




Kubernetes v1.25 introduced alpha support for Linux user namespaces (userns). This feature is touted as an additional isolation layer that improves host security and prevents many known container escape scenarios.
In this blog, we will dive deep into some potential uses and intricacies of user namespaces in order to provide a set of best practices for cluster operators aiming to enhance their clusters’ security.
Background
User namespaces are not a new concept. The Linux kernel manual mentions userns starting with v3.8. Ever since, userns have been a core technology behind rootless containers. Given that current kernel versions are in the 5.x range, userns have had ample opportunity to evolve. However, their complexity and potential security implications must be recognized: their use opens previously untested code paths. Despite being readily available in the kernel, several Linux distributions chose to disable userns by default in order to allow the feature to mature. Kubernetes developers adopted a similar approach.
It is important to note that in Kubernetes, user namespaces are still in the alpha stage. They are not production ready. In fact, the only place userns can be tested in managed clusters is Google Kubernetes Engine (GKE) alpha clusters. All testing described in this post occurred there.
How user namespaces improve workload security
User namespaces make it easier for cluster operators to mitigate the potential impact of container escape and allow extra privileges to be more safely granted to certain pods.
Mitigating the impact of container escape
The main motivation behind user namespaces in the container context is curbing the potential impact of container escape. When a container-bound process running as root escapes to the host, it is still considered a privileged process with its user ID (UID) equal to 0. However, user namespaces introduce a consistent mapping between host-level user IDs and container-level user IDs that ensures a UID 0 on the container corresponds to a non-zero UID on the host. In order to eliminate the possibility of UID overlap with the host, every pod receives 64K user IDs for private use.
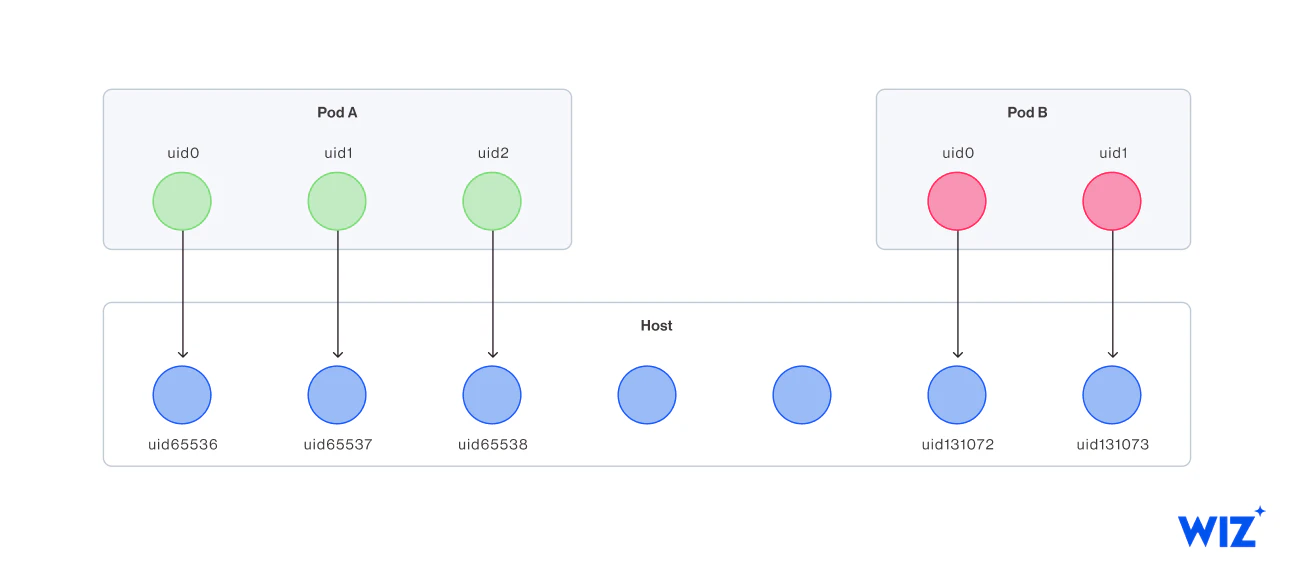
As a result, even if a process is root (i.e. UID 0) inside the container, escaping to the host will only entitle it to access resources associated with UID X. For instance, in the figure above, UID 0 on Pod A would only be able to access resources that UID 65536 is entitled to at the host level.
