

What does choosing a DSPM vendor involve?
Choosing a DSPM vendor is the process of evaluating data security posture management solutions to find one that fits your organization's cloud environment, data landscape, and operational workflows. This decision determines whether your teams chase low-value alerts or fix exposures that could actually result in breaches.
The DSPM market has expanded as organizations recognize that traditional data loss prevention (DLP) tools were not designed for cloud-native architectures. Sensitive data now lives in object storage, managed databases, data lakes, snapshots, and developer environments across multiple cloud providers. What worked for on-premises data centers simply cannot keep up with how modern applications create, copy, and move data.
DSPM capabilities vary dramatically between vendors. Some focus narrowly on classification and compliance reporting while others integrate deeply with cloud infrastructure to show how data exposure connects to identity permissions, network configurations, and potential attack paths. A tool that only tells you "sensitive data exists here" is fundamentally different from one that tells you "sensitive data exists here, and it is accessible to the internet through this misconfigured bucket policy."
Understanding these differences before engaging vendors saves months of wasted effort. The wrong choice leads to shelfware or, worse, false confidence that data is protected when critical exposures remain invisible.
Choosing a DSPM Solution? Start Here.
Our buyer’s guide breaks down the must-have features, evaluation criteria, and an RFP template to help you make the right choice.

Why choosing the right DSPM vendor matters
