




Motivation
In a rush to adopt and experiment with AI, developers and other technology practitioners are willing to cut corners. This is evident from multiple recent security incidents, such as:
Platform resource abuses (attackers hijack cloud infrastructure to power their own LLM applications)
Vendors offering unsafe 3rd-party model execution (Probllama)
Model escape vulnerabilities in hosting services (Replicate, HuggingFace and SAP-AI vulnerabilities)
Yet another side-effect of these hasty practices is the leakage of AI-related secrets in public code repositories. Secrets in public code repositories are nothing new. What’s surprising is the fact that after years of research, numerous security incidents, millions of dollars in bug bounty hunters' pockets, and general awareness of the risk, it is still painfully easy to find valid secrets in public repositories.
TL;DR
In this blog we present the results of a simple, month-long side quest scanning for active secrets in public code repositories. After analyzing the resulting dataset, we were surprised to learn that AI-related secret instances constitute a disproportional majority of the findings (4 out of top 5 secrets found were AI-related). This prompted further investigation distilling three distinct use cases of AI secret leakages:
Python notebook .ipynb files as a secrets goldmine.
Secrets in mcp.json, .env and AI agent config files. Vibe coders are not familiar with secrets management best practices, and neither are their AI coding assistants.
New secret types belonging to emerging AI vendors are pervasive and the secrets scanning industry doesn't seem to be keeping up.
We were able to find valid secrets belonging to over 30 companies and startups, among them multiple Fortune 100 companies. Hopefully this blog will serve as a wake-up call for the AI and data science communities to urgently improve their development practices.
Background and Approach