Moreover, an escaped process with a user namespace would be blocked from accessing resources such as:
/etcconfig filesDevices in
/devThe
/home/rootdirectory storing potential secretsKubelet config, which is commonly used for lateral movement within the cluster and is only readable by the root process on the cluster host
gke-test-default-pool-c15ade0e-yz47 / # ls -la /var/lib/kubelet/kubeconfig
-rw-r--r-- 1 root root 554 Dec 10 16:11 /var/lib/kubelet/kubeconfig` Unix sockets with root ownership
tcp/udp sockets with root ownership
User ID mapping prevents the exploitation of many prominent vulnerabilities. Using Azurescape as an illustration, an actor could escape to the host and call an API with the kubelet config file. With a user namespace, however, they would be unable to read the file and the exploit chain would be broken, averting cross-account container takeover.
A secondary benefit of UID mapping is better separation between pods on the same worker node in the event container escape occurs. This assumes that individual pods have different UID/GID mapping schemes onto the host, which should always be handled by a kubelet on a managed cluster.
A third often-overlooked advantage UID mapping offers is the separation of resource limits. In Linux, cgroups and namespaces are responsible for “containerizing” different workloads on the same host, with each receiving its own CPU, memory quota, etc. Nevertheless, some limits like the number of filesystem notifications remain tied to the UID/GID. Since many pods use UID 1000, they are sharing this limit; the userns feature’s automatic host UID remapping resolves this issue.
Stripping unnecessary privileges
Privileged containers running in their own user namespace are isolated and therefore their capabilities cannot harm the host. For example, Kubernetes lacks support for FUSE filesystem mounting. One workaround is adding a spec to mount a GCP bucket at a postStart event with the required CAP_SYS_ADMIN permissions for the initial namespace.
spec:
...
containers:
- name: my-container
securityContext:
privileged: true
capabilities:
add:
- SYS_ADMIN
lifecycle:
postStart:
exec:
command: ["gcsfuse", "-o", "nonempty", "your-bucket-name", "/etc/letsencrypt"] However, SYS_ADMIN is a powerful capability. In this case, implementing a user namespace would eliminate the need to specify privileged:true and grant SYS_ADMIN, drastically reducing the host’s attack surface.
Another common scenario is connecting a pod to a VPN network. Popular services like OpenVPN require the NET_ADMIN capability to configure a pod's network settings. When isolated by a user namespace, a pod is unable to hijack the host’s network configuration in the event of container escape.
Limitations
As expected of alpha features, user namespaces in Kubernetes are subject to some limitations.
Non-root can still in effect be root
In Linux, certain actions are reserved for privileged users. Even if the actions are performed inside a user namespace, the code paths and added functionality provide new attack vectors to threat actors with the ability to execute commands in a compromised pod.
Consider CVE-2022-0185. Exploiting this vulnerability requires a localized CAP_SYS_ADMIN granted automatically by userns, reflecting how a security feature can actually generate an insecurity at the kernel level. However, user namespace creation is not a privileged operation. For instance, although the creation of a PID namespace is forbidden, the creation of a new user namespace is permitted in the following GKE pod:
shay_b@cloudshell:~ (shay-junk-cluster)$ kubectl exec -it test-userns -- sh
/ # unshare -p
unshare: unshare(0x20000000): Operation not permitted
/ # readlink /proc/$$/ns/user
user:[4026531837]
/ # unshare -U
test-userns:~$ readlink /proc/$$/ns/user
user:[4026532869]Given the unshare(CLONE_NEWUSER) syscall creates new user namespaces–resulting in local, albeit risky SYS_ADMIN capabilities–it is critical to block the syscall with a seccomp profile. Fortunately, Kubernetes v1.25 upgrades the default seccomp profile feature to beta, diminishing deployments’ initial attack surface.