Data breaches remain among the most expensive security failures organizations face, with misconfigurations implicated in a significant share of cloud breaches. Industry analyses consistently rank storage misconfigurations and excessive permissions among the top causes of cloud data exposure. Publicly exposed databases can be discovered quickly (sometimes within hours) depending on attacker scanning activity, authentication requirements, and ease of exploitation. Automated scanners continuously probe cloud IP ranges, meaning unprotected resources face immediate discovery risk.
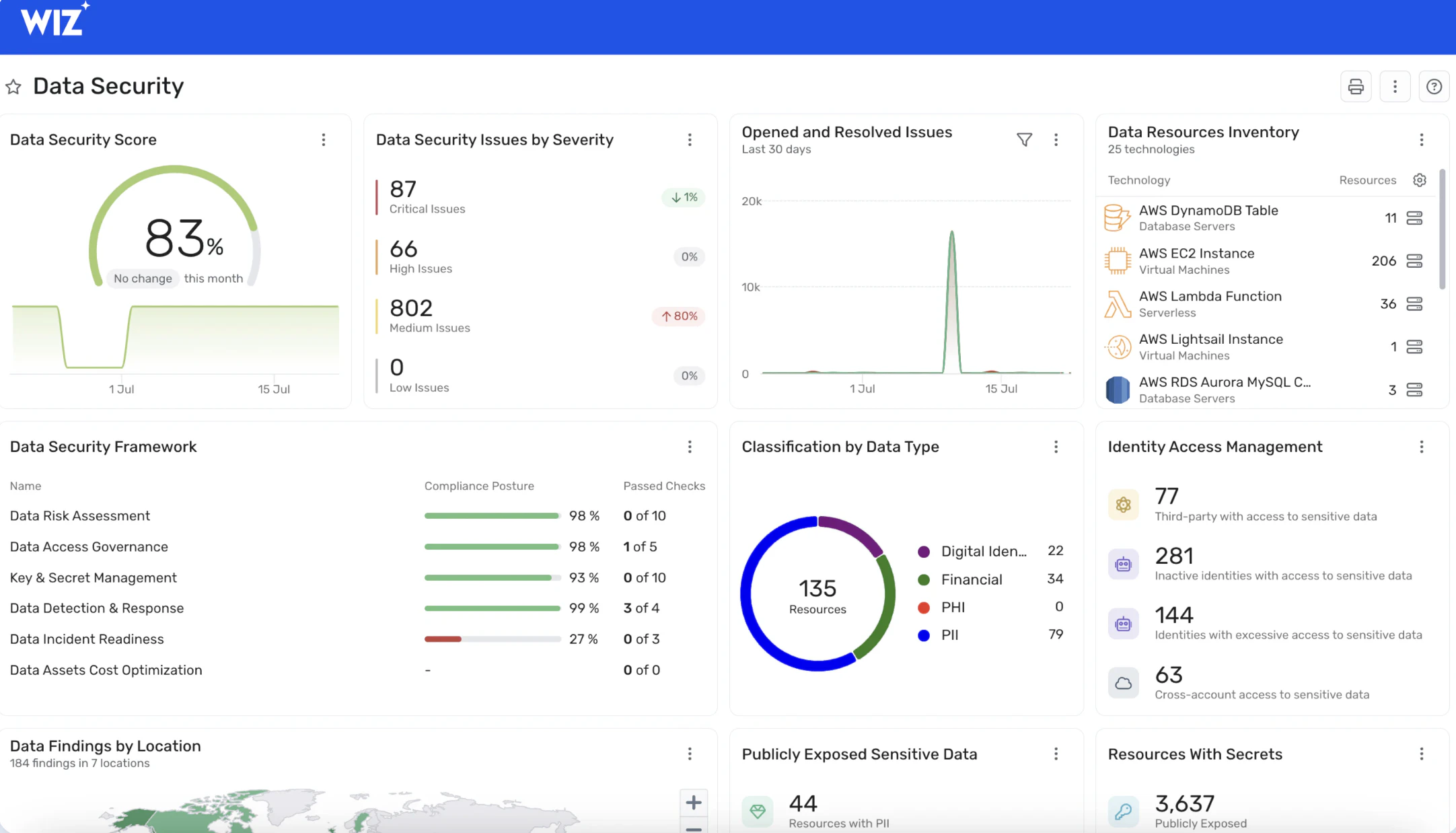
Cloud-native development has fundamentally changed where sensitive data lives and how it moves, with a large majority of enterprises now using cloud services across IaaS, PaaS, and SaaS. This shift means sensitive data now spans object storage, managed databases, data lakes, and developer environments across multiple providers. Production data gets copied into test environments for debugging. Database backups persist in forgotten snapshots long after anyone remembers they exist. ML pipelines ingest sensitive information into training datasets that get shared across teams. Traditional approaches focused on known, governed repositories miss most of this sprawl because they were designed for a world where data stayed in predictable places.
Regulatory pressure compounds these challenges. Frameworks like GDPR, PCI DSS, HIPAA, and DORA require organizations to know where sensitive data exists and demonstrate appropriate controls. A DSPM vendor that cannot map data findings to specific compliance requirements creates manual audit work that scales poorly as data volumes grow.
Security teams operate without visibility into most data risks. They cannot protect what they cannot see. The right vendor closes this visibility gap while the wrong one creates false coverage that leaves shadow data unprotected and critical exposures undetected.
