




📣UPDATE: On June 2022, we launched OPEN CVDB, a community-driven cloud vulnerability database - https://www.cloudvulndb.org/.
In the pre-cloud era, the responsibility for security was fully in the hands of the users. As we’ve moved to the cloud, we have seen not only new elements to secure and new vulnerabilities, but a new balance of shared responsibility for security between users and cloud service providers (CSPs). There has been a rough working arrangement where CSPs handle things like physical security, hardware, and managed services, while users are responsible for software, identities, and data protection. As we uncover new types of vulnerabilities, we discover more and more issues that do not fit the current model.
The Wiz Research Team has discovered and disclosed several serious vulnerabilities this year – such as AWS cross-account vulnerabilities, ChaosDB, and OMIGOD – and we’ve found that these vulnerabilities don’t fit into the model of cloud security responsibilities today, and enumeration and response are falling flat as a result.
Each of the vulnerabilities required a unique remediation process with varying responsibilities from CSPs and customers. We realized that there is no standardized way for addressing cloud vulnerabilities. Unlike other vulnerabilities that require user intervention like software vulnerabilities where we have CVEs, these cloud vulnerabilities have no identifier or enumeration, no standard format, no severity scoring and no proper notification channel. The response actions are a mix of efforts from the CSP and the user. A lack of clarity and understanding around this handoff for cloud vulnerabilities is leading to missed opportunities and decreased security.

To illustrate what we mean, let’s take a look at three examples of cloud vulnerabilities the Wiz research team has disclosed in 2021 and what happened after.
The CVE Database: Curated Vulnerability Intelligence by Wiz
Wiz's CVE Database curates CVE data to create easy-to-navigate profiles that cover the entire vulnerability timeline, exploit scenarios, and mitigation steps.
Explore database

Cloud vulnerability example #1: Cross-Account AWS Vulnerabilities
In this situation, we discovered multiple instances of a confused deputy vulnerability that affected four popular AWS services. The source of these vulnerabilities was in the default access policies provided by Amazon to users. AWS provided users with over-permissive resource policies, allowing other AWS tenants to perform read and write operations on vulnerable users.

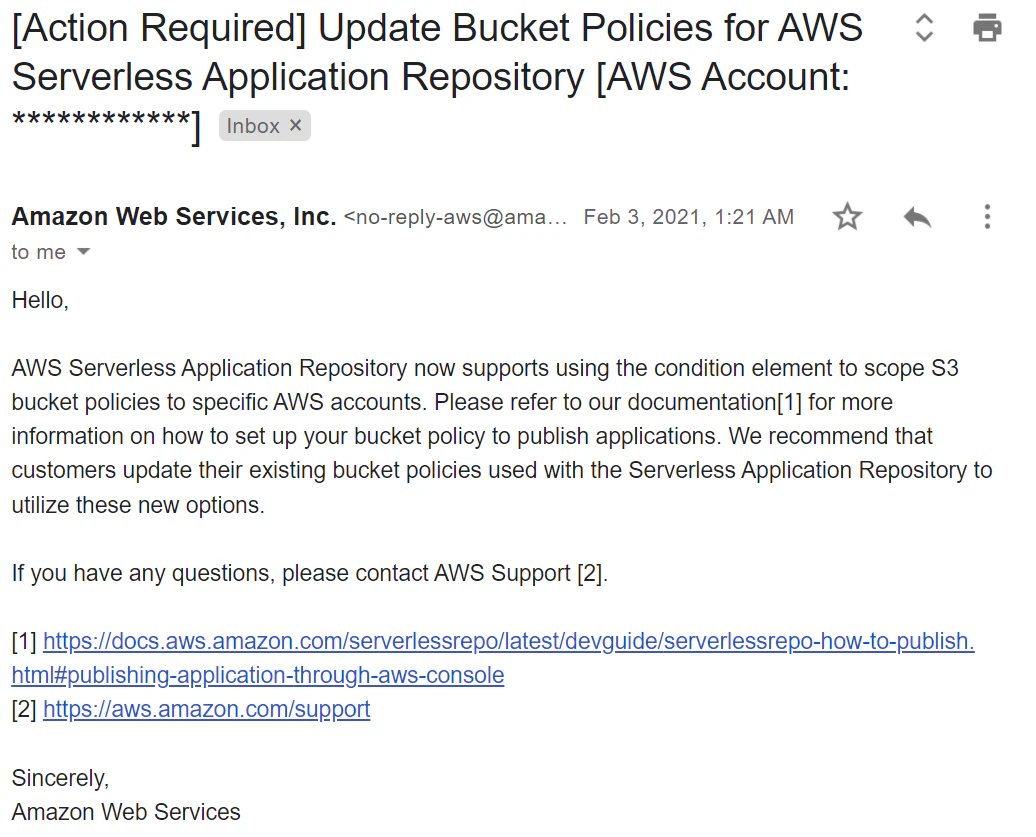
One of the vulnerable services was the AWS Serverless Repository Service. The policy provided by Amazon for its users lacked scoping conditions, and the Serverless Repository service did not support scoping conditions at the time. Because of the lack of scoping, any user of the service could access another tenant’s S3 buckets if they were configured with the vulnerable policy.
