it. Determining whether it actually matters requires additional context beyond the assignment process itself.
Guided Tour
See How Wiz Priorities CVEs
The Real Challenge of CVE Management in the Cloud
At this point, the problem with CVE management in cloud environments should be coming into focus. CVEs are useful identifiers. CVSS provides a generic severity signal. CVE assignment and publication follow a structured process. Yet despite all of this structure, security teams still struggle to answer a simple question: what should we fix first?
The core challenge is scale. Modern cloud environments routinely contain thousands or tens of thousands of CVEs at any given time. Many of these vulnerabilities are inherited through base images, third-party libraries, or managed services. Treating each CVE as an individual action item quickly overwhelms remediation capacity, even for well-resourced teams.
Cloud infrastructure also changes continuously. Containers are rebuilt, serverless functions are redeployed, and services scale up and down automatically. Some vulnerabilities may exist only briefly. Others persist because they are embedded deep in shared images or dependencies. This constant churn makes it difficult to rely on static scans or periodic reviews to maintain an accurate picture of vulnerability risk.
Another challenge is ownership. In cloud environments, the team that receives a CVE alert is not always the team that can fix it. Vulnerabilities may originate in base images, shared platforms, or upstream libraries that are maintained elsewhere. Without clear linkage between a CVE and the teams, repositories, or pipelines responsible for it, remediation stalls.
Most importantly, CVE management in the cloud fails when vulnerabilities are evaluated in isolation. A single CVE rarely tells the whole story. Real risk often emerges when vulnerabilities intersect with exposure, identity permissions, and misconfigurations. A low-severity CVE can become critical when it sits on an internet-facing service with access to sensitive data. Conversely, a high-severity CVE may pose little risk if it is unreachable and tightly constrained.
This is why many organizations find themselves trapped in a cycle of noise. Dashboards fill with CVEs. SLAs are missed. Patch backlogs grow. Yet actual risk reduction remains elusive. The issue is not a lack of data. It is a lack of context.
Effective CVE management in the cloud requires a shift in approach. Instead of asking how many vulnerabilities exist, teams need to understand which vulnerabilities are exposed, which ones matter, and which ones create realistic paths to impact. Without that shift, CVE programs become exercises in compliance rather than meaningful drivers of security outcomes.
How Wiz Changes CVE Discovery and Prioritization
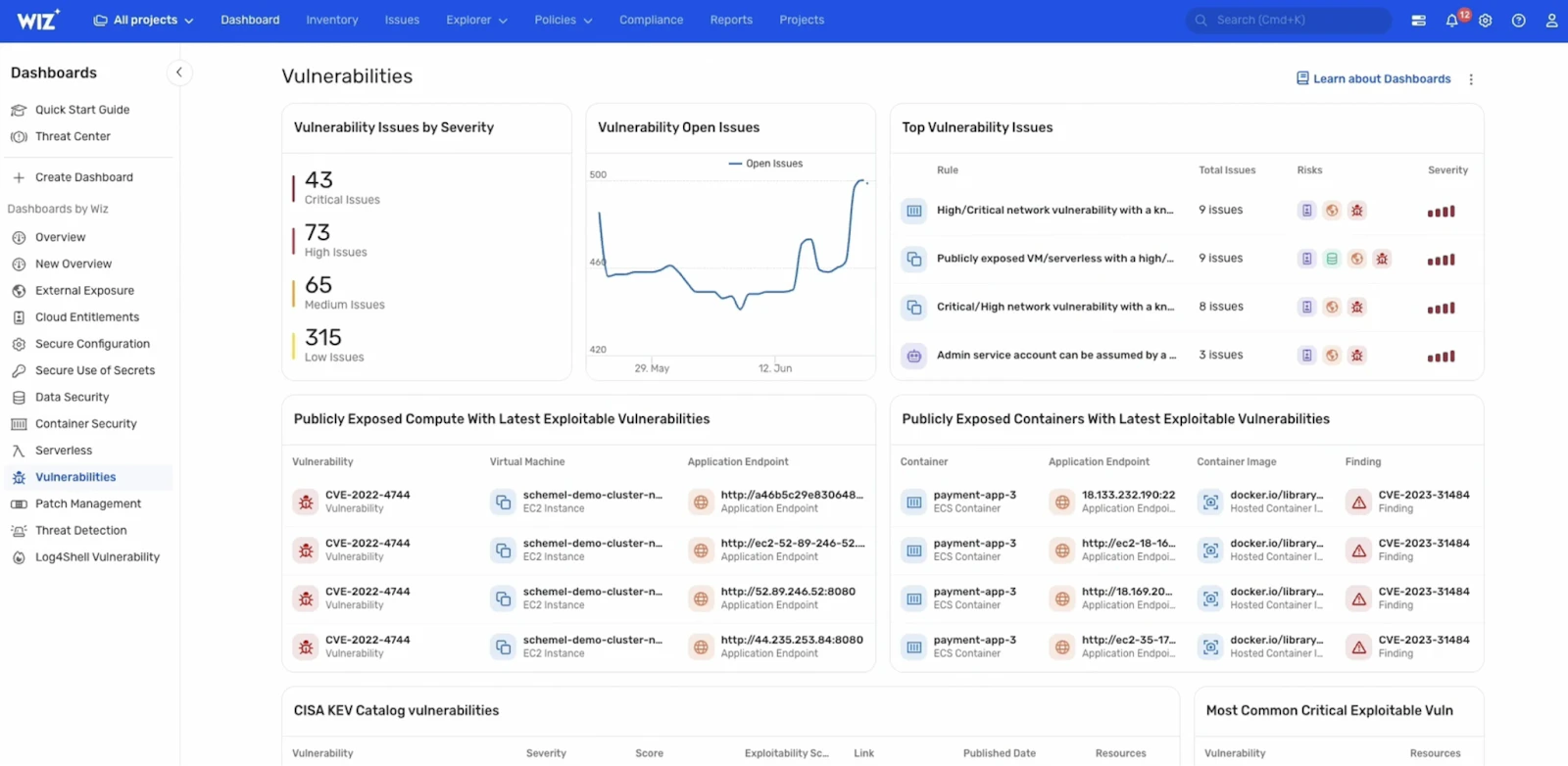
Wiz approaches CVE management through the lens of Unified Vulnerability Management (UVM). Instead of treating vulnerabilities, misconfigurations, and exposures as separate problem sets, Wiz evaluates them together as parts of the same risk surface.