What to look for in a DSPM solution
Core capabilities determine whether a DSPM tool solves data security challenges or creates new operational burdens. Evaluate each area against your specific requirements rather than accepting feature checklists at face value.
Discovery that finds the data you don't know about
Effective discovery requires more than scanning buckets you explicitly configure. Shadow data accumulates in orphaned snapshots, database backups copied across accounts, developer environments with production data samples, and cross-account copies that bypass governance controls entirely.
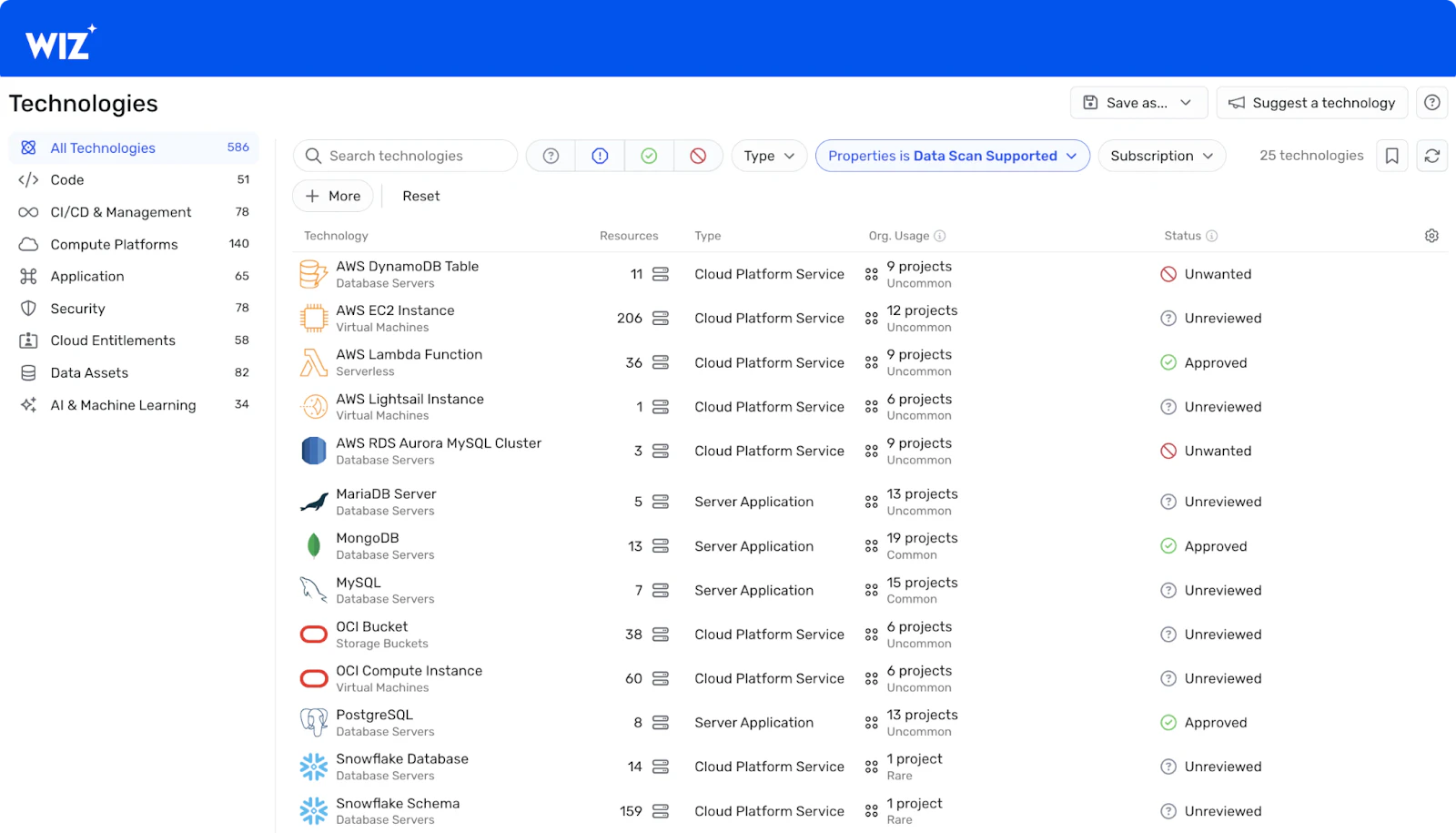
Look for agentless discovery using cloud provider APIs to find data stores across supported services in your cloud accounts without requiring per-resource setup. Verify which storage services (S3, RDS, Azure Blob, BigQuery, etc.) the vendor supports and whether discovery extends to cross-account resources. The tool should automatically detect new storage resources as they are created rather than waiting for periodic scans that miss short-lived resources. This matters because developers spin up new storage constantly, and each unscanned resource represents a potential blind spot.
Test whether discovery extends to data within workloads (for example, via disk snapshot analysis or runtime sensors) including VMs and containers, not just standalone storage services. Ask vendors whether they scan attached volumes, analyze snapshots, or require agents for workload-level visibility. Sensitive data embedded in application configurations, environment variables, or log files often escapes detection by tools focused solely on storage buckets and databases.