In response to the disclosure, Amazon took the issue very seriously. They changed the default policy, and updated the documentation to guide new users on setting up the proper secure configuration. This served to prevent the issue from spreading further. However, these actions had no effect on existing users, as Amazon is unable to change their configurations for them without potentially breaking their environment. So Amazon emailed all vulnerable users and called on them to update the vulnerable configurations they had and scope it with the right security conditions.
The problem here is that users weren't aware of the vulnerable configuration and the response actions they should take. Either the email never made it to the right person, or it got lost in a sea of other issues. Security teams far too many alerts, vulnerabilities, and incidents to pay attention to. How should they track whether these issues have already been addressed in their organization? How do they know which cloud resources have already been scoped and fixed? The approach of notifying by email is not sufficient. It doesn't provide the public with transparency into issues and makes tracking the status of issues extremely difficult. Without transparency and tracking capabilities, many organizations won't be able to fix security issues properly. We often see this result in real cloud customer environments. When CSPs notify users about security issues over email or equivalent proprietary systems, the issues are likely to remain unfixed and expose customers to risks.
Cloud vulnerability example #2: OMIGOD
Our second example is one we called OMIGOD. OMIGOD was a set of 4 new vulnerabilities that we discovered in Microsoft’s OMI agent, which is cloud middleware used by many Azure services and silently installed on users' virtual machines by Microsoft when they set up these services (Azure Log Analytics, Azure Automation and more). These vulnerabilities enabled remote code execution and local privilege escalation at root privileges. Upon disclosure, Microsoft patched the vulnerabilities and released a new version of the OMI agent.
