




TL; DR
We fine-tuned a small language model (Llama 3.2 1B) for detecting secrets in code, achieving 86% precision and 82% recall—significantly outperforming traditional regex-based methods. Our approach addresses the limitations of both regex patterns (limited context understanding) and large language models (high computational costs and privacy concerns) by creating a lean, efficient model that can run on standard CPU hardware. This blog post details our journey from data preparation to model training and deployment, demonstrating how Small Language Models can solve specific cybersecurity challenges without the overhead of massive LLMs.
This research is now one of Wiz’s core Secret Security efforts, adding fast, accurate secret detection as part of our solution.
Introduction: The Secret Detection Challenge
In cybersecurity, stolen credentials represent one of the most common attack vectors, appearing in almost one-third (31%) of all breaches. Attackers frequently target secrets from various sources, including public repositories, misconfigured cloud resources, and compromised workstations.
Traditional secret detection methods rely heavily on regex patterns, which suffer from several critical limitations: limited context understanding that prevents differentiating between actual secrets and similar-looking strings; high false positive rates that lead to alert fatigue; manual rule maintenance requiring constant updates for new secret formats; and narrow coverage that, according to our research, captures only about 60% of potential leaks with high false positive rates.

While large language models (LLMs) have demonstrated impressive capabilities for understanding code context and detecting non-trivial secrets, deploying them at scale introduces significant challenges related to computational requirements, costs, and data privacy concerns.
This led us to ask: Could we fine-tune a smaller language model to achieve the best of both worlds—the contextual understanding of LLMs with the efficiency of traditional methods?
The Limitations of Large Language Models at Scale
While large language models like GPT-4o and Claude Sonnet 4 have demonstrated impressive capabilities in understanding code context and detecting secrets, they present significant challenges when deployed at enterprise scale, particularly in a cybersecurity context like ours at Wiz.
Scale: The Million-File Problem
Wiz scans millions of code files daily across our customers' environments. Using a large language model for this task would require enormous computational resources, complex infrastructure for parallel processing, and would introduce significant time delays that could impact detection of critical vulnerabilities. Consider the math: if scanning a single file takes just 2-3 seconds with an API-based LLM, processing 5 million files would take approximately 174 days on a single thread. Even if we ignore API requests rate limits and with massive parallelization, this remains a diverging challenge
Cost: The Financial Equation
The financial implications of using commercial LLM APIs at scale are staggering. API costs for large models typically range from $0.005 to $0.10 per file, depending on size. At the scale of millions of files, this could translate to hundreds of thousands of dollars monthly— making comprehensive scanning financially unfeasible.
Privacy: The Non-Negotiable Requirement
Perhaps most critically, enterprise code contains highly sensitive information. Customers are explicitly unwilling to share proprietary code with external LLM services, and data protection regulations in various industries and regions may prohibit sending code to third-party processors.
The Paradigm Shift: Small, Specialized Models
Our research represents a significant paradigm shift away from the "bigger is better" mentality that has dominated AI discussions. By fine-tuning a small, specialized model for a specific security task, we've demonstrated that small language models can produce similar results like foundation models for specific tasks when properly trained. On-premises deployment becomes feasible to address privacy concerns, cost-effectiveness improves dramatically to enable true enterprise-scale scanning, and latency is reduced to acceptable levels for security-critical applications.
This approach changes how we think about applying AI to security challenges—instead of relying on LLMs, we can develop focused, efficient solutions tailored to specific security needs.
Data Preparation: Teaching Our Model What Secrets Look Like