Classification that balances accuracy and coverage
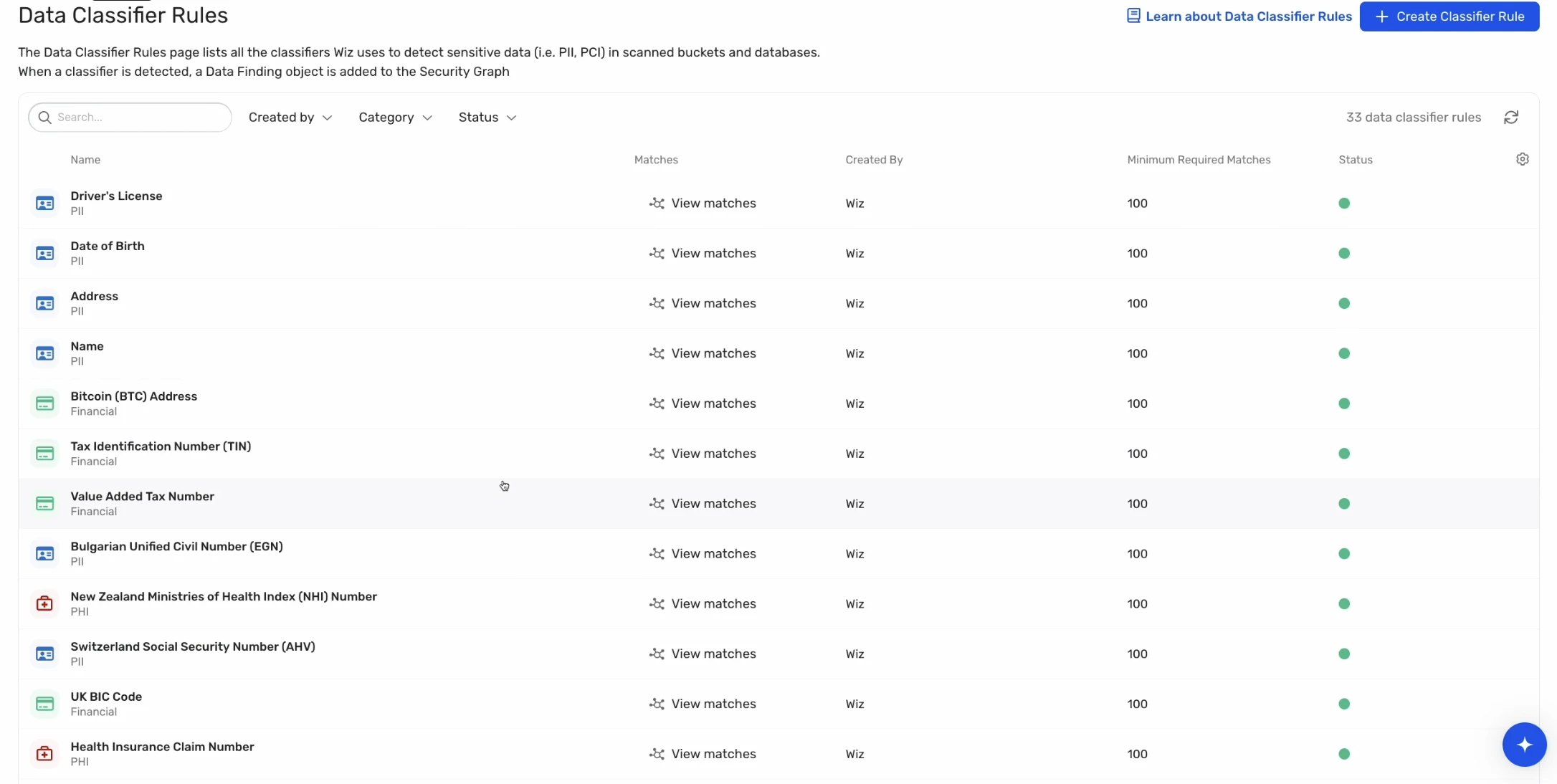
Data classification determines which findings matter. Poor classification creates noise through false positives that waste investigation time or dangerous gaps through false negatives that miss real sensitive data.
Pattern-based classification using regular expressions for credit card numbers or social security numbers provides baseline detection but misses context. A sixteen-digit number in a test file containing sample data differs meaningfully from a real cardholder record in a production database. Look for classification that considers content and context together rather than flagging every pattern match equally.
Evaluate how the tool handles unstructured data. PDFs, compressed archives, images with embedded text, and office documents contain sensitive information that structured-data-focused tools cannot parse effectively. Request sample accuracy metrics for different data types rather than accepting a single blended accuracy number that obscures performance gaps.
Context that connects data to actual risk
Discovery and classification answer what sensitive data exists and where. Context answers whether that data is genuinely exposed in ways an attacker could exploit.