Microsoft published the announcement as part of Patch Tuesday and provided guidance to users on how to update the agent. However, we see a similar situation here as in the AWS cross-account example: as users had no idea the OMI agents were installed in their environment, they had no way to know that they were vulnerable or where they were vulnerable. No information regarding affected services was published by Microsoft initially.
According to the shared responsibility model, the cloud user is responsible for updating software vulnerabilities within their virtual machines. But what happens when users don’t know OMI agents exist in their environment? How could they know?
Due to the uncertainty and lack of clear communication to users, the result was a significant number of confused cloud users, many cloud environments exposed to exploitation, and automated scanners that sought to hack into anyone who did not know how or if they should update.
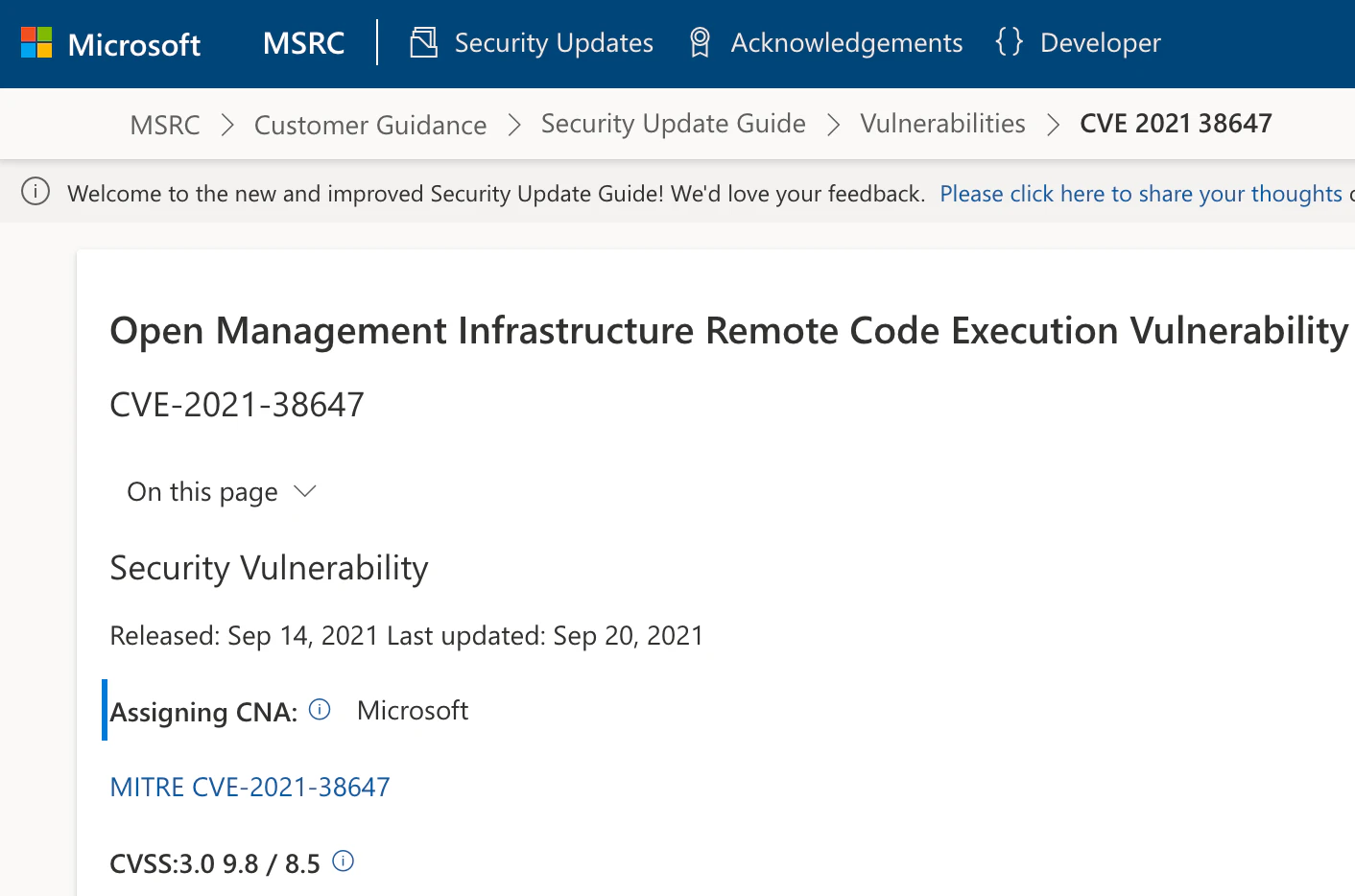
Here we learned that vulnerabilities can exist in pre-installed cloud middleware, not just in software that users create or install themselves. This vulnerability impacted multiple popular Azure services and the users of those services, but those users were not informed. The whole process of notifying users about cloud vulnerabilities barely exists. Lacking a proper channel, cloud users found themselves vulnerable without their knowing. Even though CVEs were issued for OMI, they did not specify which vulnerable Azure services they were linked to, and users had no clue if they should take action or what actions to take.
Cloud vulnerability example #3: ChaosDB
Our third instance was with ChaosDB. In August, 2021, we discovered an unprecedented service-level vulnerability in Azure Cosmos DB. Customers’ access keys were leaked, with access permissions to Cosmos DB databases of other cloud users. This occurred due to multiple flaws in the way Microsoft introduced the Jupyter Notebook feature to the Cosmos DB service. In short, Cosmos DB accounts used to come bundled with the Jupyter Notebook feature auto-enabled. This was not something made explicit to customers, so when flaws were found in Jupyter Notebook that impacted Cosmos DB, many customers were exposed without their knowledge.