Multi-Agent Approach to Data Labeling
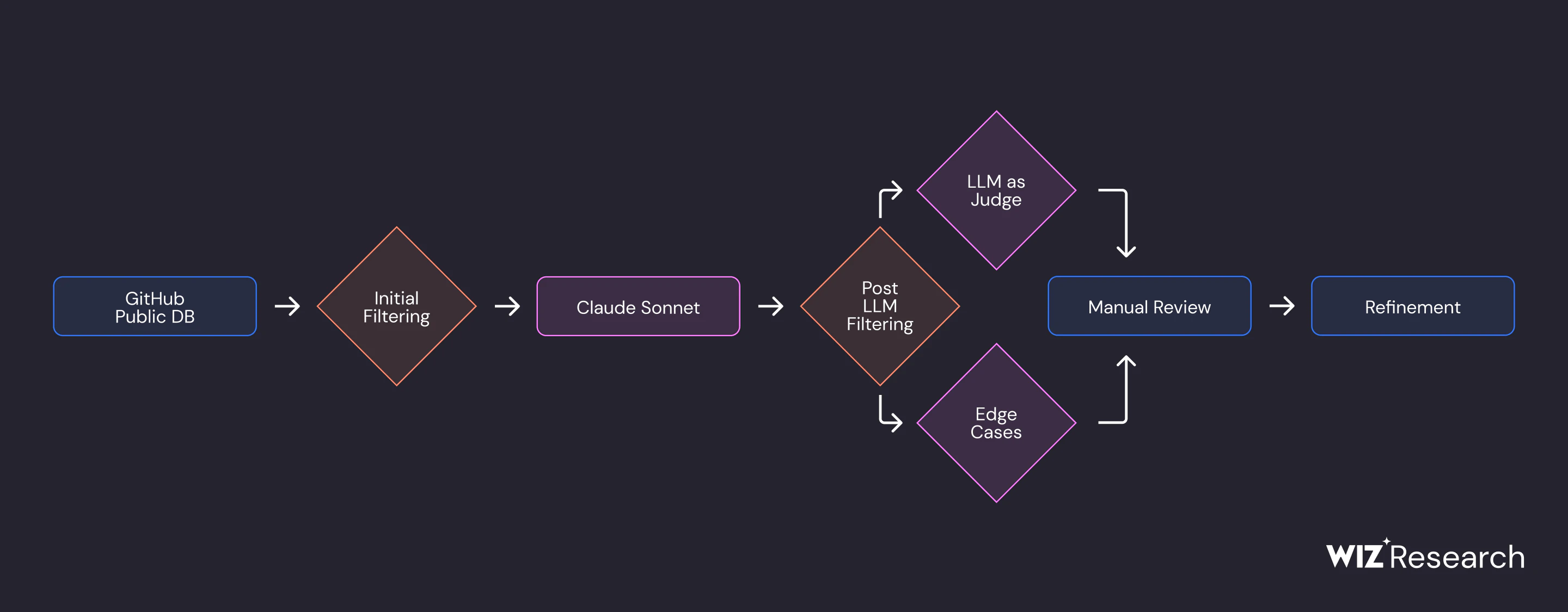
To create a high-quality training dataset, we implemented a specialized multi-agent workflow that leveraged larger LLMs to help label data. We used models like Sonnet 3.7 to identify potential secrets in code files from GitHub's vast public repositories. These models generated structured metadata for each potential secret, including secret value, variable name, category, and confidence score. We specifically focused on non-obvious secrets hidden in comments, string literals, and logging statements—areas where regex often fails—and implemented iterative prompt refinement with expert validation to ensure high-quality labels.
We used Sonnet as the base tagging model, and other LLMs as a validator (LLM as judge) for the results.
Ensuring Dataset Balance and Quality
Building a balanced and representative dataset was crucial for model performance. We combined pattern matching (regex) with entropy analysis to identify potential secrets. Our dataset ensured representation across different programming languages and file formats (XML, C, Java, Python, etc.), This process yielded a dataset containing thousands of code files.
Strategic Data Filtration
To maximize training effectiveness, we implemented a comprehensive data filtration pipeline. Beginning with our initial dataset from GitHub, we processed the data through Sonnet 3.7. Afterwards we applied clustering techniques using MinHash/LSH algorithms to group similar code files. Within these clusters, files were further organized according to the secrets our LLM detected, and we selected one representative file from each group to ensure diversity without redundancy. Our final filtration stage applied quality-focused criteria, systematically eliminating files with short secrets (lacking sufficient context), files where referenced secrets were missing from the actual code, files containing too many secrets (which could confuse the model), files with common placeholder secrets, and duplicate files with identical paths and secret patterns. This methodical approach significantly enhanced our training data quality while maintaining the diversity needed for robust model performance across various secret types and programming contexts.
Model Selection and Fine-Tuning: Small but Mighty
Setting Clear Targets
We established concrete goals for our fine-tuned model: achieve inference in approximately 10 seconds on a single threaded ARM CPU machine; output multiple data points in a single inference (secret value, category, and confidence score); and outperform traditional regex-based detection methods.
Choosing the Right Base Model
After evaluating several small language models, we selected LLAMA-3.2-1B as our base model for fine-tuning, based on its manageable parameter count of just 1 billion parameters, its solid baseline understanding of code structures despite its size, and its architecture that made it particularly suitable for adaptation using LoRA. We also tested alternatives including Phi 1.5 and QWEN CODE 2.5 0.5B but found that LLAMA-3.2-1B provided the best balance of speed and accuracy and security for our use case.
Training Techniques
To optimize our model for both performance and efficiency, we employed several advanced fine-tuning techniques:
Low-Rank Adaptation (LoRA): Adding "Smart Filters" to Our Model
LoRA represents one of the most significant advancements in efficient model fine-tuning and was essential to our approach. The traditional challenge with fully fine-tuning a neural network model typically requires updating all weights across all layers—billions of parameters that consume enormous computational resources and memory. The LoRA solution, rather than modifying the original pre-trained weights, adds small "adapter" matrices to key transformation layers within the model. These adapters are low-rank (typically ranks between 4-64), making them extremely parameter-efficient.
From a mathematical perspective, if a model has a weight matrix W, LoRA decomposes the update into: W + ΔW = W + BA, where B and A are low-rank matrices. Instead of storing and computing gradients for the entire W matrix, we only need to train the much smaller B and A matrices.
As a visual metaphor, imagine the pre-trained model as a complex lens system that processes information. Traditional fine-tuning would require reshaping all lenses. LoRA instead adds small "filter layers" at strategic points that subtly redirect the focus toward our specific task, without changing the main optical system.