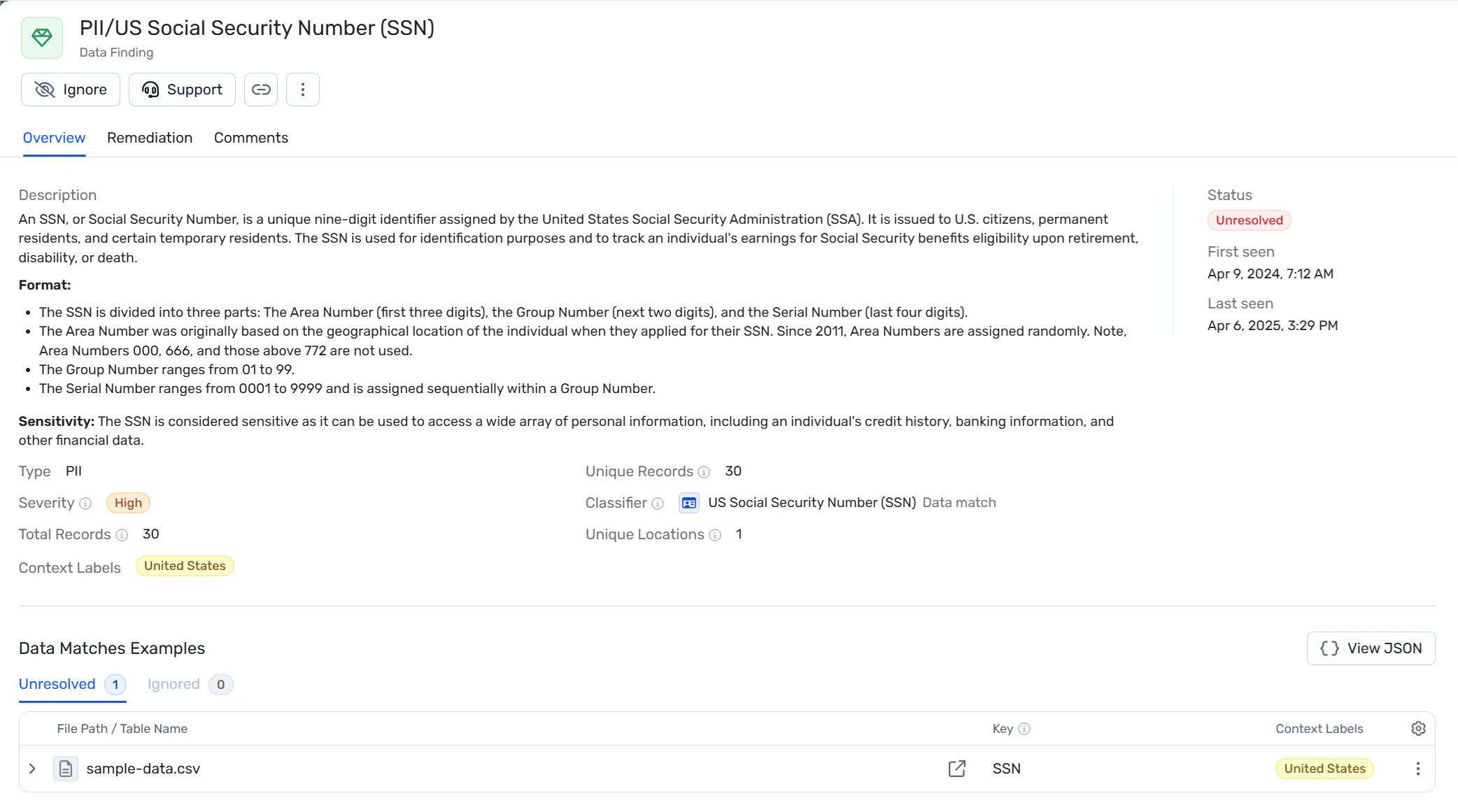
Consider the difference: A database containing customer records in a private subnet with no external access paths represents fundamentally different risk than the same data in a public bucket accessible to anonymous users. Without context, both appear as "sensitive data found" and receive equal attention despite vastly different urgency.
Look for tools that correlate multiple risk factors:
Network exposure: Is the data store reachable from the internet?
Identity permissions: Which users and service accounts can access this data?
Vulnerability state: Is the underlying infrastructure compromised or exploitable?
Configuration posture: Are encryption, logging, and access controls properly configured?