Workload classes
There are a variety of factors that impact whether user namespaces are appropriate for a pod. The following decision tree is designed for cluster operators to assess the fitness of their workloads under the current feature implementation:
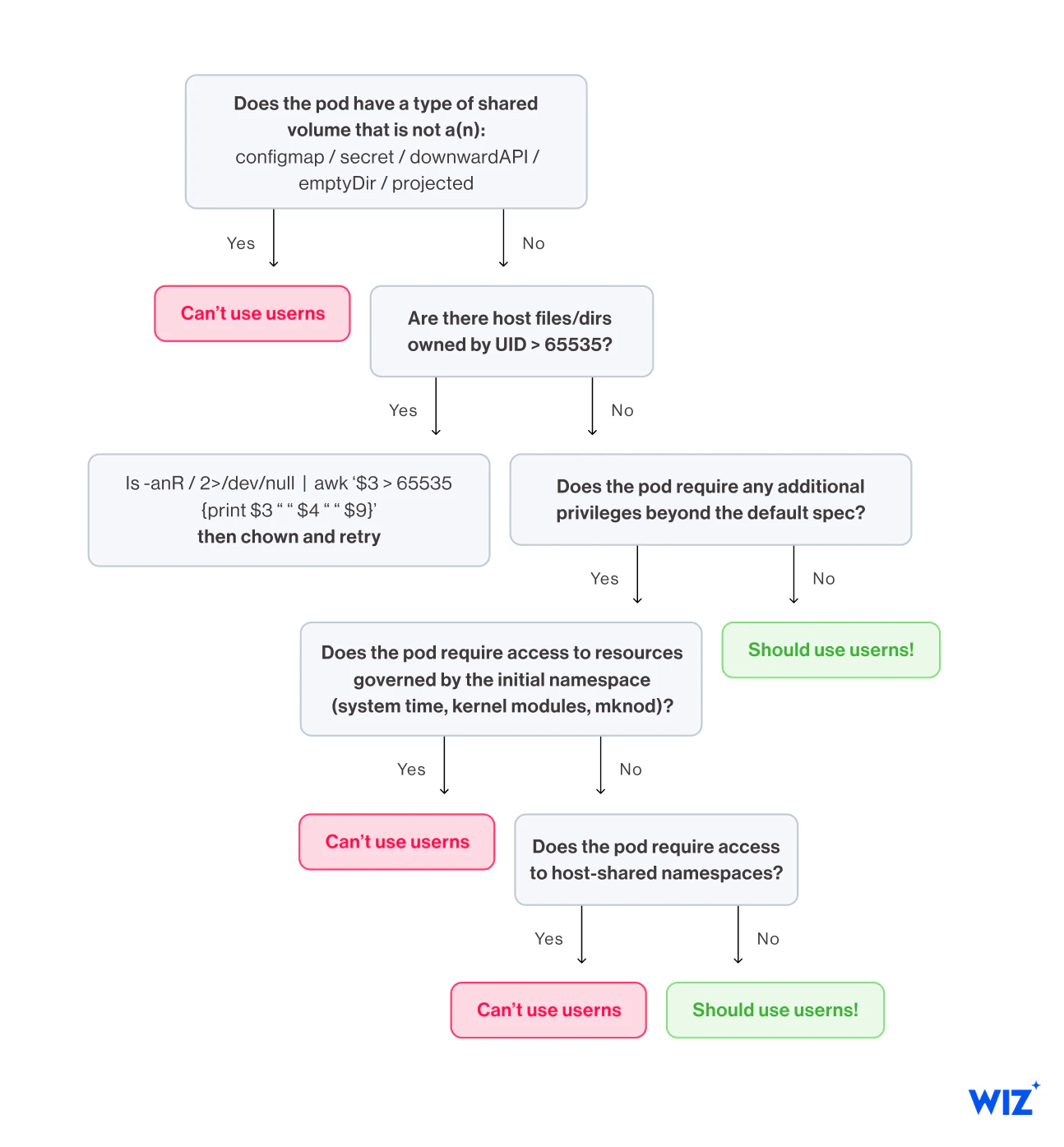
The three most prominent workload classes that are incompatible with user namespaces are those with shared volumes, those requiring initial namespace access, and those requiring host-shared namespace access (see Appendix B).
These only represent the most common limitations–there are many other possible cases. Wiz Research investigated hundreds of cloud environments to quantify some of these limitations and found that in containerized environments:
Over 30% of pods run with host-shared namespaces
44% of pods have problematic volumes mounted in their spec
24.4% of pods are privileged
1.8% of pods have
allowPrivilegeEscalation: true
These numbers highlight how user namespaces are ill-suited to a significant portion of workloads in production environments. Future research should further investigate the types of privileges afforded to pods and the impact of userns on pod privilege reduction.
Summary
User namespaces in Kubernetes offer several ways to improve workload security even though they can under certain uncommon configurations increase the attack surface of clusters. From remapping UIDs to reducing privileges, user namespaces improve isolation for applicable workloads. In order to help practitioners gauge workload fitness, we have compiled a decision tree that describes which workloads are compatible with the feature. Given the complexity of userns, it will be interesting to monitor the feature’s maturation process and see how developers address current limitations.