Secrets in public repositories are an established attack vector. Uber (2016), Scotiabank (2019), Mercedes-Benz (2024), and the most recent xAI secret leak incident are just a few of the notable instances. In fact, stolen / leaked secrets are a major attack vector in many widely known supply-chain attacks (i.e. codecov incident). GitHub, being the most popular code hosting platform (our State of Code Security Report puts the share of repositories hosted on GitHub at 81%), naturally gets the most interest from malicious actors and security researchers alike.
Wiz Code includes a secrets scanner, offering customers protection. Wiz Research supports the product through ongoing investigations of public repositories and emergent patterns in secrets leakage. Unlike the State of Code Security Report, this time we focused on public environments, casting a wide net. Unlike some secrets research, we are specifically interested in validated secrets. This automatically filters out the false positives and testing patterns and as such yields higher-quality signals.
In short, we scanned thousands of repositories and found hundreds of validated secrets, many of those are still active. Our focus in this blog is on the high-level trends causing these exposures. While we won’t share the full methodology of choosing the scanning targets, suffice to say focusing on development activity showed significant improvements over the naive focus on repository popularity used in most research on secrets.
Overall Trends
In terms of secret occurrence, we found wide differences among the secret types:
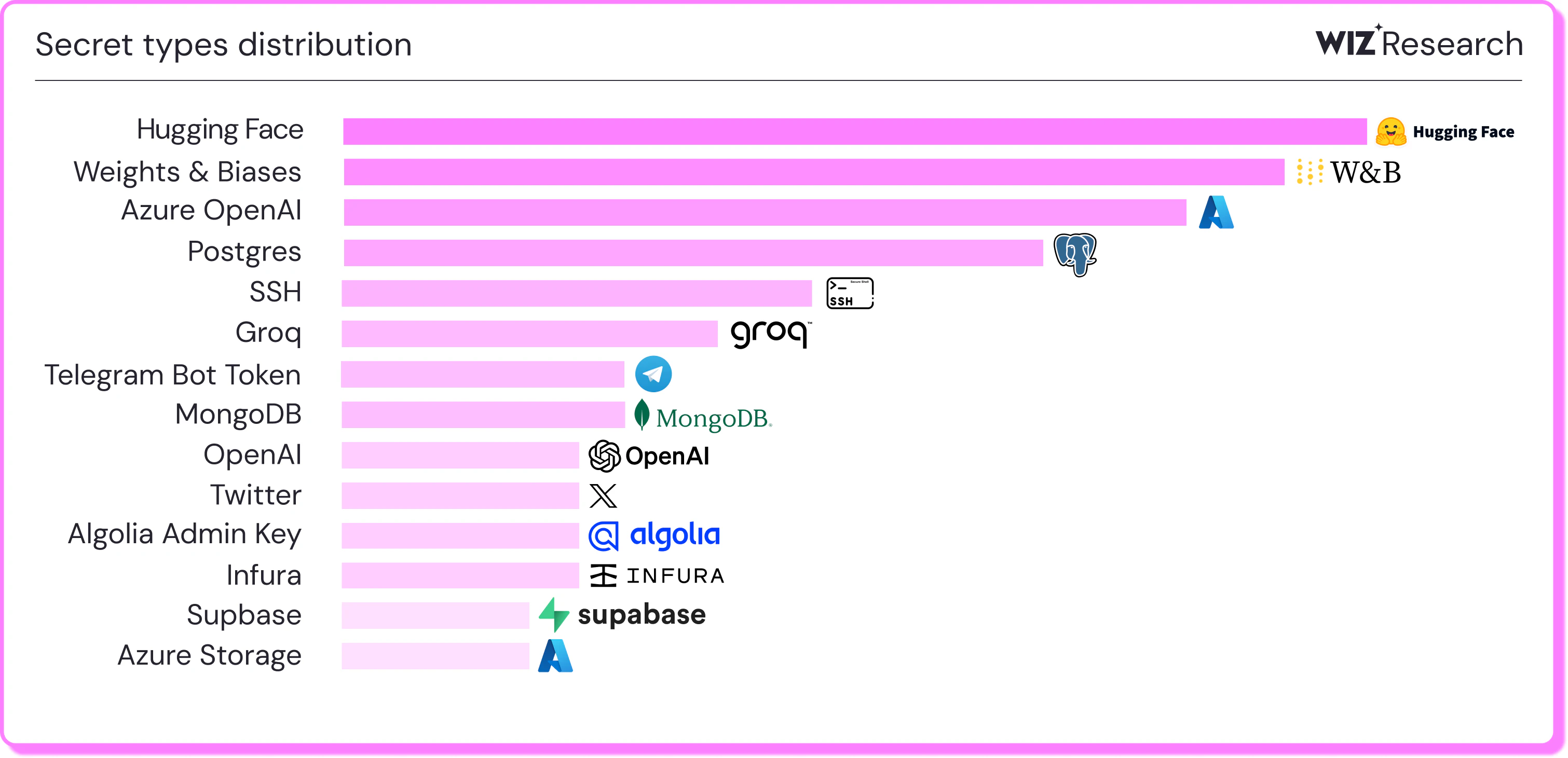
Three of the top five, and half of the top ten most common validated secrets in some way tied to AI. This result is notable because we did not purposefully target AI-related repositories. Yet, AI secrets constitute such a large proportion of identified exposed secrets. This discovery motivated us to dive deeper into research on AI-related secrets leakage.
Additionally, we wanted to understand the secret locality parameters to answer the following question: What file types include the most secrets? (and thus, deserve special attention by scanners and security policies). Turns out, one file type stands out in particular – notebook ipynb files:
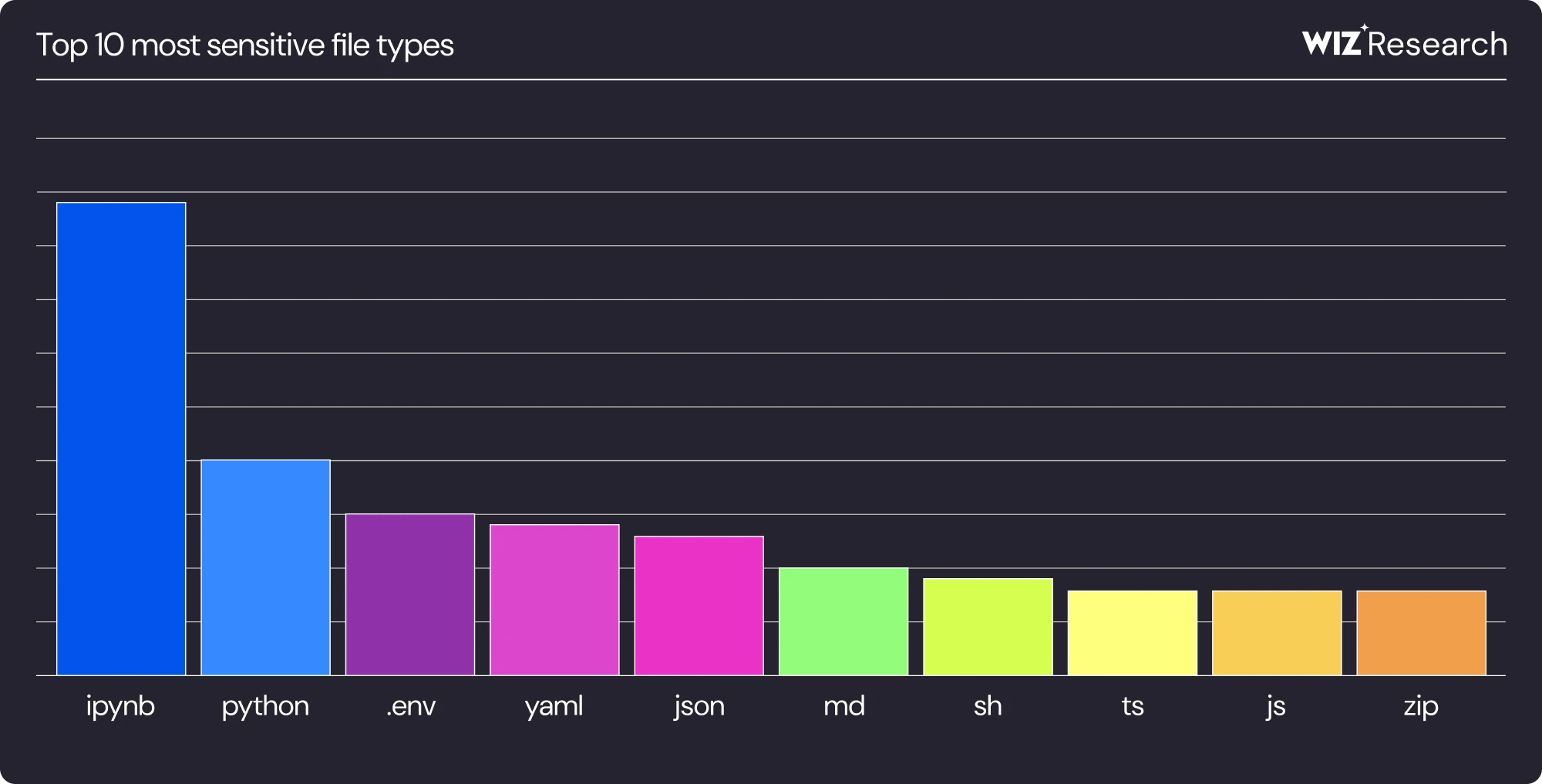
Secrets in notebooks is not a new finding. There were couple good publications on that since 2020 (for example here), yet this topic did not get wide exposure. It’s unfortunate, because supremacy of notebooks as a source of leaked secrets comparing to other file types is remarkable.
Another interesting question would be the correlation between the file types and the secret types. What kind of secret would you expect to see in this file? Such a determination can also be helpful to adjust the secret scanners and scanning policies. The relationships are intriguing:
| File | 1st most common secret | 2nd most common secret | 3rd most common secret |
|---|---|---|---|
| ipynb | HuggingFace | AzureOpenAI | WeightsAndBiases |
| python | HuggingFace | ||
| .env | HuggingFace | ||
| yaml | WeightsAndBiases | ||
| json | AzureOpenAI | ||
| md | Postgres | ||
| sh | WeightsAndBiases | ||
| ts | AlgoliaAdminKey | ||
| js | AlgoliaAdminKey |
Only for the 6-ranked md files the most common leaking secret is conventional Postgres credential.
Patterns in Secrets Leakage
With AI secrets being responsible for such an overwhelming majority of the findings, naturally we wanted to better understand the use cases that lead to secrets leaking.
Python notebooks
As mentioned earlier, ipynb files are by far the most leak-prone file type. This is because they pack a unique combination of code, code output, and descriptive elements. According to JupyterLab docs, a notebook is a “shareable document that combines computer code, plain language descriptions, data, rich visualizations like 3D models, charts, graphs and figures, and interactive controls“. As a result, there is a natural confusion as to how to treat these files – as a logs, as a code, or as a text. This is exacerbated by the fact that .gitignore files are not expressive enough to pick different use cases – one can either allow checking-in ipynb files or not, regardless of whether the file contains execution output or not.