This correlation distinguishes validated exposure from theoretical risk. Prioritization should reflect real-world conditions: exposure paths, effective access, and asset criticality, not just sensitivity labels. Without this context, security teams waste time investigating findings that represent no realistic attack path while truly dangerous exposures get buried in the noise.
Identity and access visibility
Knowing where sensitive data exists matters less than knowing who can reach it. Data access often involves complex permission chains including direct grants, inherited policies, role assumptions, and trust relationships that create non-obvious access paths.
Evaluate whether the tool maps effective permissions rather than just listing attached policies. An identity might have read access to a sensitive bucket through multiple paths: a direct policy attachment, an inherited permission from a group, and a role assumption chain through a service account. Understanding the complete picture requires calculating effective permissions across all these paths.
Look for visibility into both human and machine identities. Service accounts, Lambda execution roles, and CI/CD pipeline credentials often have broader data access than individual users because they were configured for convenience rather than least privilege. The tool should distinguish identity types and highlight overprivileged access patterns that create unnecessary risk.
Remediation that goes beyond reporting
Finding problems without fixing them does not improve security posture. Evaluate how solutions support remediation workflows that help engineers actually resolve issues rather than just documenting them.
Actionable findings include specific guidance on what to change. The difference between "bucket is public" and "modify this bucket policy to remove anonymous access, here is the corrected configuration" determines whether engineers can act quickly or must research every finding independently.
Look for integration with infrastructure-as-code tools enabling remediation through existing deployment pipelines rather than manual console changes that drift over time. Evaluate automated remediation capabilities and the granularity of automation controls since some issues benefit from automatic fixes while others require human review.
Compliance alignment that reduces audit burden
Regulatory compliance requires demonstrating that data protection controls exist and function. A DSPM tool should map findings to specific framework requirements automatically rather than generating generic reports that auditors cannot use directly.
Verify support for frameworks relevant to your organization: PCI DSS, HIPAA, GDPR, SOC 2, and industry-specific regulations each have distinct requirements. Generic compliance dashboards not aligned to specific controls create manual mapping work during audits that defeats much of the value.
Look for continuous compliance monitoring rather than point-in-time assessments. Drift detection that alerts when configurations change in ways affecting compliance status helps maintain posture between formal audits rather than scrambling to remediate before each assessment.
Common pitfalls when choosing a DSPM vendor
Understanding where DSPM evaluations go wrong helps you avoid repeating common mistakes that lead to poor outcomes or wasted investment.
Evaluating demos instead of production environments
Vendor demonstrations use carefully constructed datasets showcasing capabilities without revealing limitations. Every demo shows accurate classification and clean dashboards because the data was specifically selected to produce those results.
The real test is connecting to your actual environment with the messy reality of legacy data formats, inconsistent naming conventions, and data in unexpected locations. Require a POC scanning representative production data, not vendor-provided sandboxes where every edge case has been smoothed away.
Treating DSPM as a standalone category
Data security does not exist in isolation from cloud security. A sensitive database finding matters more when the database host has a critical vulnerability, when an overprivileged identity can access it, and when network configurations allow external connections. These factors combine to create real risk.
Standalone DSPM tools unable to integrate with infrastructure context force manual correlation across multiple consoles, slowing response times and creating gaps where risks spanning multiple domains go undetected. Consider whether DSPM capability integrated into a broader cloud security platform provides better outcomes than best-of-breed point solutions requiring separate integration work.
Ignoring operational overhead
DSPM tools generating thousands of findings without prioritization create more work than they eliminate. Team capacity to remediate is finite, and a tool surfacing every sensitive file equally treats test documents with sample PII the same as production customer data accessible to the internet.
Evaluate how vendors approach prioritization. The goal is a short list of critical issues requiring immediate attention, not a comprehensive inventory overwhelming your remediation capacity.
Artisan, a healthcare technology company protecting fertility patient data, found their previous CSPM platform overwhelmed developers with alerts. As they explained: "With our old platform, we were getting thousands of alerts for every one problem that we'd solve. Wiz allows us to understand vulnerabilities much more efficiently. Now, we can concentrate our efforts on problems rather than simply identifying them."
CSPM vs DSPM: Why You Need Both
Discover the similarities between CSPM and DSPM, what factors set them apart, and which one is the best choice for your organization’s needs.