Appendices
Appendix A–Userns in Docker
Kubernetes-level support of user namespaces is conditioned on container runtime support. Docker was one of the earliest adopters of userns. Consider the following user mapping when running the Docker daemon with userns-remap enabled after editing /etc/docker/daemon.json.
kali@kali:/tmp$ sudo docker run -it --rm alpine sleep 1h
---
kali@kali:/usr/local/lib/systemd/system$ ps aux | grep sleep
root 2919 0.0 0.0 10752 5128 pts/1 S+ 10:19 0:00 sudo docker run -it --rm alpine sleep 1h
root 2920 0.8 0.8 1423596 53860 pts/1 Sl+ 10:19 0:00 docker run -it --rm alpine sleep 1h
296608 2969 0.4 0.0 1608 4 pts/0 Ss+ 10:19 0:00 sleep 1h Although the sudo and Docker processes are running as root, the Bash process has UID 296608. This is because the default Docker user for remapping user IDs is configured in /etc/subuid as dockremap:296608:65536. The root user in the container corresponds to UID 296608 on the host, UID 1 to UID 296609, and so on.
Additionally, the level of namespace isolation differs between the container and the host, with the only shared namespace being the time namespace:
kali@kali:/etc/docker$ sudo ls -la /proc/1/ns
lrwxrwxrwx 1 root root 0 Dec 16 14:04 cgroup -> 'cgroup:[4026531835]'
…
lrwxrwxrwx 1 root root 0 Dec 16 14:04 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Dec 16 14:04 uts -> 'uts:[4026531838]'
kali@kali:/etc/docker$ sudo docker run -it --rm alpine sh
/ # ls -la /proc/$$/ns
lrwxrwxrwx 1 root root 0 Dec 16 12:05 cgroup -> cgroup:[4026532866]
…
lrwxrwxrwx 1 root root 0 Dec 16 12:05 user -> user:[4026532672]
lrwxrwxrwx 1 root root 0 Dec 16 12:05 uts -> uts:[4026532674] Appendix B–Decision tree
Pods requiring privileges governed by initial user namespaces
The hierarchical structure of namespaces ensures a subordination of the resources managed by all non-user namespaces to the user namespace owner. Not all resources, however, are tied to the namespaces. As explained in the kernel userns manual:
There are many privileged operations that affect resources that are not associated with any namespace type, for example, changing the system (i.e. calendar) time (governed by CAP_SYS_TIME), loading a kernel module (governed by CAP_SYS_MODULE), and creating a device (governed by CAP_MKNOD). Only a process with privileges in the initial user namespace can perform such operations.
What happens if you try to run mknod in the user namespace after enabling user-remap in the Docker daemon (see Appendix A)?
kali@kali:/tmp$ sudo docker run -it --rm alpine sh
/ # mknod /tmp/null c 1 3
mknod: /tmp/null: Operation not permitted This means that workloads requiring access to resources and/or syscalls associated with initial namespaces cannot use this feature. Moreover, it will be impossible to add these capabilities in the securityContext of the pod.
KEP correctly identifies one user story describing why a cluster admin would not want to use the feature: “As a cluster admin, I want to allow some pods to run in the host user namespace if they need a feature only available in such user namespace, such as loading a kernel module with CAP_SYS_MODULE.”
Pods requiring capabilities on host namespaces
Consider a container that requires CAP_SYS_ADMIN on the host network stack to tap into the host network or a debug container requiring CAP_SYS_PTRACE on a host PID namespace. These pods will have to keep using current sharing interfaces. Currently pod specification allows the configuration of three types of shareable namespaces:
Network (
hostNetwork: true)process IDs (
hostPID: true)IPC (
hostIPC: true)
The presence of any of the above in the pod spec clashes with the potential usage of user namespaces.
Stateful workloads
Currently, only pods with the following set of volume types are allowed to utilize user namespaces:
configmap
secret
downwardAPI
emptyDir
projected
This is because resources cannot be shared between the pods once they are governed by a different user namespace. KEP describes the plan to tackle this limitation in phase 2 by mapping the pods using the shared volume to the same UID/GUID scheme. This will weaken the security posture of the node and represents a security/usability tradeoff.
Other limitations
Adding hostUser: true is incompatible with setting hostNetwork, hostIPC, or hostPID and as such results in a loss of privilege granularity. This compels a rather binary approach for the migration: either don’t use userns at all or only use userns. This loss of granularity also impacts capabilities–adding capabilities in securityContext is impossible if used in combination with user namespaces.
User namespaces affect file ownership mapping. According to the documentation: "The kubelet will assign UIDs/GIDs higher than that to pods. Therefore, to guarantee as much isolation as possible, the UIDs/GIDs used by the host's files and host's processes should be in the range 0-65535."
The following command finds any files on the node that are owned by user > 65535 and thus need to be chown-ed:
ls -anR / 2>/dev/null | awk '$3 > 65535 {print $3 " " $4 " " $9}'