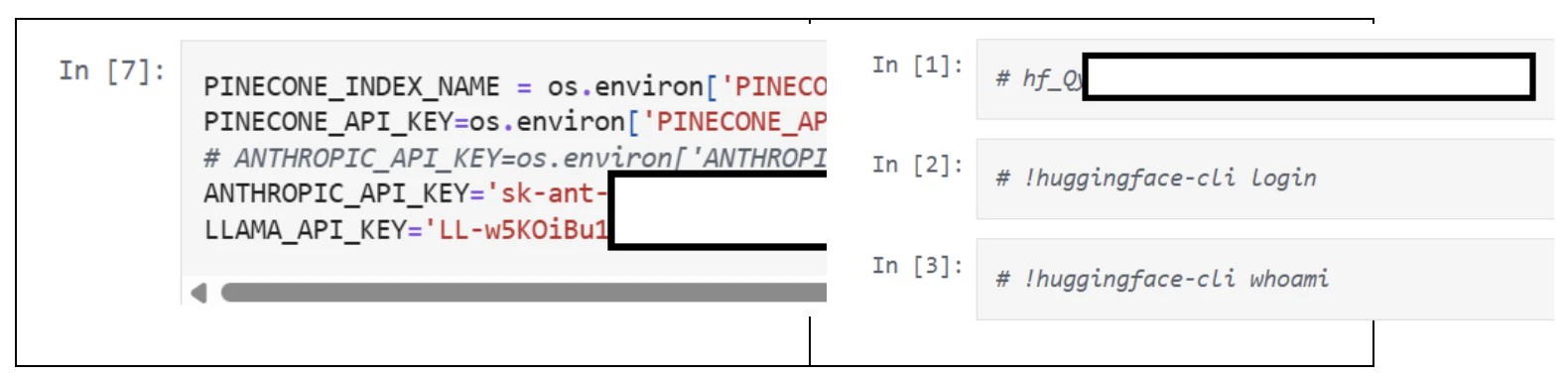
There are several distinct leak patterns that we can learn from. The most obvious is straight-up secret usage in a source code; this can be an embedded secret in the Python snippet of as a comment:
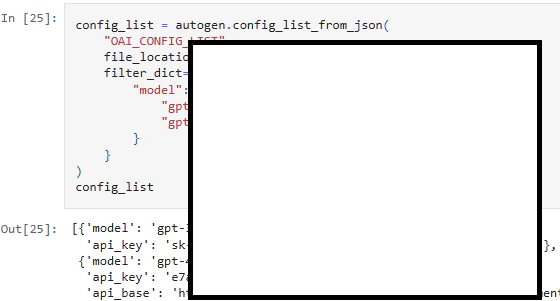
Another common usage pattern is dumping secrets in the execution output. Obviously, print() function will do the job, however, due to the interactive nature of notebooks, simply typing the variable will print it. In the case below, even though the developer has used the proper way to load the API key from the environment (load_dotenv(); os.environ["AZURE_OPENAI_API_KEY"] = os.environ.get("API_KEY")), the successive action of printing the loaded config renders the code insecure:
In addition, there is a more subtle way to unintentionally disclose secrets – via the usage of debug and diagnostics functions. In the following examples functions show() and list() output, among other things, API keys:

Finally, given the large number of failed outputs in notebooks, it is also common to observe sensitive details pertaining the local development setup, filesystem layout and networking as in these error messages:
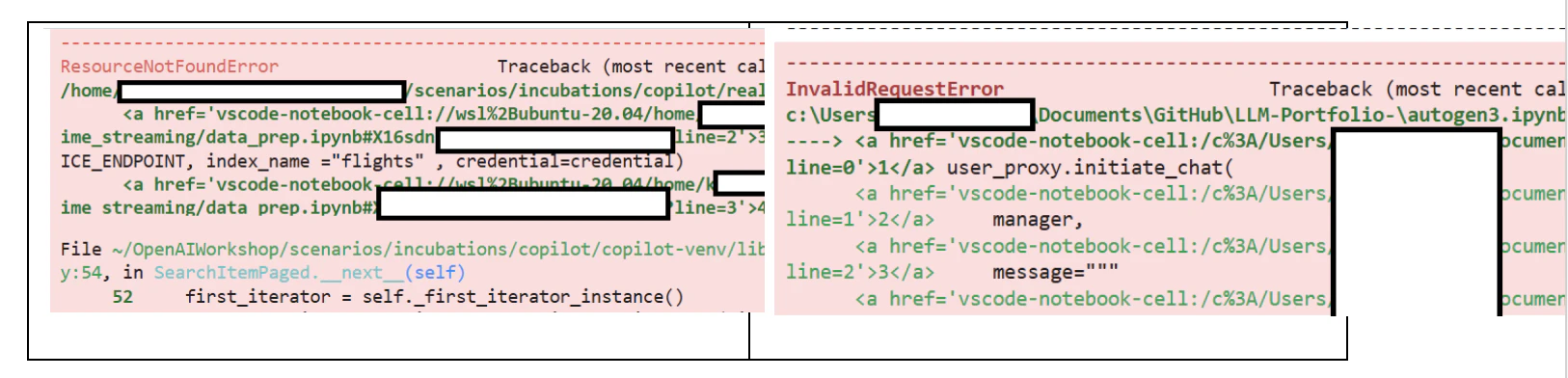
Beyond just secrets, code execution results in Python notebooks should be generally treated as sensitive. Their content, if correlated to a developer’s organization, can provide reconnaissance details for malicious actors.