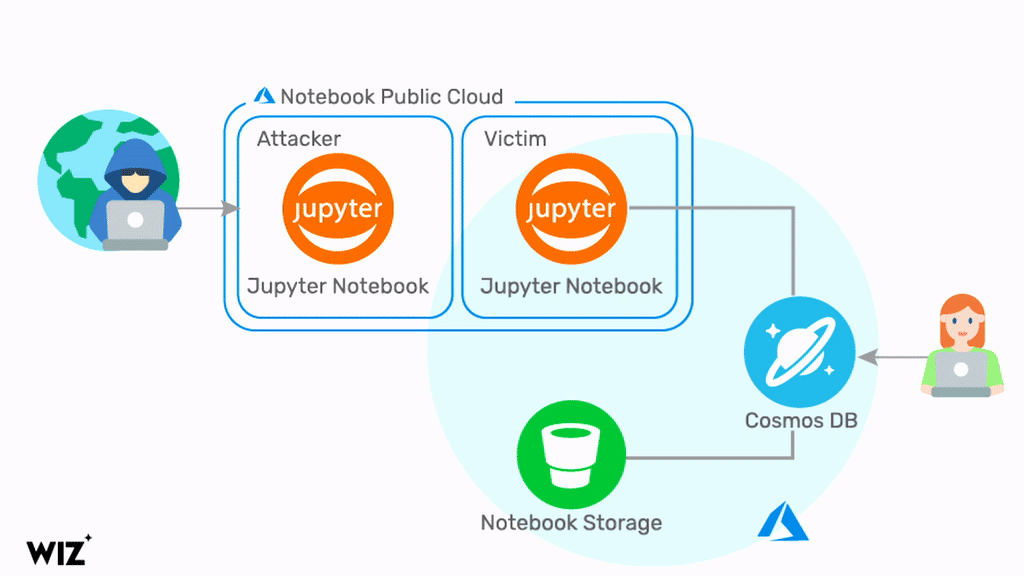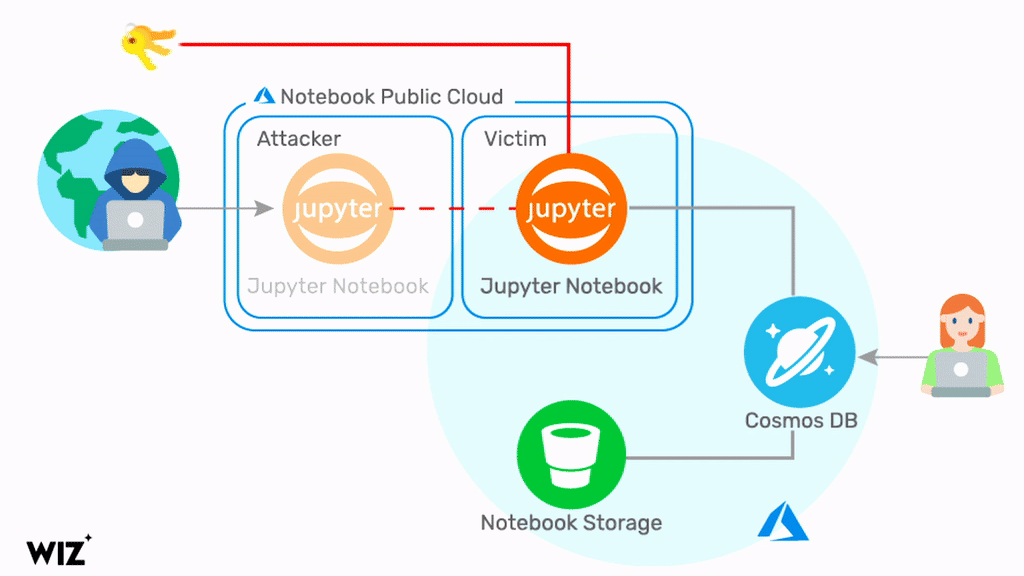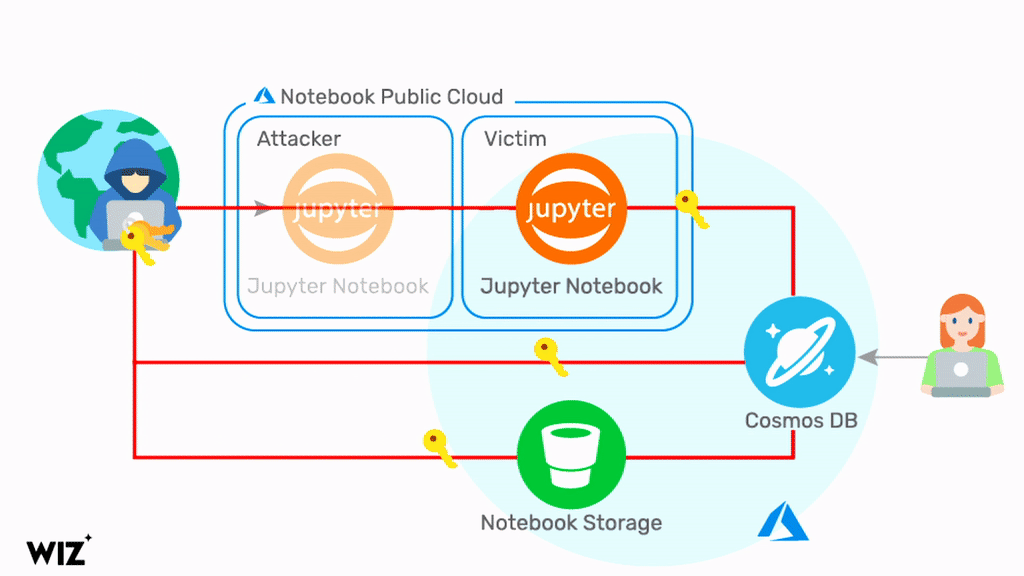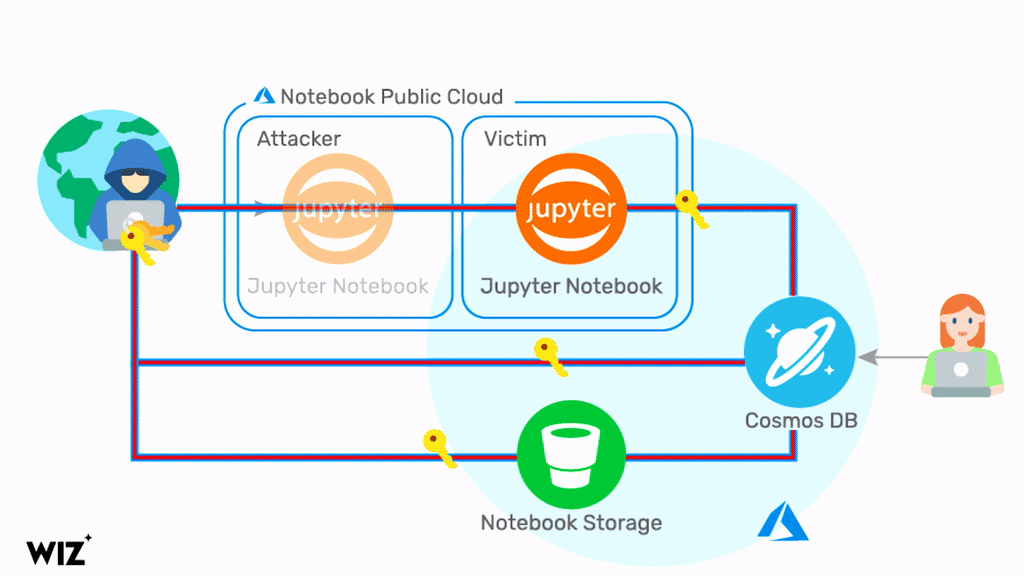
Upon disclosure, Microsoft quickly emailed a select group of customers, and later published a blog post on the vulnerability. Users were asked to manually rotate their keys for each instance of Cosmos DB. The timeframe of the vulnerability exposure was not made clear, making it difficult for users to know if they were at risk.
Once again, we are faced with a situation where users are asked to take manual action without the requisite clarity and transparency for them to know the priority of these actions and whether or not they are part of the impacted group at all. These manual actions are not trivial. Regenerating keys is a complex process. In some cases, it even requires code changes and new deployments. Due to the lack of a proper notification channel, transparency, and tracking capabilities for these vulnerabilities, a lot of users found it challenging to take the proper steps necessary for their environment. Moreover, future Cosmos DB users who would like to assess whether their DB is vulnerable would find it to be difficult due to the missing public details.
We must create a better way to respond to cloud vulnerabilities
The purpose of the examples above is not to just bash on CSPs. In most cases, they responded quickly and worked to mitigate the issues as best they could. The problems arise not from their lack of effort, but from a lack of standardization, transparency, and clear understanding of what each players’ role is in responding to cloud vulnerabilities. The major issues are as follows:
No standardized notification channel across CSPs
No issue tracking in place
No severity scoring to help users prioritize
Lack of transparency into the vulnerabilities and their detection
Variety of response actions across different vulnerabilities
We want to put forth a call to action to the security community: this is something we can improve. We believe we need a centralized database for reporting and enumerating cloud vulnerabilities.
This database must be public and standardized, so reports are consistent across CSPs. Each entry should be reported by CSPs and include the most pertinent information for users: vulnerability ID, description, severity, remediation steps, and detection methods.