Quantization: Compressing Without Compromising
Quantization was another crucial technique that allowed us to run our model efficiently on CPU hardware. Traditional LLMs use 32-bit floating-point (FP32) precision for weights and activations, consuming substantial memory. Through quantization, we reduced this precision while preserving accuracy.
We employed a quantization strategy using post-training quantization to reduce model weights to 8-bit integers (INT8), while maintaining 16-bit precision for critical attention layers where we observed accuracy degradation.
Technically, we utilized the llama-cpp framework, applied careful calibration using a representative dataset to determine optimal quantization parameters, and implemented weight clipping to reduce outliers that cause quantization errors.
The results were impressive: a 75% smaller model footprint compared to full FP32 precision, 2.3x faster processing on CPU hardware, and less than 1% drop in precision and recall metrics. We created multiple quantized versions of our model with different precision trade-offs, allowing deployment flexibility based on hardware constraints and accuracy requirements.
This combination of LoRA fine-tuning and strategic quantization allowed us to create a model that maintained the contextual understanding capabilities needed for secret detection while being lean enough to run efficiently at scale on standard CPU hardware.

Evaluation and Results: Exceeding Expectations
Validation Methodology
We developed a comprehensive validation process to accurately measure our model's performance. We evaluated based on precision, recall, and runtime performance, considering both file-level matches (does this file contain secrets?) and secret-level matches (what specific secrets are identified?). Since language models can sometimes produce "almost correct" outputs,
like:
| Actual Variable Name | Model Output Variable Name |
|---|---|
| secterKey | secret_key |
| SessionToken | token |
| myauthtoken | my_auth_token |
We defined confidence thresholds for variable names and secret values and implemented a match scoring system that accounts for minor variations in output.
Performance Results
Our fine-tuned model achieved impressive results:
| Model | Recall | Precision | Runtime |
|---|---|---|---|
| LLAMA-3.2-1B | 82% | 85.7% | ~27 tokens/sec |
| Qwen Code 2.5 0.5B | 71% | 87.5% | ~143 tokens/sec |
These results demonstrate that our fine-tuned model significantly outperforms traditional regex-based approaches (which typically achieve ~60% recall with high false positive rates) while remaining efficient enough to run on standard hardware.
Optimizing Inference
To meet our runtime target of approximately 10 seconds per file on CPU hardware, we implemented several optimizations. We created a "prediction funnel" that first filters files by length, name, and basic regex patterns, ensuring only files that pass these initial filters are processed by the model. For large files, we extract only relevant sections, discarding long documentation blocks and examples, which dramatically reduces the token count for processing. We also implemented efficient model loading and caching to reduce startup latency, allowing for faster batch processing of files.
Deployment and Integration: From Research to Production
Our model was designed from the ground up with production deployment in mind. It runs efficiently on standard CPU hardware, eliminating the need for specialized GPU infrastructure and allowing for deployment across a wide range of environments. We implemented a phased deployment approach, initially running the model on a small subset of files to validate performance in real-world environments before scaling up.
Rather than replacing existing detection methods, our model works alongside them. During the research process, our LLM labeling efforts actually helped identify additional regex patterns that could be added to traditional detectors. We also built mechanisms to capture false positives and false negatives in production, feeding this data back into our training pipeline to continuously improve the model.
Future Directions: This is Just the Beginning
Our success with fine-tuning a small language model for secret detection opens several exciting avenues to enhance our platform.
While our SLM-based detection engine is currently in private preview, its primary goal is to augment the powerful secrets scanning capabilities Wiz is already known for.
Today, Wiz provides comprehensive coverage in code by scanning the full Git history for hundreds of secret types and running automated validity checks to reduce noise. Furthermore, we connect these findings with cloud and runtime insights to contextualize each exposed secret's permissions and potential blast radius if exploited.
We see our new AI classification capabilities as the next step in this evolution, allowing us to cast an even wider net to catch generic secrets while ensuring high recall and low false-positive rates.
We alsoaim to expand coverage beyond code to detect secrets in configuration files, documentation, and other data types. Further model optimization could involve reducing model size while maintaining performance and exploring advanced quantization techniques to improve inference speed.
We also see opportunities for enhanced contextual understanding, training the model to better assess the severity and exploitability of discovered secrets and identify potential misuse scenarios.
Key Takeaways
Our research demonstrates several important lessons for applying AI to cybersecurity challenges. Small language models, when properly fine-tuned, can solve specific security challenges without the overhead of massive LLMs, balancing performance, efficiency, and privacy concerns.
Data tagging and generation using LLMs can help you solve challenges that were overlooked before due to lack of time or resources. Manual tagging that would have taken security teams months to do can be done in a fraction of the time, allowing agile development and research, and solving complex challenges. This work now feeds straight into Wiz’s Data Security product, where AI-powered detection- a key element of the platform’s DSPM solution, delivers faster, more accurate protection for sensitive data.
BSidesSF 2025 Presentation