Vibe-coding secrets into mcp.json
AI-assisted code generation is known to favor hardcoding secrets. This forms a toxic combination with the emergence of Model Context Protocol servers. MCP is a rapidly developing technology, with thousands of servers launched in the months after release.
Unfortunately, many MCP servers favor configuration through hardcoded credentials within the mcp.json configuration file. Take, for example, the instructions for an unofficial Perplexity MCP server.
Taskmaster AI is another example of a broadly popular server (over 11k stars) that makes this unsafe recommendation – impacting customer secrets for AI providers like OpenAI and Anthropic:
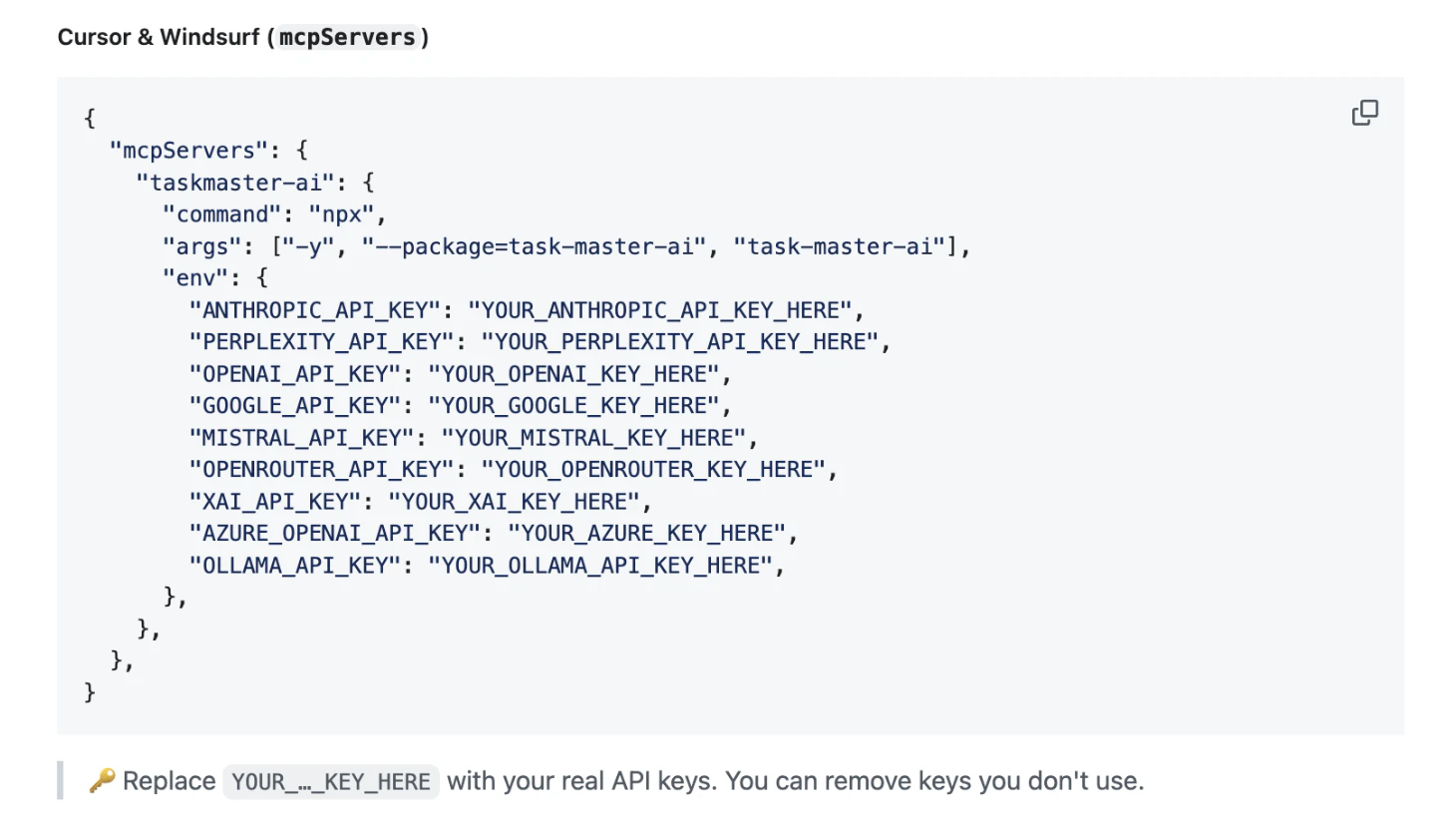
Unfortunately, this pattern is pervasive, impacting even the official Github MCP server. Once these secrets are hardcoded into mcp.json, it’s easy to see how they end up leaked publicly.
Gaps in current tooling
The ease in which you can still find secrets with a simple GitHub search is a cause for concern. AI is accelerating the process of writing code, and increased leakage of secrets appears to be a byproduct.
GitHub’s secrets scanning was transformational – the auto-remediation for supported platforms has meaningfully cut down on major incidents. But the scanning relies on the relevant platforms integrating with Github’s scanner, leading to limited coverage. Additionally, most integrations do not auto-revoke secrets, to avoid disrupting customer operation. The tradeoff is that we see numerous secrets that should have been detected and alerted by Github’s scanner that don’t end up remediated, or at least not promptly.