Traditional vulnerability management treats CVEs as the primary unit of work. Findings are generated, scored, and queued for remediation largely in isolation. In cloud environments, this model breaks down because vulnerabilities rarely exist alone. Real risk emerges from how vulnerabilities intersect with exposure, identity, and configuration.
Wiz starts with continuous, agentless discovery of CVEs across cloud workloads, including virtual machines, containers, serverless functions, and managed services. This ensures broad coverage in environments where workloads are ephemeral and change constantly. But discovery is only the entry point, not the outcome.
Under the UVM model, CVEs are treated as one signal among many. Wiz correlates each vulnerability with runtime context such as internet exposure, identity permissions, and access to sensitive data. This unified view makes it possible to distinguish between vulnerabilities that are theoretically severe and those that create real risk in practice.
The Wiz Security Graph is central to this approach. It connects CVEs to misconfigurations, overly permissive identities, and reachable attack paths. A vulnerability becomes high priority not because of its CVSS score alone, but because it participates in a path that leads to privileged access or critical data. Conversely, CVEs that lack exposure or meaningful impact can be deprioritized without increasing risk.
This is where Wiz UVM changes the conversation. Instead of asking which CVEs exist, teams can see which vulnerabilities actually matter in the context of their cloud architecture. Vulnerabilities, exposures, and attack paths are evaluated together, producing a prioritized set of risks that are defensible and actionable.
UVM also improves response speed. When a new CVE or zero-day vulnerability is disclosed, Wiz enables teams to quickly determine whether affected workloads are present, exposed, and connected to sensitive assets. By tying vulnerabilities back to cloud resources, identities, and ownership, remediation efforts can focus on the risks that require immediate action.
Finally, UVM helps reduce noise at the source. Many CVEs originate from shared base images and inherited components. Wiz provides visibility into these sources of risk and enables teams to address them systematically, rather than repeatedly triaging the same issues across individual workloads.
In this model, CVEs remain important, but they are no longer the center of gravity. Unified Vulnerability Management shifts the focus from vulnerability counts to risk reduction by evaluating how vulnerabilities behave in real cloud environments. That shift is what allows security teams to move from reactive CVE triage to proactive, context-driven risk management.
Agentless Scanning = Complete Visibility Into Vulnerabilities
Learn why CISOs at the fastest growing companies choose Wiz to identify and remediate vulnerabilities in their cloud environments.