Here’s an example of what such an entry could look like for ChaosDB:
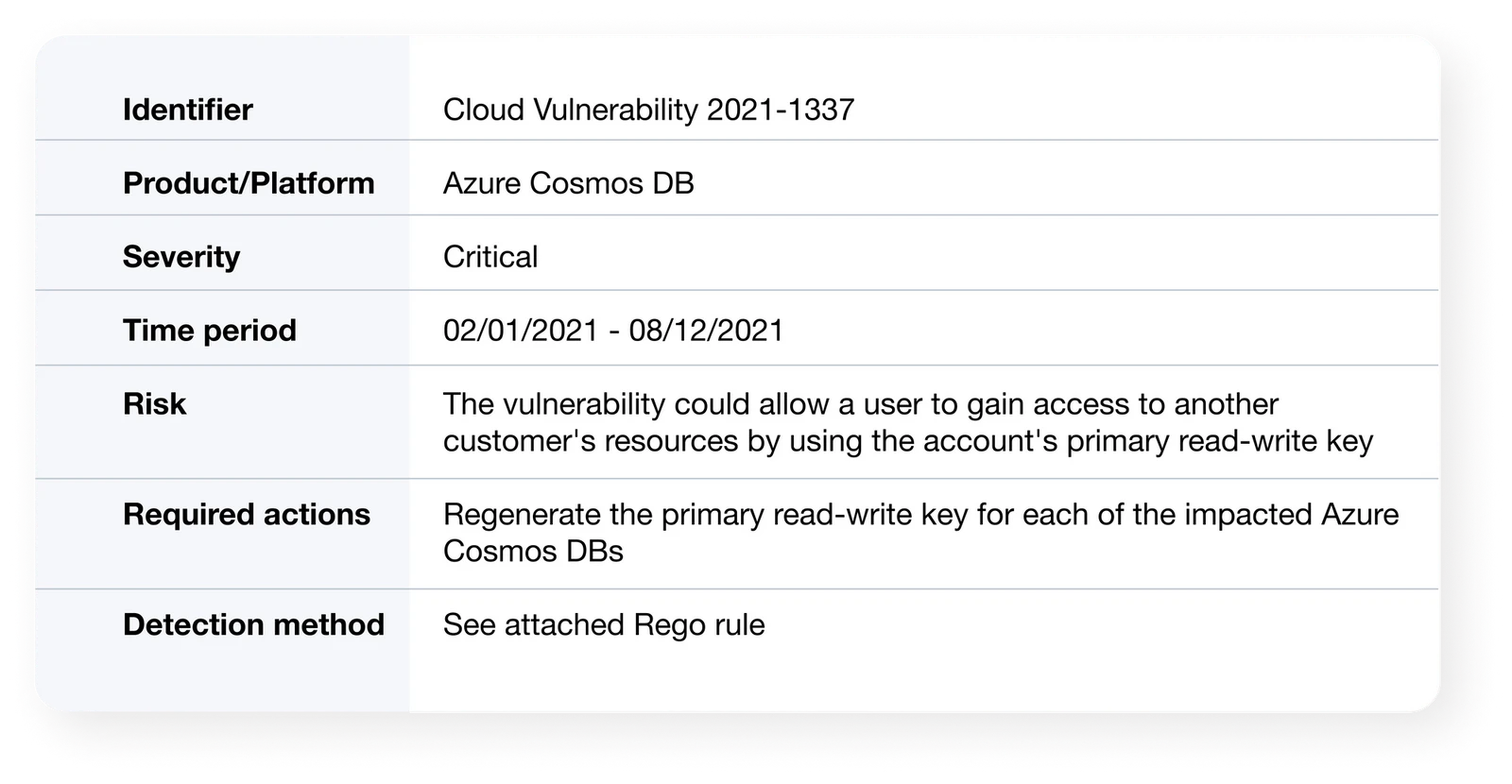
Similarly, cloud providers should use this format to report cloud vulnerabilities to a central database. This database must be public for anyone to use. For cloud customers who want to track their own environments and for security vendors who want to integrate it with their solutions. This database should be fed from the cloud providers themselves. We believe it is a shared interest of cloud providers and cloud users.

The exact shape and scope of this database is not something we claim to have all the answers to. What we hope to do here is start the discussion. There are several ways to get involved. First, we need to band together to put pressure on our CSPs to request CVEs for cloud services. We need to ask for more transparency, identification, and severity information for each vulnerability, and that has to come from our CSPs. Second, we’d like to thank our CloudCVE community for the insightful discussions that helped shape this blog. We’d love for you to join us on Slack to further discuss and shape this.
Watch our Security Industry Call-to-Action: We Need a Cloud Vulnerability Database briefing at BlackHat Europe 2021—
June 2022 - we launched OPEN CVDB, a community-driven cloud vulnerability database - https://www.cloudvulndb.org/.