In looking at popular secrets scanning tools, we observe that despite supporting hundreds of types of secrets, they’re unable to keep pace with the rate of innovation. Pattern based matching will always lag new secrets and isn’t suitable for all kinds of secrets.
This is why Wiz Research takes a diverse approach to secrets detection, such as our recent session at BSidesSF on Enhancing Secret Detection in Cybersecurity with Small LMs.
Take China’s AI Tigers: immensely popular AI platforms, but overlooked by Western centric platforms and tools. GitHub has a huge user base shared with these platforms. The result? Dramatic volumes of unaddressed credential leakage for Chinese AI platforms, relative to Western platforms where leaks are automatically detected and reported.
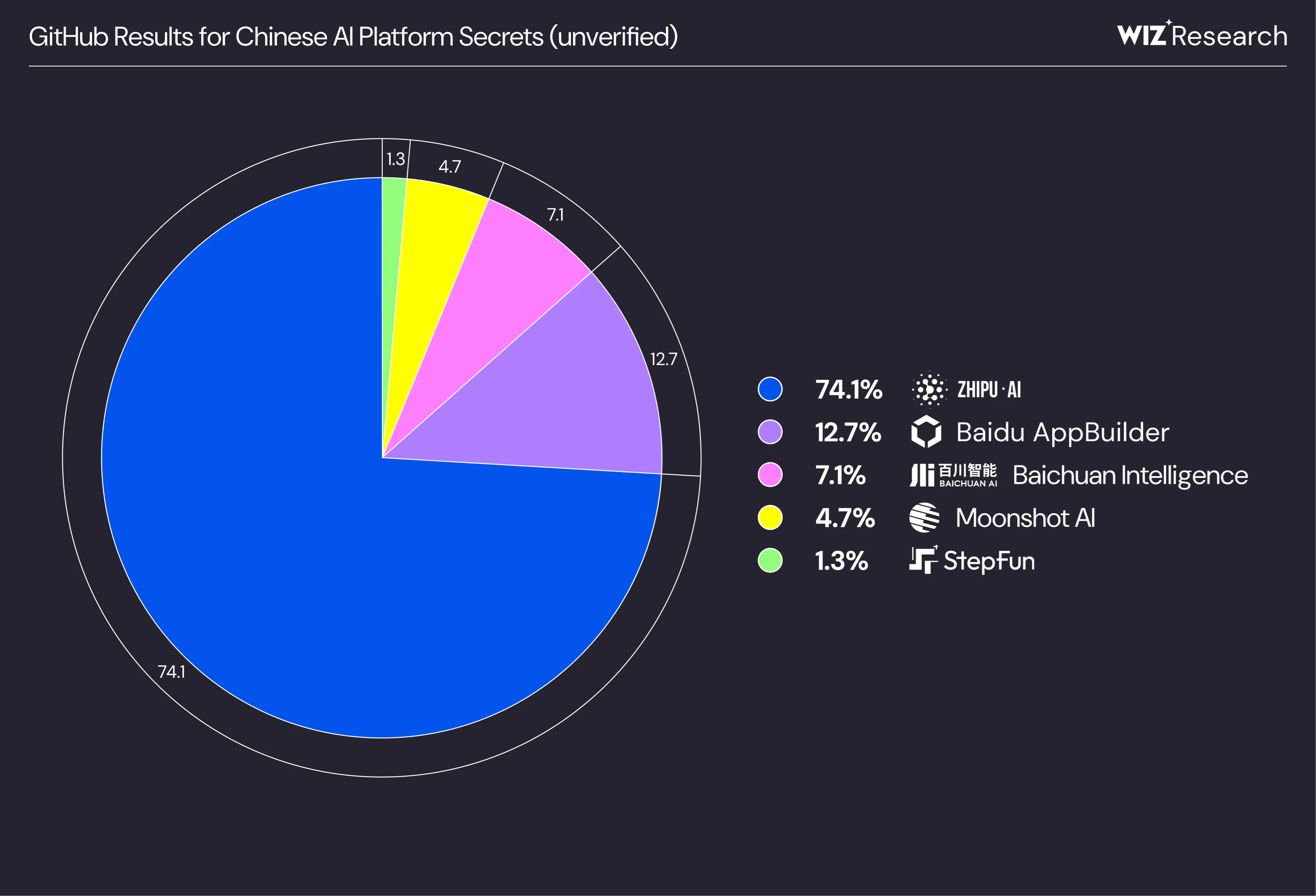
However, even more common AI services are often missed by secrets scanners.
We have compiled a list of AI secrets that are missed by one or more popular secret scanning tools, informed by our search of validated secrets in code:
| Most common | Less common | AI Tigers |
|---|---|---|
| Perplexity, WeightsAndBiases, Groq, NVIDIA API | Tavily, Langchain, NVIDIA-NGC, Cohere, Pinecone, Clarifai, Gemini, AI21 Labs, IBM Watsonx AI, Cerebras, FriendliAI, FireworksAI, TogetherAI | Zhipu AI, Moonshot AI, Baichuan Intelligence, 01.AI, StepFun, MiniMax |