Read more

Underestimating shadow data challenges
Organizations consistently underestimate how much sensitive data exists outside governed repositories. Research indicates that a meaningful percentage of publicly accessible cloud storage contains sensitive data, often due to misconfiguration rather than intentional public sharing. This includes database backups in old snapshots, production data copied to development environments, and intermediate files from data pipelines.
Test whether a DSPM tool can discover data you did not know existed. If a POC only finds data in explicitly configured locations, it will miss shadow data representing your greatest unmanaged risk.
Overlooking identity and access complexity
Knowing where sensitive data exists is necessary but insufficient. The critical question is who can access it and through what paths.
Cloud identity is complex. Role chaining, resource policies, trust relationships, and inherited permissions create access paths not obvious from examining individual policies. A DSPM tool listing "IAM users with access" without calculating effective permissions provides incomplete visibility into actual exposure.
DSPM for AI: Best practices and implementation guide
Data security posture management (DSPM) for AI extends standard data security posture management into AI-specific data flows, including training datasets, vector databases, embedding stores, inference pipelines, and AI agents.
Read more

How DSPM fits within broader cloud security
Modern DSPM works best when integrated with cloud security posture management, workload protection, and identity security rather than operating as an isolated capability that requires manual correlation with other tools.
The CNAPP integration advantage
Cloud-native application protection platforms (CNAPPs) unify multiple security capabilities including posture management, vulnerability assessment, identity analysis, and data security within a shared context model.
When DSPM shares context with vulnerability scanning, you can see whether the host containing sensitive data is exploitable. When integrated with identity analysis, you understand exactly which principals can reach data and how they obtained access. This unified approach eliminates the manual correlation required when DSPM operates in isolation.
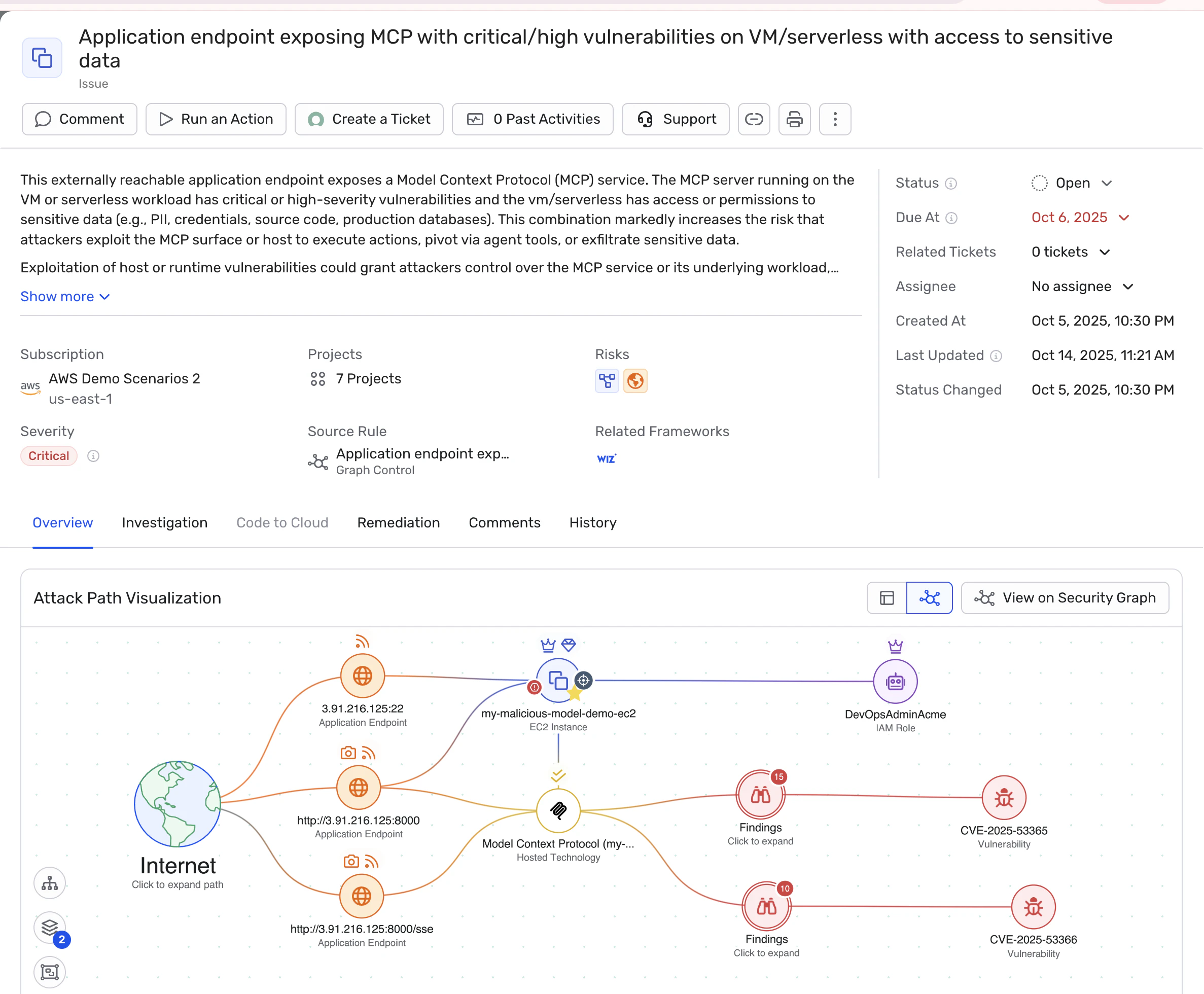
Security teams see complete attack paths to sensitive data rather than disconnected findings requiring investigation across multiple tools. A finding that combines "sensitive customer data" with "publicly accessible storage" and "overprivileged service account" tells a complete risk story that isolated tools cannot.
Data security in development pipelines
Sensitive data exposure often begins before production deployment. Credentials get committed to repositories, test data containing real customer information gets included in sample datasets, and configuration files embed secrets that persist through version control history forever.
DSPM capabilities extending into CI/CD pipelines and code scanning detect these issues before deployment reaches production. This shift-left approach prevents data exposure rather than detecting it after sensitive information has already been accessible for days or weeks.
Detection and response for data threats
DSPM traditionally focuses on posture: understanding where sensitive data exists and whether it is properly protected. Detection and response capabilities extend this to identify when data access patterns change in suspicious ways.
Unusual access to sensitive data stores, large data downloads, or access from unexpected identities can indicate compromise or insider threats. When DSPM is integrated with cloud detection and response (CDR), security teams can correlate suspicious access signals (such as unusual download volumes or access from unexpected identities) with data sensitivity context. This combination helps spot potential exfiltration earlier rather than discovering it late in incident response. DSPM provides the "what data is at risk" context; CDR provides the "what anomalous activity occurred" detection.
Wiz's approach to DSPM
Wiz delivers DSPM as part of an integrated cloud security platform connecting data discovery to the context required for meaningful prioritization. Rather than treating data security as isolated from infrastructure risk, Wiz correlates sensitive data findings with exposure, identity permissions, vulnerabilities, and misconfigurations to show which data risks could actually lead to a breach.
The approach emphasizes validated exposure over exhaustive pattern matching. Finding every file that matches a sensitive data pattern, without context on whether that data is actually exposed, creates noise that overwhelms security teams. Wiz prioritizes findings where sensitive data intersects with real exposure: public access, overprivileged identities, or vulnerable infrastructure.
Agentless discovery: Scans cloud storage, databases, and workloads without deployment overhead, finding shadow data in orphaned snapshots and unmanaged locations
Graph-based context: Maps relationships between data stores, identities, network configurations, and vulnerabilities to calculate attack paths to sensitive data
Identity and access analysis: Shows effective permissions for human and machine identities, distinguishing between direct access and inherited entitlements
The 5R remediation framework: Provides structured workflows to Reduce, Restrict, Relabel, Relocate, and Reconfigure data assets based on risk
Compliance mapping: Automatically aligns data findings to regulatory frameworks including PCI DSS, GDPR, HIPAA, and DORA
This integrated approach helps security teams move from managing thousands of data findings to remediating exposures representing genuine business risk.
Get a demo to see how Wiz connects sensitive data to exposure and access context so teams can prioritize what's actually at risk, not chase every pattern match.
Get a 1:1 demo of your data risks
See how Wiz DSPM automatically discovers sensitive data, maps where it lives, and shows exactly how it could be accessed or exposed — all in minutes.