As part of the WizCode and WizCloud, our secret scanning module now detects the vast majority of the above secret types. In addition, the work is underway to add the rest under an AI-based classification.
Impact on Companies
About a third of the secrets we found belong to personal projects, while the rest is divided equally between companies, company employees, startups, open source, and research/university projects:
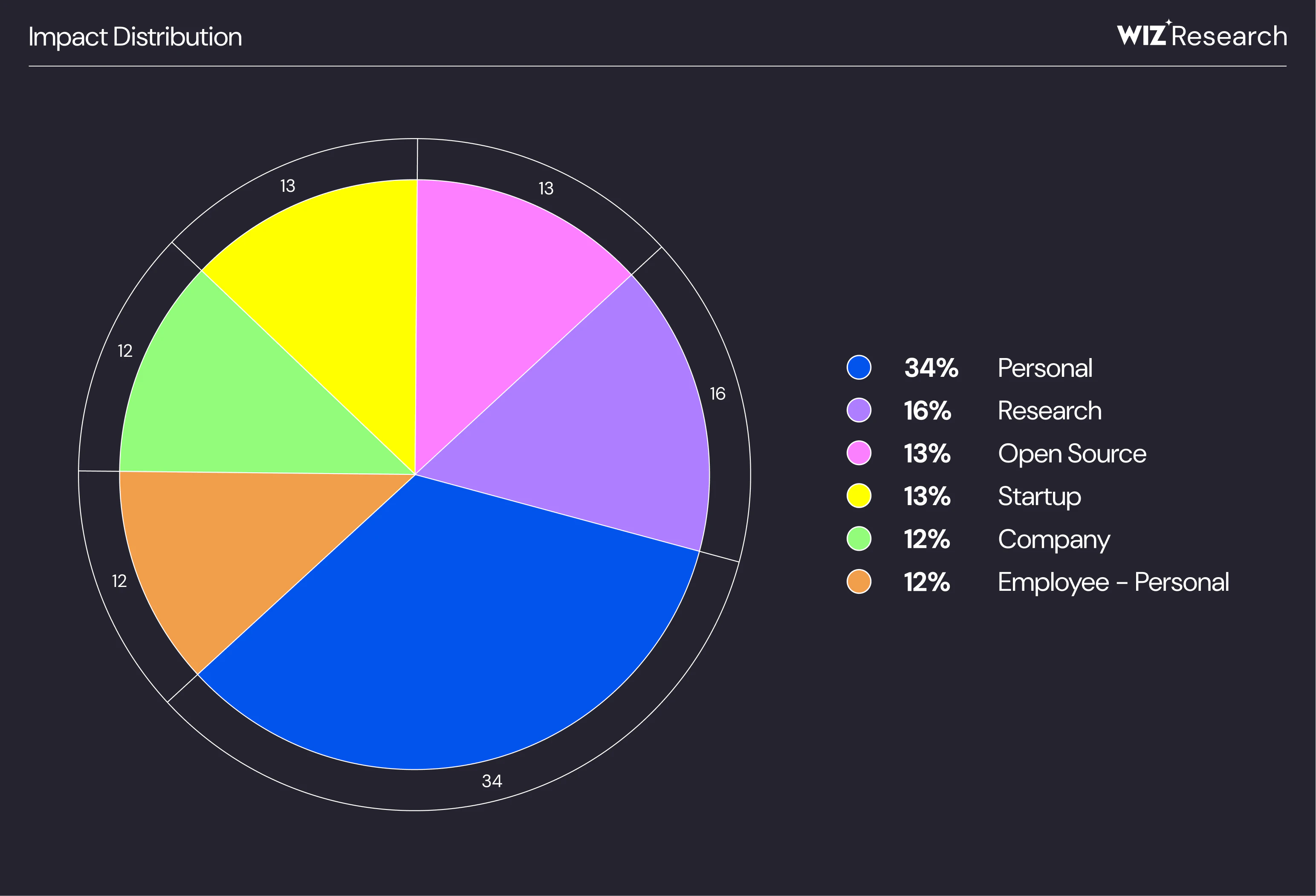
This means that about 40% of discovered secrets can have a real impact on companies. We were able to find valid secrets belonging to over 30 companies and startups, including multiple Fortune 100 companies. To take one example: one of the secrets reported to MSRC was assigned Critical severity and could have led to the disclosure of sensitive HR data.
Another particularly interesting finding: 56% of the detected secrets with company impact were found in personal repositories of company employees, rather than in the company organizations themselves. This highlights the dangers of adjacent discovery, but that's a story for another blog.
Since we did not perform a systematic study, we cannot state the overall percentage of vulnerable companies. What we can say is that we found exposed secrets in around 20% of the organizations we checked. This suggests that these initial findings are just the tip of the iceberg.
Takeaways and Disclosures
To conclude, our research highlights several important messages, all of them are underscored by the crazy pace of AI adoption and evolution: AI providers multiply and with them new secret types and new secret usage cases. On the flip side, the progress in AI-for-code brings an “AI-automated” way to setup the dev environment. This setup is often leak-prone.
The good news is the mitigation in most part remained the same – secret scanning pre-commit hooks, periodic scans, CI/CD pipeline integration and git history scanning. Assuming, of course, that the existing secret scanners will catch up with the gaps. The integration of new secret types and usage patterns into the existing protection and detection flows must be accompanied by a scrupulous inspection of the use cases. For example, how does your org use ipynb files? Is there a policy preventing check-ins of the notebooks with execution output? Does your secret scanner scan non-renderable / large ipynb files?
As an aftermath of this project, our research team has disclosed the most prominent findings to customers, partners and 3rd-party companies. The most difficult part turned out to be reporting what seems like a production-level secret leaks to small startups without a dedicated security team. Overwhelming majority of initial contact attempts to founders or GitHub org members via LinkedIn / X / email were left unanswered, therefore, we do not disclose the findings in detail. Hopefully, we will be able to talk more on that and expand on the hunting methodology in one of the upcoming conferences.










